Refactoring a distributed monolith to microservices

Rehan van der Merwe
Posted on August 5, 2020

This article documents the thought process and steps involved in refactoring a distributed monolith to microservices. We are going to remove API GW, use Amazon Event Bridge and implement BASE consistency in the system to truly decouple our microservices.
This blog is also available as a presentation. Reach out if you would like me to present it at an event.
I will use the codebase from the previous installment to the series that can be found here. The first part focuses on creating the codebase and implementing AWS native observability, monitoring and alerting services. As always you can find the code that we used in the respective GitHub repositories over here: https://github.com/rehanvdm/MicroService.
Original System
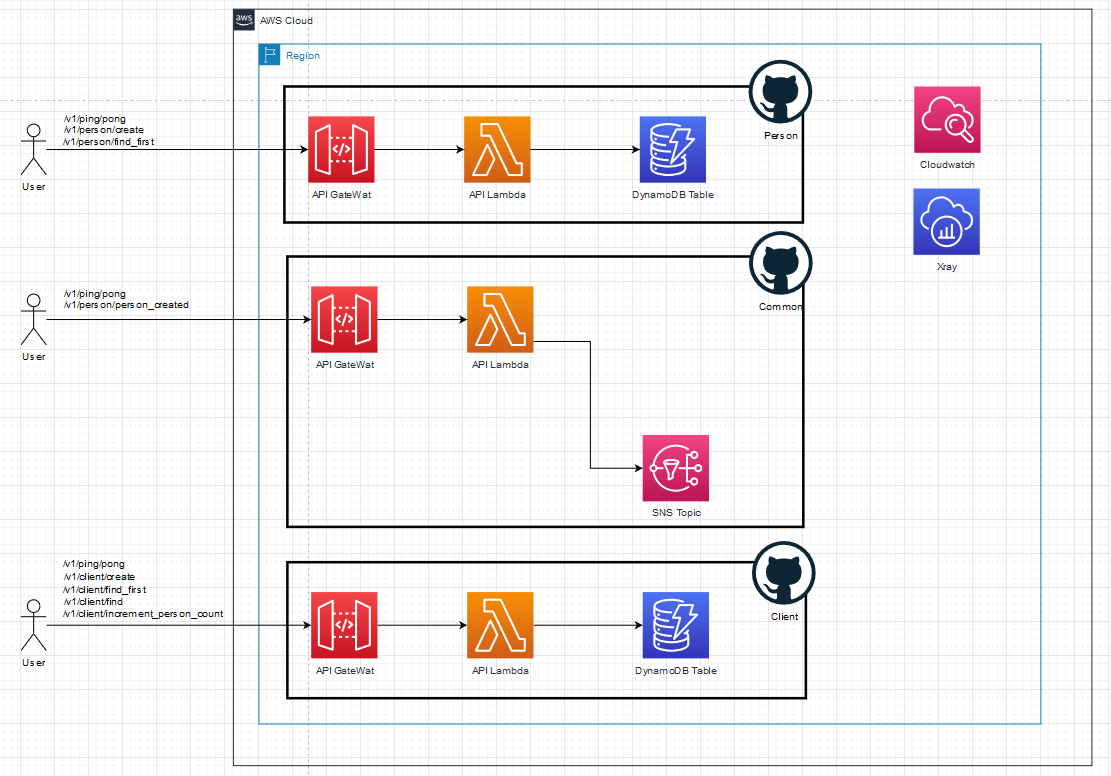
The original system is a distributed monolith that consists of three microservices.
Within each project you can find an OpenAPI (part2/src/lambda/api/api-definition.yaml) file that defines the API definition for each service. AWS CDK is used and they all follow the similar stock standard CDK project layout: Typescript for the CDK and ES6 JS for the application code. NPM commands have been written to do deployments and it also contains end-to-end tests using Mocha and Chai. In addition, each service contains a detailed README inside the /part2 path. Note that I only have a single Lambda for the API endpoint and do internal routing. Yes, I believe in a Lambalith for the API!😊 and also prefer JSON POST over REST (more about this later).
A problem arises as soon as these microservices start to call one another. We will focus on the creation of a new person to demonstrate how this tight coupling is working.
The client service stores clients and has basic create-client and find-client functionalities as well as an endpoint to increment the person count for a specific client. The person service also has basic create-person and find-person endpoints. When a person is created, it calls the common service which notifies me by email about the new person that was added using an SNS subscription. The common service first needs to do a lookup on the client service so that it can enrich the email. It also increments the counter on the client. Click on the image below to see the step-by-step path for creating a person:
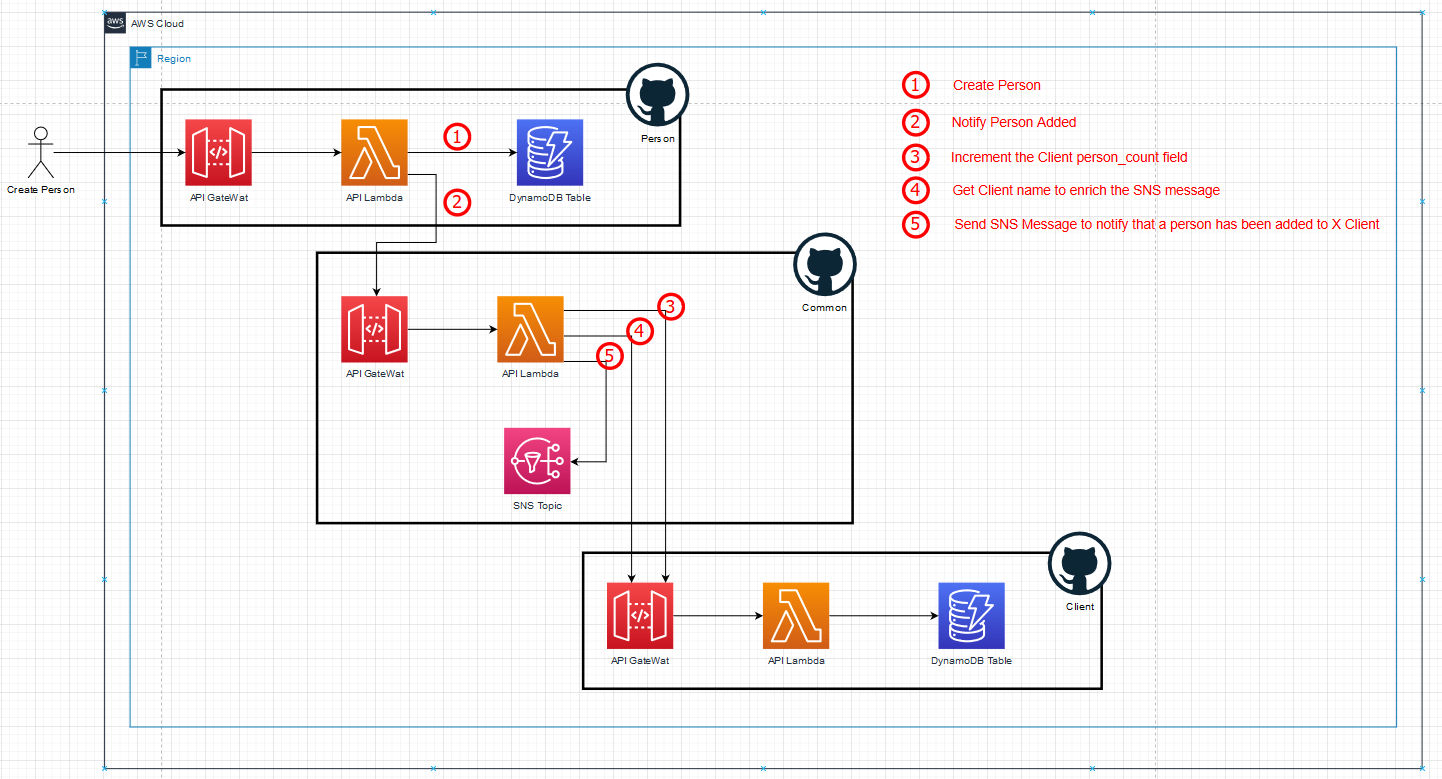
Original system – full create person flow (Click to enlarge)
The create-person call is highly dependent on the common service and does not even know that the common service is dependent on the client service. As a result, the person service is also dragged down if either the common or the client service is down. Not to mention that it now has to wait for the completion of every step in the synchronous chain. This wastes money and increases the probability of hitting the API Gateway timeout of 29 seconds.
Decoupling with Amazon Event Bridge
Amazon Event Bridge is a serverless event bus that makes it easy to work with event-driven architectures. It works on a basic publish and subscribe model. We use it to emit certain events like: person-created and client-created. Other services can then listen to only the events that they want and act on it. The new system is refactored to incorporate this and remove the direct HTTP API calls between services.
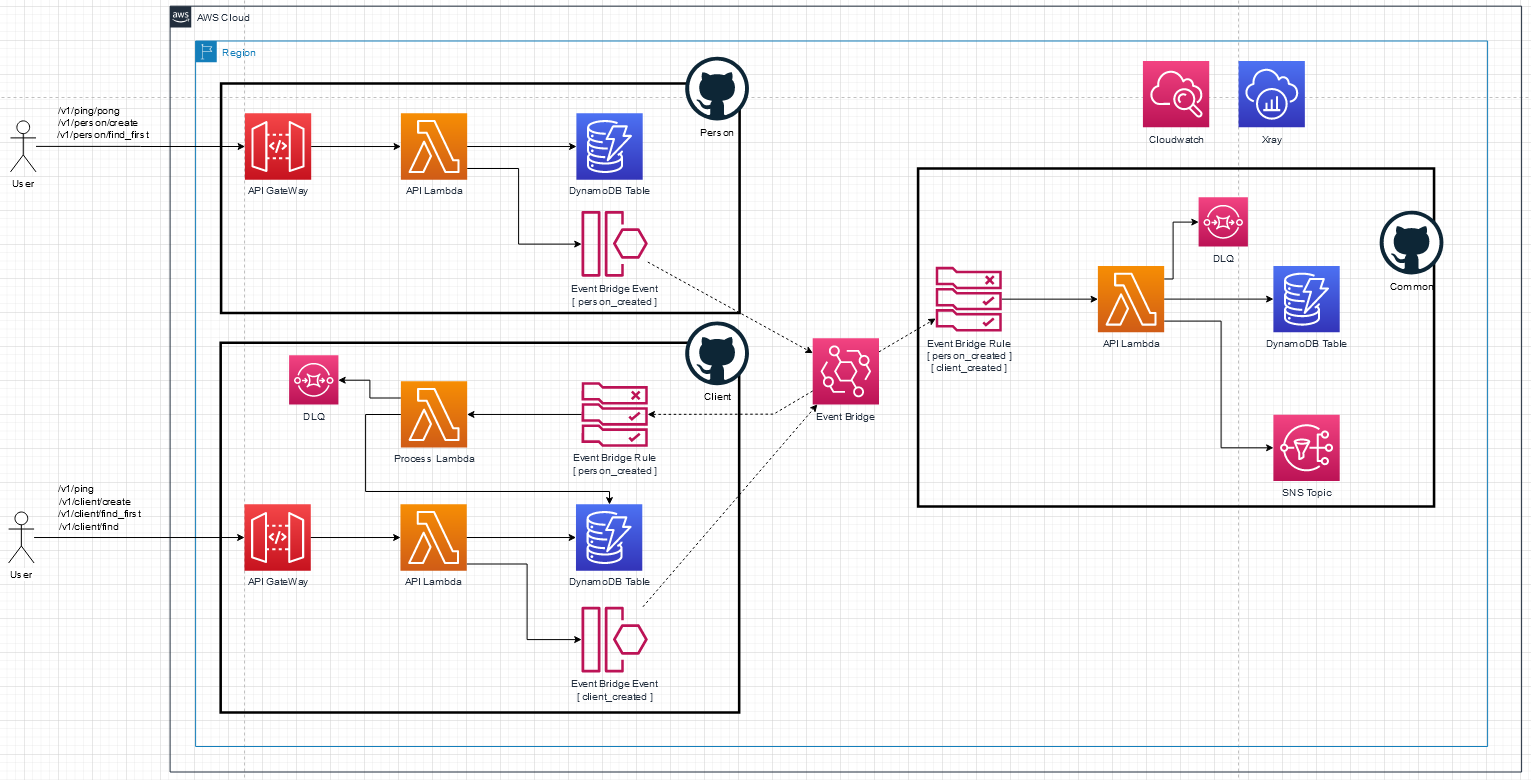
New system (Click to enlarge)
The client service has not changed much. It is stillfronted with API Gateway (GW). It now emits an event onto the bus whenever aclient is created. A new Lambda function is added that listens to the create-person events. This increments the person counter for that specific client.This feature was previously on the common service but has now moved to theclient service.
The person service is working exactly as before. Justlike the client service, it also emits an event onto the event bus,specifically the create-person event.
The common service no longer needs to be fronted byAPI GW. Instead it listens to both the create-client and _create-person_events. The common service stores the client data in its own DynamoDB table. Ituses this to look the client up within itself (locally), rather than calling anHTTP API to get the data for a specific client. The common service still sendsan email when a new person is added.
From an external integration point of view , all API endpoints stayed exactly the same. The diagrams below clearly illustrate that each service is only concerned with its own data and responsibilities. The event that is emitted onto the bus is also added for convenience.
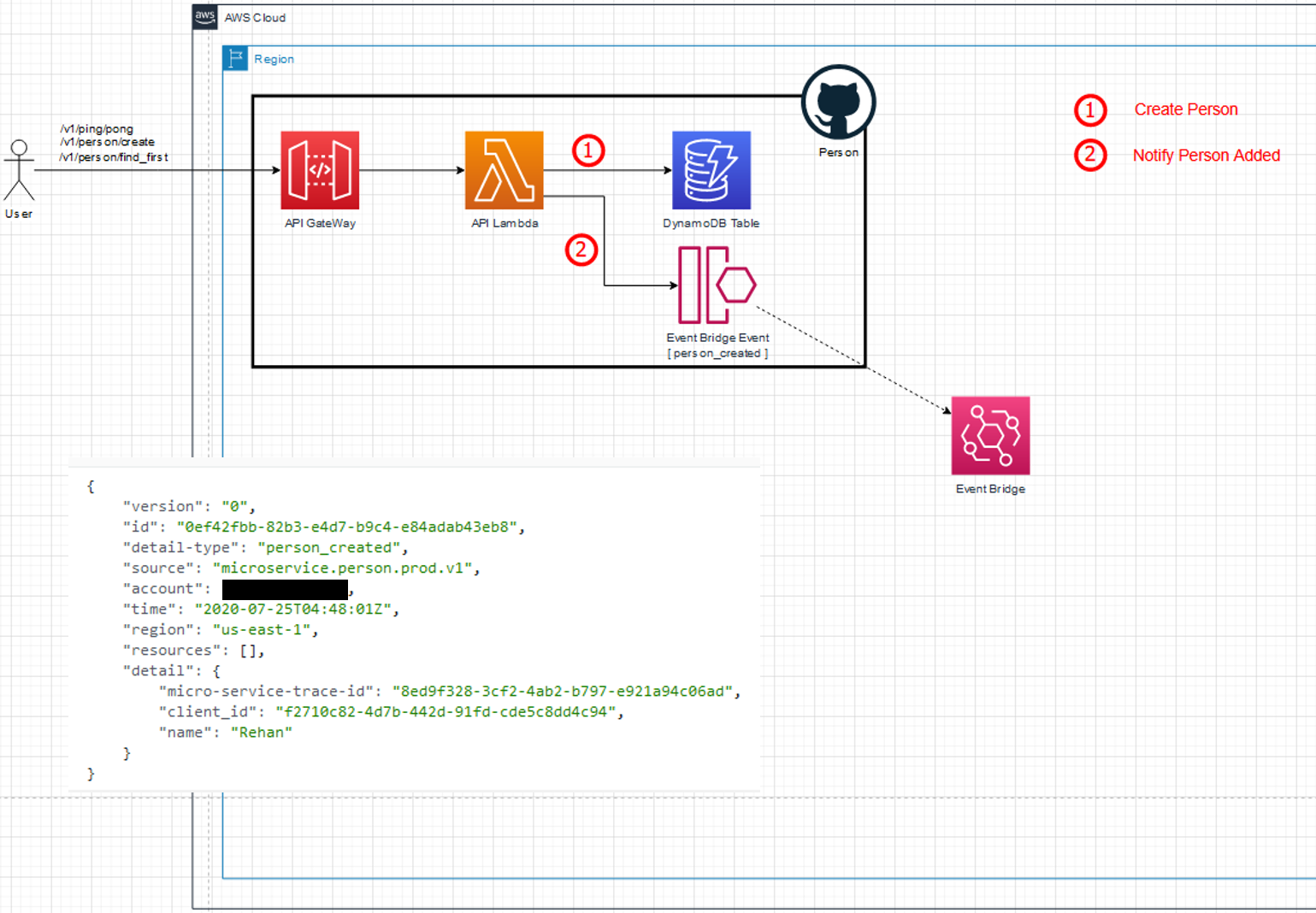
New system – partial create person flow (Click to enlarge)
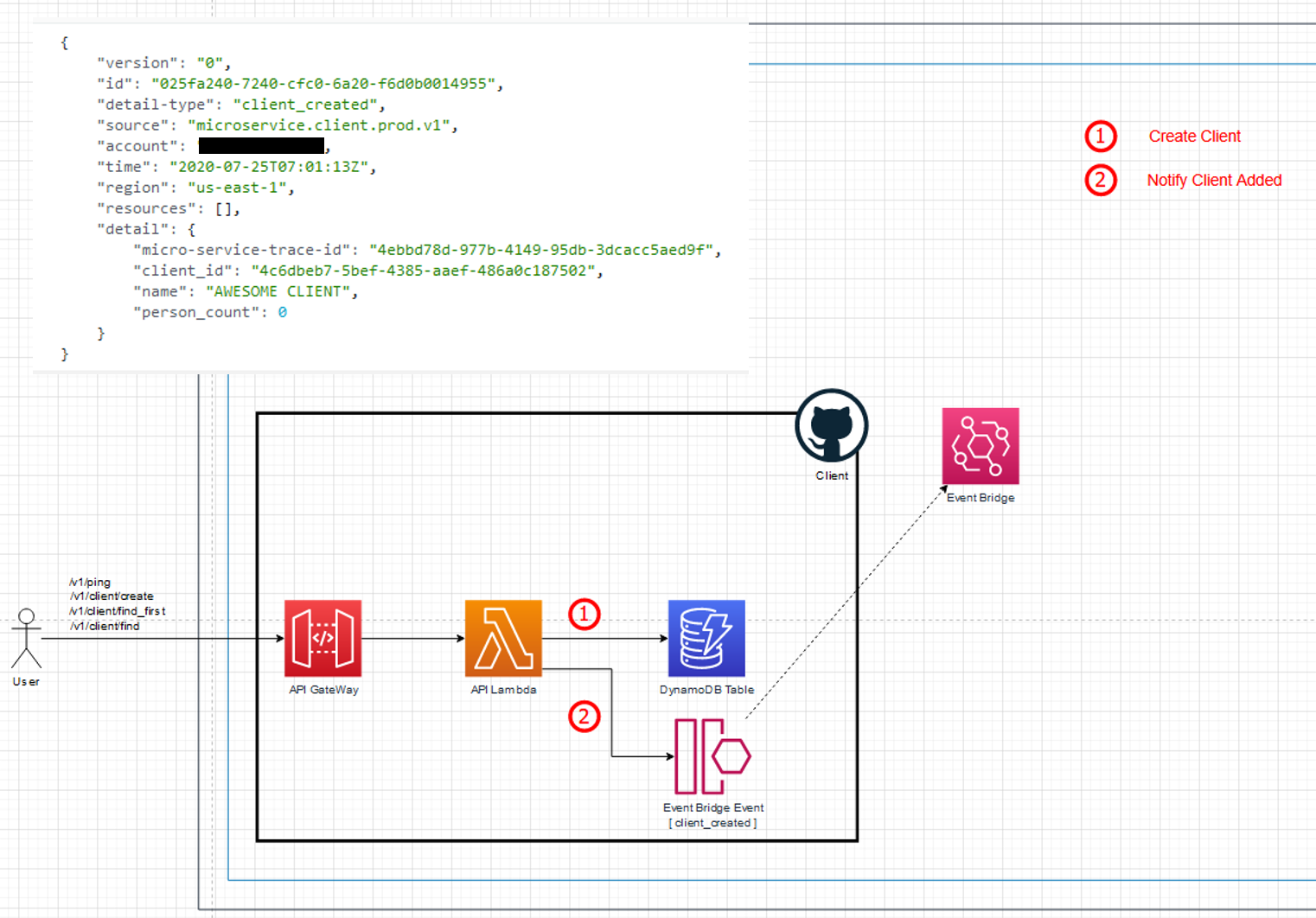
New system – partial client person flow (Click to enlarge)
Internally the common service has an Event Bridge Rule with the Lambda function as target. It listens to the create-client events and then stores only the client-id and client name fields within its own DynamoDB table. This removes the need for it to do an HTTP API call to the client service as it can now just do the lookup locally against its own data store.
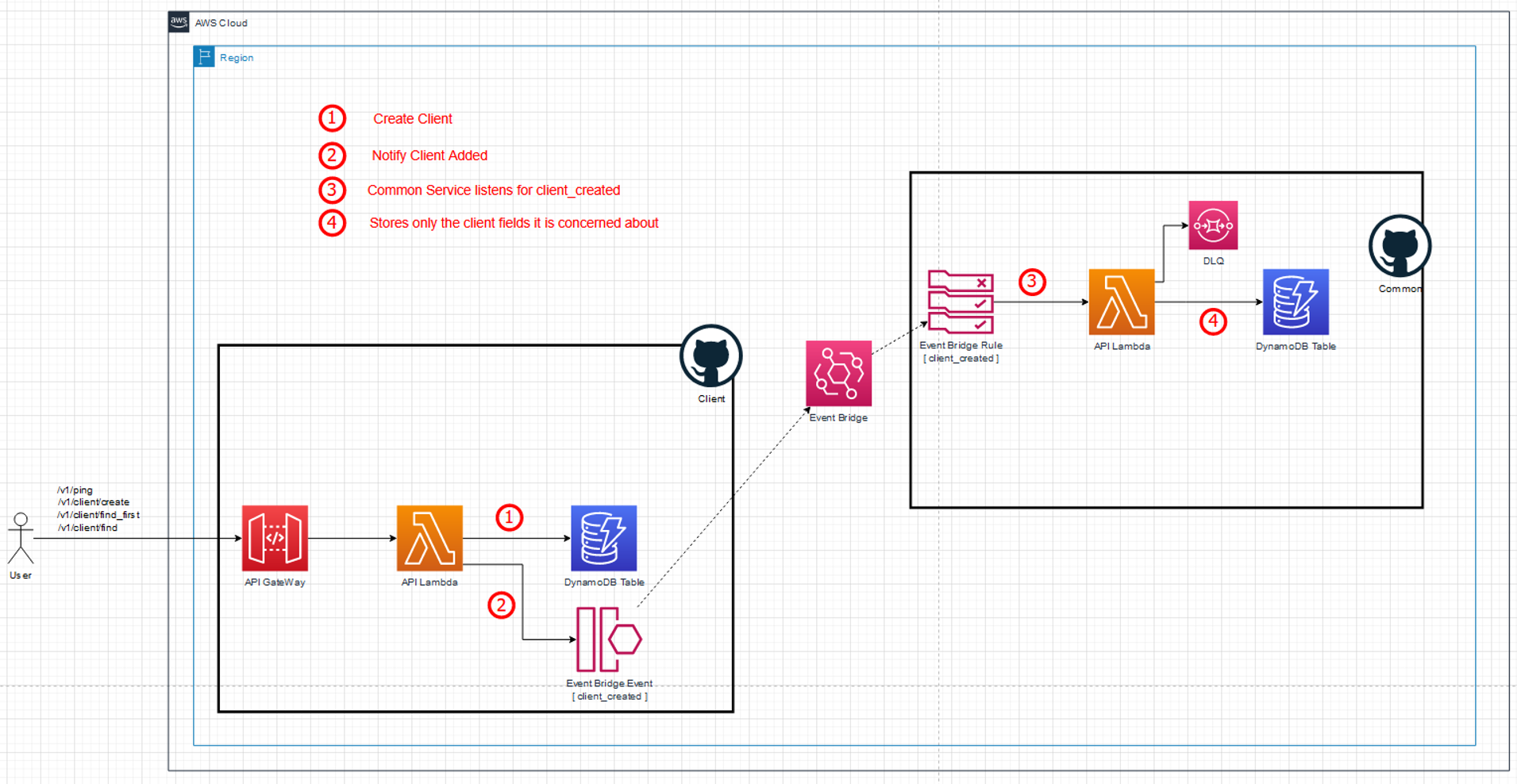
New system – full create client flow (Click to enlarge)
The common service also listens to the create-person event. It looks up the client information in its own DynamoDB table and then sends the SNS message. At the same time , the client service also listens to the create-person events. It uses the client-id that comes with the event to increment the person counter for that specific client in the client service DynamoDB table.
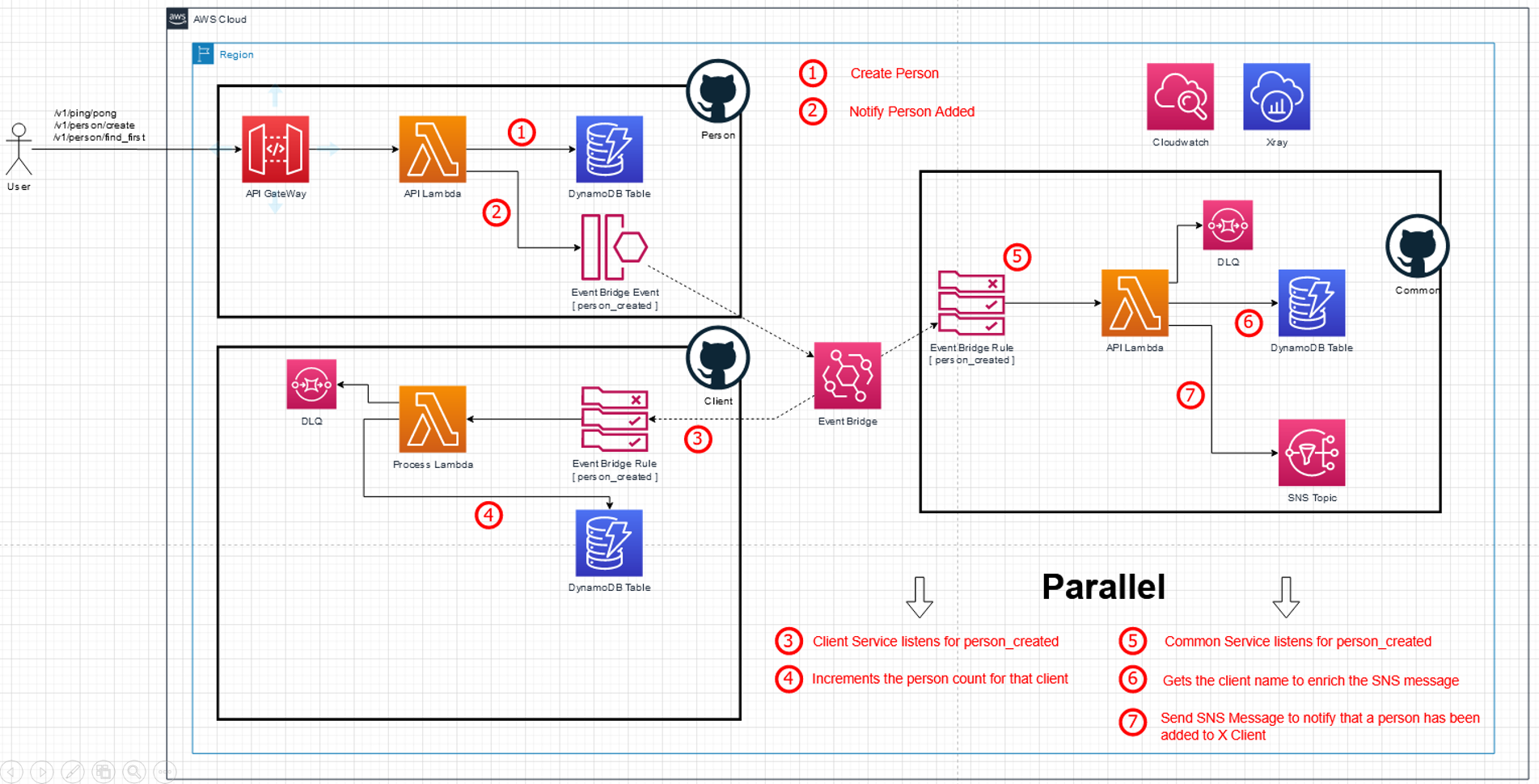
New system – full create person flow (Click to enlarge)
What has changed?
We used Event Bridge to remove direct HTTP API calls between microservices. It also allowed us to move some logic to where it belongs. The common service should not be responsible to increment the specific client’s person counter in the first place. That functionality is now contained within the client service, where it belongs.
We basically borrowed two principles from the SOLID OOP principles :
- Single Responsibility – Each service is only concerned with its own core functionality.
- Open Closed – Each service is now open for extension, but the core functionality is closed for modification.
Then we introduced BASE consistency into the system:
- B asic A vailability – Even if the client service is down the common service can still operate as it has a copy of the data. Thus the data layer/plane is still operational.
- S oft State – Stores don’t have to be write-consistent or mutually consistent all the time.
- E ventual Consistency – The system will become consistent over time, given that the system doesn’t receive input during that time.
A BASE system is almost always going to be an AP system if you look at the CAP theorem. Meaning it favors A vailability and P artitioning over C onsistency.
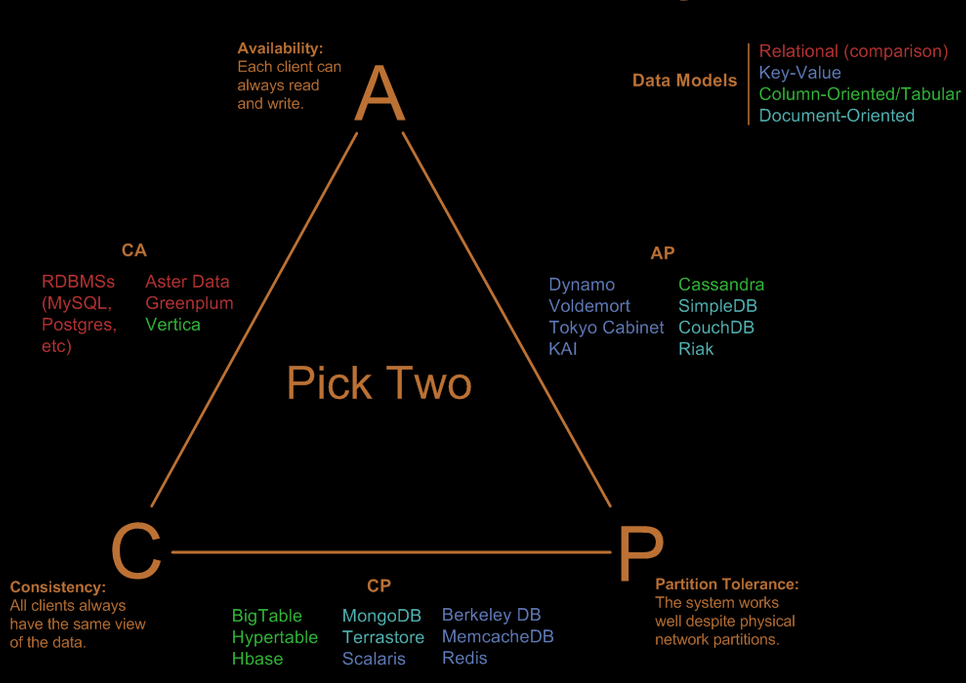
DynamoDB is an example of an AP system as well. Your data is stored on multiple 10GB partition drives spread over multiple Availability Zones. That replication takes a few milliseconds, up to a second or two. Obviously, there are cases where you need to read the data back directly after writing. That is why you can specify a Strongly Consistent read, which just goes back to the writer node and queries the data there instead of waiting for the data to have propagated to all nodes.
S3 has read-after-write consistency for the PUT item command but all other commands are subject to eventual consistency. This means that after updating an item, the old content may still be returned for a short amount of time until the content of that file has propagated to all the storage nodes. There are more examples such as these all over the AWS ecosystem.
Event-driven architectures come with their own pros and cons. Firstly, you need to approach the problem with a different distributed mindset that needs to be present within the company/team as well. Event versioning and communication between teams that own microservices are also crucial. It is a good idea to have a service that keeps a ledger of all events that happen in the system. Worst case, this history of events can be replayed to fix any processing errors in the downstream processing.
Event bridge, like SNS and SQS, guarantees delivery of a message at least once. This means your system needs to be idempotent. An example of an idempotent flow is when the client is created and the common service does a PUT command into the DynamoDB table. If that event gets delivered more than once, it just overwrites the current client with the exact same data.
An example of a non-idempotent flow is when the person iscreated. If the client service gets more than one message, it increments theclient-person counter more than once. There are ways to make this callidempotent, but we’ll leave that for a different blog.
Another thing to consider is that not all systems can accept the delay that eventual consistency introduces into a system. It is perfectly acceptable in our system as a person will probably not be created immediately within one second after a client has been created. Thus, whenever the common service does the client lookup locally, it can be assured that the client data is always populated.
Resilience to Failure
One of the benefits that we have achieved by refactoring to a microservice system is that we are now r esilient to complete services failure. The client service can still operate if the person and common service is down. Similarly, the person service can operate on its own and is not dependent on the other services.
We also removed any timeout problems that was introduced by the previous architecture that synchronously chained API calls. If an Event Bridge target service (like Lambda, in our case) is down, it will retry sending the message with exponential bakeoff for up to 24 hours.
All Lambda functions that process the asynchronous events from Event Bridge have Dead Letter Queues (DLQ) attached. The event will be moved to the DLQ after three unsuccessful processing attempts by the Lambda function. We can then inspect the message later, fix any errors and replay the message if necessary.
Basic chaos can be introduced into the system to test its resilience. This is built into the code and can be toggled on the Lambda functions with environment variables. If ENABLE_CHAOS is true, then the following environment variables are applied:
- INJECT_LATENCY – Number || false
- INJECT_ERROR – String; two possible values: error will throw a hard error and handled will throw a soft error
A Lambda service failure can be simulated by setting Reserved Concurrency to 0. Event Bridge will then retry delivering the event for up to 24 hours.
Conclusion (TL;DR)
We refactored a distributed monolith to a microservice architecture using Event Bridge and broke dependencies using BASE consistency. The code for this blog can be found here: https://github.com/rehanvdm/MicroService.
Posted on August 5, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related