Are We Making Lambda Too Hard?

Allen Helton
Posted on May 3, 2023

You may or may not know that I run a weekly serverless newsletter. The newsletter compiles the best serverless content every week and gives a summary with my thoughts.
I love doing it - it's a great way to stay up to date on all the new feature releases and keep up with trending topics. While I won't claim I read all content around serverless, I will claim that I read the majority of it. This has given me a pretty good indication of what people are doing at their jobs, how they are set up, and what people are pushing as best practices nowadays.
I'm beginning to see a trend that I'm not sure I like... yet. There have been quite a few posts lately about how people recommend structuring Lambda-heavy projects. They talk about the different layers of code, responsibility separation, and code reusability. While these things might sound like no-brainers, it's beginning to make Lambda development feel a bit complex and bring in some habits that seem to fight against the modularity and simplicity the service provides.
Thinking Idealistically
When I think of a perfect environment for Lambda, a few key components come to mind:
- Simple
- Modular
- Isolated
- Up-to-date
Simple
Before I open the handler for a Lambda function, I want to know what problem it's solving. Intuitive file or folder names are a must to quickly identify where code lives if you need to make an enhancement or fix a bug.
When I first started getting into serverless, I had many people ask me "how do you manage all those Lambda functions?" My first answer was that serverless apps are built in code and Infrastructure as Code (IaC), not through clicking around in the AWS console. On top of that, apps are generally composed of many microservices, each with the functions that support that service - meaning all functions aren't kept in the same location and are easier to manage.
My second answer is that code should be intuitively named. If I write a Lambda function that sends an email, I would expect to find the source code for it either in a folder named send-email or a file named send-email.js (or whatever programming language you use). Stick to a standard naming convention so you know where and how to locate something.
Another thing I think of when considering a "simple" Lambda function is legibility. Is the code easy to follow? Do I have to dive 5 layers deep to figure out what the code is doing? If I can quickly glance at a file and pinpoint where something is happening, I've built it simple enough.
Keeping code simple is harder than it sounds. Serverless makes it easy to connect services and add "just one more thing". When you keep adding more things, it gets difficult to understand the scope of the function. Code gets abstracted away to single calls that perform hidden tasks and it just gets... hard.
Function code should be explicit. I should be able to look at the code and know exactly what it does. I don't want to wade through nested method calls and multiple files to figure out that a function is saving an entity to DynamoDB. That's unnecessary complexity that distracts programmers from figuring out exactly how it solves the business problem.
Modular
A function should do one thing. It rarely solves an entire business process on its own. It does one discrete piece of logic and returns (or fires an event to continue a process asynchronously).
Think about a basic CRUD API. Each endpoint is backed by an individual Lambda function. The create endpoint calls the createEntityFunction. The delete endpoint calls the deleteEntityFunction and so on. If you need to react to a new or updated entity, using DynamoDB Streams or an EventBridge event is a great way to orchestrate follow-on activities.
If we take my reference application Gopher Holes Unlimited as an example, we see that I have a function that updates an existing gopher and another function that links gophers to gopher holes.
When a user updates a gopher, they can optionally pass in a gopher hole identifier. When a gopher hole id is provided, a link record is created in DynamoDB so the gopher hole can come back in a query if the user wants to see all gopher holes associated with a particular gopher. But in the app, the logic is separated for the sake of modularity.
There could be more than one way to link a gopher hole to a gopher. So by splitting the logic that creates the link record into its own function, I can reuse it in a number of different business processes. I could link the gopher hole with an event, I could add it as part of a Step Function workflow, or I could even make it its own endpoint. Because it's modular, I can reuse it however I like.
Isolated
Early in my serverless journey, I had an epiphany. My background was in thick client applications written in .NET. I was very used to spaghetti code that was called from all over the place. We routinely would fix a bug in file A and create two new bugs in files B and C because they shared the code and expected different behavior.
But that wasn't the case with Lambda. A function is a discrete unit of code. It's completely self-contained. If I changed something in function A, there was no way I was going to affect function B.
I've seen some patterns lately that change that paradigm a bit. The functions contained in a microservice all have their isolated handlers that contain things like input validation, client initialization, and configuration loaders, but then they call into shared logic and data access layers (logical layers, not Lambda layers).
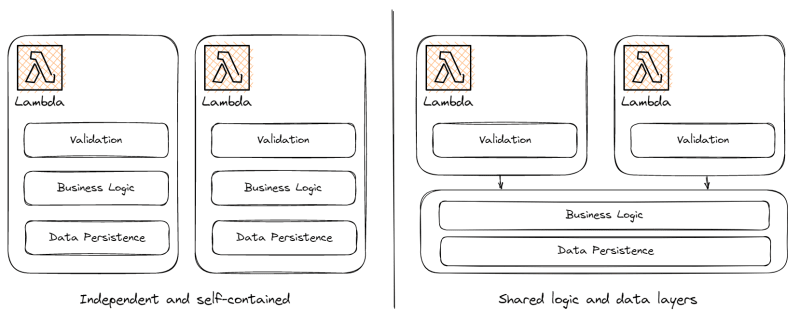
I'm not saying one is better than the other, but there are definitely tradeoffs between the two methods. When you have independent and self-contained functions, you guarantee one change won't accidentally affect an unrelated Lambda function. However, you have more places to change when refactoring, extending a data entity, or adding a new feature. You must keep track of all the functions that handle a particular entity.
On the flip side, with shared logic and data layers, you only need to update one spot when making code changes. But the tradeoff here is that you could inadvertently break an unrelated Lambda function because the shared code was changed. Unit tests help catch these accidents, but they aren't perfect!
Up-to-date
One of the things I love about cloud, specifically serverless, is the shared responsibility model. Developers write code, configure resources, and manage permissions, while the cloud vendor handles the rest. This includes keeping all operating systems up-to-date and secure, guaranteeing infrastructure availability and redundancy, and managing networking between service calls.
However, in January of 2023, AWS released runtime management controls, providing users the ability to selectively choose when they get patches to the runtime their functions are running on. Users can select automatic updates (which is how it has always been), update the runtime when the function code updates, or update manually.
Unless you have a very good reason to not take updates as they are made, you should ignore this feature.
At a previous job, we allowed users to choose when they upgraded versions of our flagship application. It started as a nice offering we provided users, but as we grew, it turned into a nightmare for developers. Over the course of a few years, we had over 125 versions of the same app in production at any point in time. Estimates for bug fixes and enhancements grew tenfold because they had to be patched back into a crazy amount of different versions.
The operational burden of managing all these versions made us quickly realize we messed up.
Granted, Lambda runtime management is on AWS and not us - the consumers. But choosing to not be on the latest version means your code will fall further and further behind important security patches, runtime enhancements, and optimizations. You'll end up being frozen in time because it will continuously get harder to update to the latest and greatest.
Next Steps
Many of you are reading this and thinking "this isn't how you build enterprise-grade production software." To that I only have one question - why not?
What I've described above is how we built two completely serverless apps in use by tens of thousands of people every day. The team has been able to maintain the software without too many hiccups, and we've kept the operational and development burden low by keeping our functions isolated.
That said, your dev team will build experience and familiarity with your code no matter how it's structured. They will become equally as proficient if your functions are isolated or if they share business logic and data access layers.
But if you want to minimize blast radius when things go south, consider keeping functions small and separate. Try to keep the code simple, you want to get a feel for what the function does at a glance. You don't want to spend an hour trying to figure out what code is doing because of an unnecessary amount of abstractions and inheritance.
Abstraction for the sake of abstraction is detrimental. Sometimes being explicit results in better maintainability.
Cleverness isn't simple. It's hard to understand. Remember, you're not going to be the only person maintaining the code you're writing. You might be the one writing it now, but you likely won't be the person enhancing it in two years. Instead of finding a clever solution in 10 lines of code, opt for a simple solution in 20.
Build your functions with single responsibility in mind. Make them do one thing and make them do it well. Chain functions together in Step Functions or choreograph them with events. Use this modularity to your advantage.
I've found great success with keeping it simple. Some might consider my approach to development with Lambda naive, but it's worked! It doesn't need to be more complicated than developing building blocks and putting them together.
As always, I'm happy to discuss anything I've mentioned in this article. I'm perfectly aware it's a hot take, but until I've seen why it doesn't work, I'm sticking to it.
Happy coding!
Posted on May 3, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



November 21, 2024