Writing testable serverless apps and preventing vendor lock-in using hexagonal architecture

Slobodan Stojanović
Posted on June 18, 2020

What's the scariest thing about serverless? The answer to that question depends on the person you ask and timing.
In the early days of serverless, people would mention long-running tasks. However, with AWS Lambda 15 minute timeout, AWS Fargate, and many other announcements, that problem is already solved. People who work with medical apps, and other industries that are dealing with sensitive data, would probably mention compliance, but serverless providers are adding support for many different compliances regularly to their platforms. What about binaries and large dependencies? That was an annoying problem, but then AWS introduced Lambda Layers. Cold starts? If you still have cold start issues, you either use VPC, something peculiar, or we are using serverless in a completely different way. If you are running your Lambda functions in VPC, AWS has some good news for you.
Maybe Node.js? Just kidding, I love Node.js!
However, it doesn't matter if you are talking to the back end developer, system architect, or a business person, there's one thing that always pops up, and it's often followed by a few seconds of silence.

What about big bad vendor lock-in?
What's vendor lock-in?
If a few seconds of scary silence doesn't scare you away, you can ask yourself what's that mysterious vendor lock-in, anyway?
If you check Wikipedia, you'll see the following definition:
In economics, vendor lock-in, makes a customer dependent on a vendor for products and services, unable to use another vendor without substantial switching costs.
As every definition, this sentence is either too boring and makes you fall asleep, or it opens a lot of other questions. One of the follow-up questions can be "how does vendor lock-in in cloud computing works?"
Let's say that you need a server. I don't know why, you are weird, but that's not important at the moment.
So you need a server. You can either buy it or rent it. You can probably try to build it from scratch, but to do that you must first invent the universe, and that's far beyond the scope of this article.

Let's say that you are reasonable enough, and you decide to rent a server. You find the guy with many servers, let's call him Jeff, and you rent a server from him. Because you are weird, you call your server "the cloud," but in reality, it's just a regular server somewhere in Jeff's basement.

Jeff is smart, and he knows how you and some other weird people use his servers. As most of you have some database, he introduces a cloud database service. Same with storage, computing, and even with machine learning services.
As Jeff has enough clients, he decides to charge you for real usage of his services. That means that you pay only for the services that you use. Should I even mention that you love his offering?

But, what if Jeff is a villain?
Maybe he is just waiting until you fully embrace his cheap and beautiful cloud services, and implement them deep into the business logic of your web application. Then; a few seconds of scary silence; he drastically increases the price of his services.

If that happens, I guess you'll not be in love with Jeff's cloud anymore. Your wallet will not be happy, either.
Luckily, it's not all over! There's another guy with many servers, let's call him Bill. He also has some cloud database, compute, storage, and other similar services. Bill is also pricing his services per usage, and it seems that your app could work fine in Bill's basement and that you would be happy again.

New hope arises. Can you move your app to Bill's basement, pardon, cloud?
Well, you can. However, that's not easy, as Bill's database service doesn't work the same way Jeff's database service work. Same with other managed services. To migrate your app to Bill's servers, you'll need to adjust it.
Do you remember the moment you decided that testing is tedious and that you can live without automated tests? Also, all those moments when you cut corners in the application architecture, to be able to finish some non-crucial feature a few hours faster?
All of your bad decisions now make the migration even more expensive than keeping your app in Jeff's basement.
Well, that's the moment you realize what the true meaning of cloud vendor lock-in is.
How to fight vendor lock-in?
So, how do you fight vendor lock-in? In most of the cases, you fight it the same way you fight monsters under your bed.
The first step is to face your fears, and give them the right name. In the cloud, the right name for vendor lock-in is switching cost. As Mark Schwartz, Enterprise Strategist at AWS, says in his excellent article "Switching Costs and Lock-In":
My train of thought went like this: the term “lock-in” is misleading. We are really talking about switching costs.
Is it? I'll answer with another quote from Mark's article:
Switching costs have existed throughout the history of IT. As soon as you commit yourself to a platform or a vendor you will have switching costs if you later decide to change. If you choose Java and then migrate to Node.js, you will have a cost.
My experience is similar. In our product, Vacation Tracker, we switched many things. We migrated most of our app from MongoDB to DynamoDB, migrated some Express.js parts of the app to serverless on AWS, entirely changed some services. Do we have issues with vendor lock-in? Sometimes we do! However, it's our choice, and it's probably not a vendor lock-in you would expect.
Even though our app is almost 100% serverless on AWS, we don't have any issues with cloud vendor lock-in. However, our app integrates deeply with Slack, and sometimes, even the smallest change on Slack's platform can affect our product.
So, how can we fight cloud vendor lock-in? First, we can fight it by asking ourselves the right question — how do we keep our switching costs reasonably low?
To keep our switching costs low, we need to start with better planning. How low should our switching costs be? That depends on how likely we need to switch to some other platform. So far, AWS lowered the prices for their cloud services more than 15 times, and they never raised the price of any of the products. I don't think the risk that they'll increase the prices significantly is high. Even if they do, and our infrastructure cost rise 100 times, we'll pay less than $100 per month. Should we even care about that?
If the risk is high enough, so it needs to be planned for, how much would switching cost? The cost depends on your architecture, but in our case, spending a few weeks on migration would not have a significant impact on our business, so I think our switching cost is reasonably low.
Once you finish initial planning, it's time to consider some good architecture practices and deployment procedures that allow you to evolve your application, and to make necessary migrations in the future less painful and expensive. Deployment procedures are beyond the scope of this article, and we'll probably discuss them in some of the future ones (you can always subscribe to our newsletter on Vacation Tracker website), but even the deployment procedures often depend on a decent app architecture and how testable is your app is.
Designing testable serverless apps using hexagonal architecture
I mentioned testing, but why do you need to test your application if it's serverless and it scales automagically? Your infrastructure might be fully managed, but your business logic and code are not. You can, and will have bugs in your serverless application. The difference is that your bugs will not crash your infrastructure, but they can scale automatically.
Most of the time serverless applications are not entirely isolated monoliths without integrations. Instead, they contain many services interacting with each other and with external dependencies. For example, our application is deeply integrated with Slack, and the central part of our integration looks similar to the following diagram. Slack sends webhook events to the API Gateway. Then we route them to different Lambda functions that handle different scenarios, for example, Slack slash command handler for slash commands, or message action handlers for responses to the button actions in Slack. Lambda functions process the event, push the event to the Amazon Simple Notification Service (SNS) topic, and reply to Slack. Then our business logic gets the message from the SNS topic and does something with it.
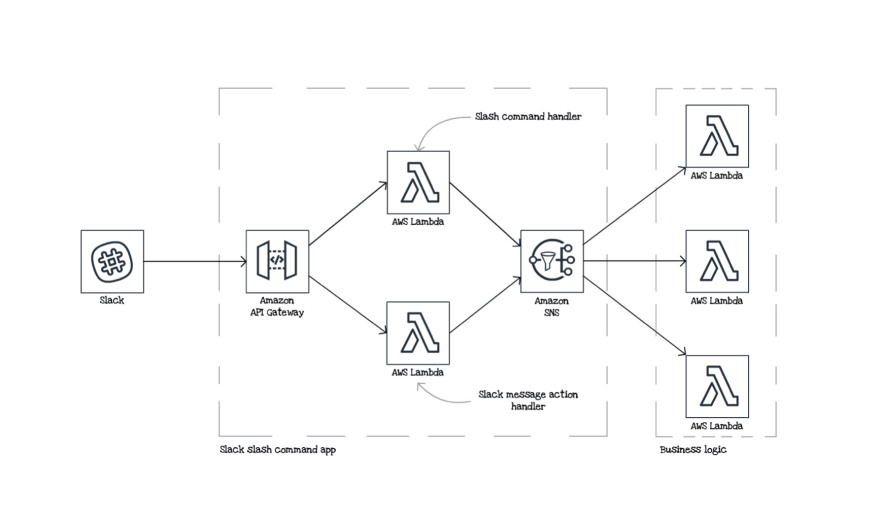
If just one of these pieces fails, our business logic will not be able to function correctly. Also, when you have many small services in your app, any integration can change any moment, either on the next deployment or when the external dependency change. Tests will not prevent these changes, but they'll at least ensure that your changes are not accidental.
But how do you know what should you test in a serverless app? That's a big topic, and you can read a bit more about it in my previous article about testing serverless applications.
The testing pyramid is a good start. Does it still apply? Yes, it does. Is it the same? Not really, because automated tests are cheaper than they were before. You can now create a new DynamoDB table in seconds, and then delete it after running your tests. Alternatively, you can leave it there, because you will pay only for the real usage (unless you store some vast amount of data during your tests). It's the same with other parts of your app. You can create an exact copy of your production app in minutes, and it will probably cost you less than a few cents to run a full end-to-end test suite.

However, faster and cheaper tests are not the only differences. Integration tests are cheaper, but also more critical because a common serverless app is split into many small pieces.
What makes a serverless app testable
Every application is testable, but some applications are written in a way that makes automated testing incredibly hard and expensive. That's precisely what you want to avoid in your application because lack of automated tests can make your switching process way more complicated.
That's where your app architecture jumps in and saves the day. You shouldn't reinvent the wheel; many excellent app architectures are around for years or decades. Which one is the right one for your serverless app?
Any architecture that will let you test your app easily and keep your switching costs low will be perfect. Because sooner or later you'll need to migrate pieces of your app. Not to another cloud vendor, but a new service, or some new or changed integration.
Like any other application, your serverless app has certain risks you'll need to consider. As my friend and co-author Aleksandar Simovic explained in our book Serverless Applications with Node.js, there are the following four risks that you should consider when architecting your app:
- Configuration risks; for example, is DynamoDB table correct and do you have access rights?
- Technical workflow risks; for example, are you parsing and using the incoming request properly?
- Business logic risks; or is your app logic working the way it should?
- Integration risks; for example, are you storing the data to your DynamodB table correctly?
You can test most of these risks with your end-to-end tests. But, imagine if testing a new car was done that way, and that you need to assemble the whole car to test if windshield wipers are working correctly.
Ports, adapters and architecture
If you are often traveling, you know the pain with power plugs. If you go from Europe to North America, you can't just plug your laptop in the power supply socket. They are incompatible.
However, buying a new cable whenever you travel to another country would be too expensive and pointless. Fortunately, you can buy a small adapter to make your power cable compatible with power sockets all around the world.

Your application should work the same way. Does your business logic care if it stores the data to MongoDB or DynamoDB? Not really. However, your database adapter should care about that.
This leads us to my favorite architecture for serverless apps: hexagonal architecture, alternatively called ports and adapters. As it's creator, Alistair Cockburn, explains, the hexagonal architecture allows an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases.
By definition, this architecture seems like a perfect fit for serverless, as it's almost impossible to simulate your entire eventual runtime locally during the development.
Let's say you have a service that receives some notification, parse it, save the data to the database, and then sends another notification to SNS topic. For us, this is a typical pattern. For example, when we save a vacation request to the database, we also send a message to the SNS topic that then triggers another service to send a request to the manager via Slack.
Instead of bundling everything together, the business logic of this service is simple, and it just coordinates other services. The core of the service exposes three ports:
- A port for an incoming event
- A port for saving data to the database
- A port for sending a notification
Then we have different adapters, for example, one for sending the notification to the Amazon SNS topic for production, and another that fits the same port for sending a local notification during testing.
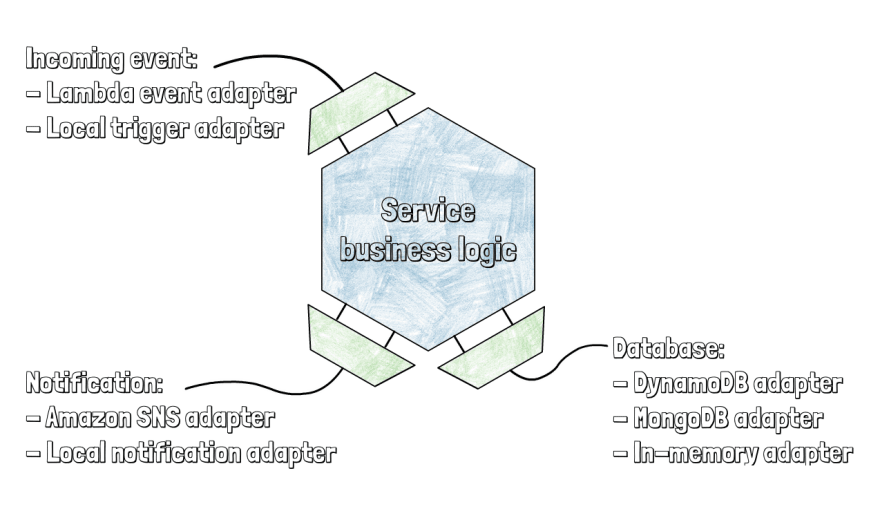
As explained in my other article about hexagonal architecture, our minimal code example is split into the following two files:
- The
lambda.jsfile wires the dependencies and has no tests. - The
main.jsfile holds the business logic.
Remember our Slack flow? Let's see this in practice for one of the functions, for example, Slack slash command handler.

The lambda.js file from this function takes the SNS notification repository as a dependency and invokes the main.js function with it, and the received event. We have unit and integration tests for the function from the main.js, but it's never tested against Amazon SNS. Why? Because we send messages to multiple SNS topics from many different services. If we test each of them against Amazon SNS, it will take much time, and most of our tests would be redundant, as we'll repeatedly check if our SNS repository and it's a dependency, AWS SDK, are working as they should.
Instead, we test our main.js function against a local notification adapter that talks fit the same notification port. However, in the SNS notification repository's integration tests, we test the integration with Amazon SNS to make sure it works as intended.

But, how do we write ports and adapters in our code? It's simple!
Our main.js function receives an instance of notification repository as a parameter. That instance can be any notification repository compatible to the notification port, not just Amazon SNS adapter.
Also, what is the notification port? It's just a .send method of that notification repository. Our main.js file will try to send a message by invoking the following function: notification.send(message). Anything that can fulfill this request is a compatible adapter.
Our SNS notification is a class that exposes send method that sends a message. That's the adapter.
The lambda.js file looks similar to the following code snippet:
// Dependencies
const {
parseApiEvent,
SnsRepository
} = require('../common')
const httpResponse = require('@vacationtracker/api-gateway-http-response')
// Business logic
const main = require('./main')
async function handler(event) {
// Parse API event
const { body, headers } = parseApiEvent(event)
// Create an instance of SNS notification repository
const notification = new SnsRepository(
process.env.topic
)
// Invoke the main function with all dependencies
await main(body, headers, notification)
// Return status an empty 204 response
return httpResponse()
}
The most important part of our lambda.js file is the following line:
await main(body, headers, notification)
With this approach, it's easy to write automated tests for our business logic. In unit tests, we invoke our main function with some static values for the body and headers and mock the notification adapter. Then we check if the mock is invoked with the correct data.

In integration tests, we invoke the main function with some a static body and headers, and the instance of local notification repository. Local notification repository can be a simple wrapper around native JavaScript events.

If you want to read more about testing serverless apps and see code examples, checkout our new course on Senzo Homeschool platform (first one starts on Monday, June 22, 2020):

What about Vendor lock-in?
Yes, what about it? Ah, yes, we were talking about vendor lock-in! So you can ask how does hexagonal architecture help fighting a vendor lock-in.
Choosing a wrong database seems like significant vendor lock-in, right? We migrated most of our app from MongoDB to DynamoDB easily.
Our app is integrated with databases the same way it is integrated with Amazon SNS: using the database repository. At some point, our app was using MongoDB repository, that had unit and integration tests.
Once we decided to migrate to DynamoDB, we created another adapter for DynamoDB and called it dynamodb-repository.js. This repository has the same interface as MongoDB one, for example, if you want to delete a vacation you need to invoke the following function: db.deleteVacation(params). MongoDB repository will delete the vacation in MongoDB, and DynamoDB repository will delete it in DynamoDB.
During the migration, we connected our services to two repositories at the same time and started switching integrations, one by one. When the migration was finished, we removed the MongoDB integration from the service.

Beyond testing
There are always some things that can't be tested. For example, you integrated with Google, and they changed their API without proper notice. We saw Slack changing their app behavior many times, and it wasn't even documented.
Some of these integration changes are hard to detect, for example, when Slack decide to show only 5 attachments in the mobile layout our calendar is screwed, but our app still works properly. However, most of these changes start causing many errors in your app.
You can't fight against unexpected changes of third-party dependencies, they'll happen, but you can and should monitor both front end and back end of your app, and react fast when the changes break parts of your app.
If your serverless app is on AWS, there is a variety of excellent services that helps you monitor it. You can use built-in tools such as Amazon CloudWatch and AWS X-Ray, or some of the third-party apps, such as IOpipe, Epsagon, Thundra, Lumigo, and many others.
Posted on June 18, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
June 18, 2020