Solving The Austin Problem with a Data Privacy Vault

Sean Falconer
Posted on February 1, 2024
Data anonymization and tokenization play a crucial role in safeguarding sensitive information. Traditional tokenization systems, however, encounter significant limitations that hinder their effectiveness, breaking certain workflows and complicating security. This blog post delves into the "Austin Problem" – a challenge arising from traditional tokenization systems – and explores how Skyflow's data privacy vault addresses these issues.
Understanding Data Anonymization and Tokenization
Tokenization is a non-algorithmic approach to data anonymization that swaps sensitive data for tokens. For example, if you tokenize a customer’s name, like “John”, it gets replaced by an obfuscated (or tokenized) string like “A12KTX”. Because there’s no mathematical relationship between “John” and “A12KTX”, even if someone has the tokenized data, they can’t get the original data from tokenized data without access to the tokenization process.
A common form of tokenization is PCI tokenization, whereby credit card data is replaced with randomly generated tokens.
As an example, when integrating with a payment service provider (PSP) like Stripe, Adyen, or Braintree, your card acceptance flow will look something like what’s shown below.
The front end SDK will collect the credit card information and pass that along to the issuing bank. Once the card is validated and authorized, the gateway or PSP will store the card and pass back a token as a stand-in for the card. You can safely store the token in your backend and be free from PCI compliance. The only thing you care about is the token and that’s enough for you to do everything you need to do with the credit card when relying on the PSP’s SDKs and APIs.

But tokenization isn’t limited to credit card data; it can anonymize various types of sensitive information, such as names, addresses, social security numbers, and more. The inverse process of tokenization, called detokenization, retrieves the original data from tokens using a token map.
Before we get into the limitations of this approach, let’s take a look at how traditional tokenization systems work.
How Traditional Tokenization Works
Conceptually, tokenization is fairly simple, swap sensitive data for a non-sensitive randomly generated value and keep track of the mapping from sensitive to non-sensitive values and vice versa. From an implementation standpoint, here's how these systems typically work:
Token Generation: When sensitive data needs to be protected, such as a customer's name, a tokenization system generates a random or pseudo-random token, which is a unique alphanumeric string like "A12KTX."
Token Map: The system maintains a token map or token dictionary, functioning similarly to a hash table. This map associates each original data value (e.g., "John") with its corresponding token (e.g., "A12KTX"). This mapping is stored securely.
Token Replacement: The sensitive data, such as "John," is replaced with its corresponding token, "A12KTX," before it is stored or transmitted. This tokenized data is what gets used in databases, applications, or during data exchanges.
Detokenization: When the original data needs to be retrieved, a process called detokenization is used. To detokenize data, the system looks up the token in the token map and retrieves the corresponding original value. Only authorized users or processes with access to the tokenization system can perform detokenization.
Security: Traditional tokenization systems emphasize the absence of a mathematical relationship between the original data and the token. This means that even if someone gains access to the tokenized data, they cannot reverse-engineer it to obtain the original information without the tokenization process and access to the token map.
Protection of Original Data: Since the original data is never stored alongside the tokenized data and is only retrievable through the token map, even if the environment containing the tokenized data is breached, the original data remains secure and uncompromised.

.
AWS has a great article going through in detail how to create such a system. But even a seemingly simple system has a lot going on under the covers that you would need to build and maintain as shown below.

Limitations of Traditional Tokenization Systems
Traditional tokenization systems suffer from three major limitations:
Token Overload: In these systems, mapping a given input string to a token can lead to issues, as it may result in token collisions. This can break analytics and clean room workflows.
Limited Security Model for Detokenization: Users or processes often have broad permissions for detokenization, which poses security risks and lacks granularity.
Choice Between Tokenization and Encryption: Traditional tokenization systems typically do not integrate encryption, limiting their security capabilities.
Let’s take a closer look at each of these problems.
The Austin Problem: Token Overload
To support analytics use cases with tokenization, the same input value needs to generate the same tokenized output value. This is known as consistent or deterministic tokenization. With consistent tokenization, I will always know that the city “San Francisco” will be tokenized the same way. This approach keeps query operations like counts, group bys, and joins intact.
However, with traditional tokenization, there’s no disambiguation between different types of input. The token map doesn’t know that a particular string represents a city, state, name or any other information. This naive approach can lead to undesirable effects and is the manifestation of what I call The Austin Problem.
The Austin Problem occurs when the same input string generates the same token value for two different distinct types of data For instance, if a customer's first name is "Austin" and another customer lives in the city of Austin, Texas, their name and city would yield the same token (see the image below).

Not being able to disambiguate the data type when going from token to original value can cause incorrect analytical calculations and confusion depending on the design of your analytics store.
Additionally, this simplistic approach complicates adhering to privacy requirements like data subject requests (DSAR) and the right to be forgotten (RTBF) that are a feature of many privacy regulations like GDPR and CCPA.
For example, let’s say you get a RTBF from a customer named ‘Austin’. If you have only one customer named 'Austin.', ideally, you would delete the mapping from 'Austin' to the token value in the Token Store, rendering any tokens stored in your downstream services invalid. However, this becomes challenging if you also need to retain the token mapping for customers residing in the city of Austin, Texas. Consequently, what initially appeared as a straightforward compliance action turns into a manual project to ensure analytics continuity for customers in that city.
Similar to the challenges with analytics, clean rooms where the data has been tokenized by both parties can also be problematic. A clean room depends on being able to perform join operation between two or more parties within a secure isolated environment. Depending on how the data is stored by the businesses, not being able to know the difference between something like a person’s name and a person’s city could lead to miscalculations.
Limited Security Model for Detokenization
Traditional tokenization systems lack fine-grained access control over detokenization permissions and output. This makes it challenging to cater to various use cases and data types.
For example, a marketer might only need partial access to a customer's date of birth, while the customer should see their full date of birth.

Even if you can add some additional magic to control access to who can detokenize data based on their identity, since the token map has no knowledge of the datatype, they’re all just strings, applying data masking based on identity gets complicated.
The Choice Between Tokenization and Encryption
Tokenization offers a unique advantage to encryption: it severs any mathematical link between the original data and the generated tokens. In contrast, encryption processes can potentially be reverse-engineered. Additionally, tokens provide practical benefits when it comes to searchability and analytics, as they don't require decryption for use. However, what we really need is a combination of these techniques.
In traditional tokenization, data encryption operates as a distinct system, and the process of detokenization involves bringing the data back to its original plaintext form. If data masking is necessary, it is applied in real-time to the plaintext data. The separation of encryption, detokenization, and masking within traditional tokenization systems introduces potential vulnerabilities at each integration point.
Solving the Austin Problem
The key to solving the Austin Problem requires a more sophisticated approach that brings what has been historically siloed and independent systems together like tokenization, access control, data masking, and encryption. Additionally, we need to re-think traditional tokenization to expand its functionality to address some of the outlined limitations.
Skyflow is a data privacy vault that isolates, protects, and governs sensitive customer data. With Skyflow, the vault supports a new more advanced tokenization called schema-based tokenization.
With schema-based tokenization, instead of relying on a single token map where tokens regardless of data type get intermixed, we can define a schema the same way we would for a database, and each column has its own self-contained tokenization map and tokenization scheme.
Each column within the schema can define its own custom format rules, allowing you to generate any kind of token. In the example image below, you can see the settings for a format-preserving consistently generated token for a credit card number, and also a consistently generated token in the form of a UUID for a cardholder name.
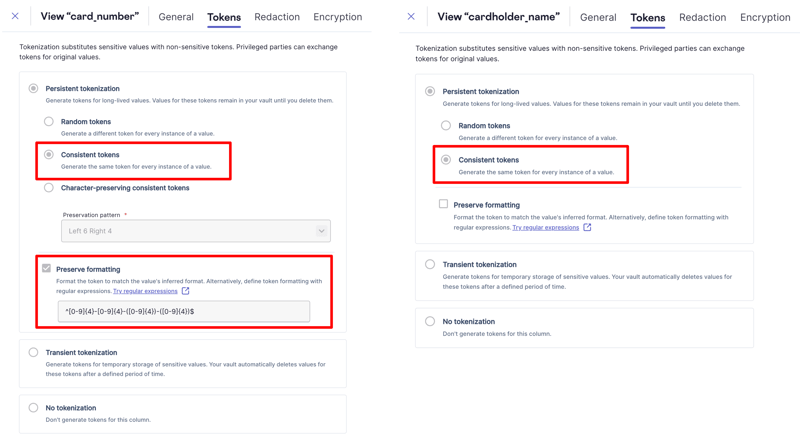
Skyflow supports a variety of sophisticated tokenization techniques, like transient tokenization for temporary storage. These are essentially self-destructing tokens for ephemeral data.
Additional enhancements include:
Data Type Awareness: Skyflow's system understands the data type of input, allowing for customized tokenization. Each column within the schema can define its tokenization rules, accommodating various data types.
Column Groups: To prevent token overload, Skyflow supports column groups, similar to namespaces in programming. This feature restricts deterministic tokenization to specific columns, ensuring tokens remain unique even when dealing with similar input values.
Fine-Grained Access Control: Skyflow's data governance engine offers fine-grained policy-based access control, extending to the detokenization process. This enables control over who can access what data, how it's accessed, and its format.
For example, in the image below, the same data is shown in two different ways depending on the role of the viewer. The Customer Support role not only has restrictions on the columns, but also for specific rows.
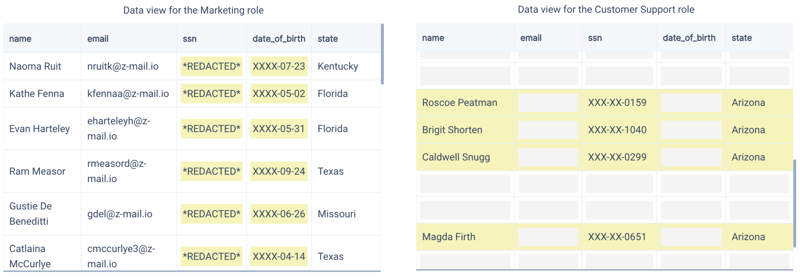
An example policy for customer support is shown below.
ALLOW READ ON payments.name, payments.state WITH REDACTION = PLAIN_TEXT WHERE payments.state = Arizona
ALLOW READ ON payments.ssn WITH REDACTION = MASKED WHERE payments.state = Arizona
Simple policies control how data can be viewed and by whom, making tokenization and access control not isolated disconnected features, but all part of the same system.
Integration of Tokenization and Encryption: Even with the enhancements available through schema-based tokenization, there are still workflows that can’t be fully supported. Similarly, encryption is great, but typically requires decrypting the data in order to perform operations like search.
Skyflow solves this with polymorphic data encryption, a unique approach that fully supports operations on encrypted data. For example you could query your vault to calculate the total number of customers that are over the age of 21 in the state of California without ever decrypting the data.
Skyflow seamlessly integrates tokenization, encryption, data masking, and access control, enhancing security while preserving data usability. This combination ensures data remains protected throughout its lifecycle.
Wrapping Up
The Austin Problem highlights one of several limitations with traditional tokenization systems, which hampers analytics workflows and makes adhering to certain privacy requirements like DSARs and RTBF extremely difficult.
Skyflow’s data privacy vault technology addresses these challenges by providing data type awareness, column groups, fine-grained access control, and integrated advanced tokenization and encryption. This approach not only enhances security but also preserves data usability, a tradeoff that companies have historically had to make. Polymorphic data encryption balances the need for security while keeping the data usable for any workflow you might perform with sensitive customer data.
Posted on February 1, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.