Learn How to Write AWS Lambda Functions with Three Architecture Layers

Ran Isenberg
Posted on April 24, 2023

Writing all your business domain logic code in the Lambda handler entry function can be very tempting. I’ve heard many excuses during the code review: “It’s just a few dozen lines of code” or “It’s still very readable.”
But let’s face it; when you developed regular non-Serverless services, you didn’t write your entire service code in one file or function.
You modeled your code into classes and modules and assigned each a single responsibility based on SOLID principles.
Writing Lambda functions should not be any different. Your handler function should not contain the actual business domain logic, nor should it access your DynamoDB table. And there are good reasons for that which we will cover in this post.
So, in this blog post, you will learn how to write AWS Lambda function code containing three architectural layers: the handler, the logic, and data access layer. These layers result in well-organized code that is easier to maintain, easier to test, and as a result, leads to fewer bugs down the road. In addition, we will discuss error handling.
A complimentary Python Serverless service project that implements these concepts can be found here.
](https://res.cloudinary.com/practicaldev/image/fetch/s--vFAJl2nV--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/2000/0%2Ao3FTCHZ7L8hXVqLq.png)
This blog post was originally published on my website “Ran The Builder”
Table of Contents
The AWS Lambda Function Architecture Layers
Error Handling Across Layers
Sample Serverless Service
The Handler Layer
Error Handling
The Logic Layer
Relationship to Data Access Layer
Data Access Layer (DAL)
The AWS Lambda Function Architecture Layers
AWS Lambda architecture layers are the building blocks of Serverless applications that allow developers to write reusable, organized, easy-to-maintain code with a single responsibility.
These principles go well with SOLID principles, where the ‘S’ stands for single responsibility.
Encapsulating a single responsibility code into a single layer reduces the spaghetti code syndrome. For example, imagine a use case where API calls to your database are scattered across unrelated files and functions. Now imagine a better scenario where all API calls to your database reside in a single module or file, a single layer. This layer’s sole responsibility is handling connections and API calls to the database. This encapsulation and single responsibility makes it:
Easy to share the code between multiple Lambda functions, i.e., call it from different functions — zero code duplication.
Test the single responsibility code, i.e., test all database-related APIs and edge cases in a single module.
Easier to maintain the code. When you want to change an API call or add a cache, you make the changes in one module or file instead of multiple scattered files with possible code duplication.
I believe there are three layers in AWS Lambda functions:
The handler layer
The logic layer
The data access layer (DAL)
In Python, a layer is a reusable module, i.e., a set of files.

Error Handling Across Layers
There are two methods: raise an exception or return a None or True/False to mark a success or failure. I’ve tried the return value method in one of my services, and it gets messy quickly. There’s a great discussion over at stack overflow, and I suggest you check it out. In Python, exceptions are the Pythonic way to mark that something has gone wrong, but you must ensure you catch all exceptions. Exceptions stop processing quickly across layers.
However, raising layer-specific exceptions from one layer to another can break their single responsibility concept. Why should the logic or handler layers be familiar with DynamoDB exceptions? It shouldn’t. That’s why you should use custom exceptions that mark their type: Internal server error, bad request exception, etc.
How does it work in practice? Each layer is responsible for catching its layer-specific exceptions, logging them, and re-raising them as one of the relevant custom exceptions with the stack trace.
But who catches these custom exceptions? Well, the handler layer will catch them as it’s the layer that knows how to turn these exceptions into a relevant output to the caller. We will discuss it in further detail in the handler layer section.
Sample Serverless Service
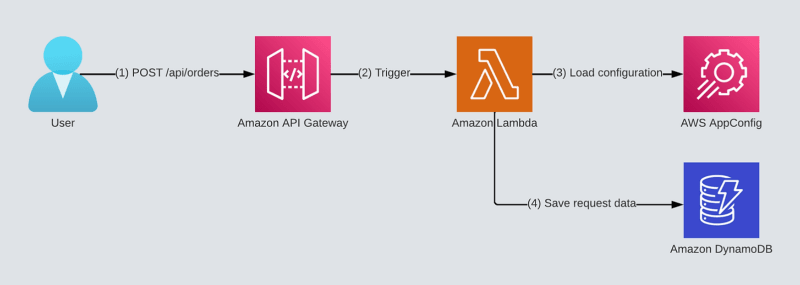
Let’s go over our sample ‘Order’ service and analyze what each layer is responsible for.
The template project we will use is a simple ‘orders’ service.
It has an API GW that triggers an AWS Lambda function under the POST /api/orders path.
It stores all orders in an Amazon DynamoDB table.
It also deploys and stores dynamic configuration and feature flags in AWS AppConfig.
Read more about it here.
The complete code can be found here.
The Handler Layer
The handler layer is the entry function called when the function is invoked.

It has several responsibilities:
Load & verify configuration from environment variables
Initialize global utilities such as logger, tracer, metrics handler, etc.
Handle input validation
Pass input to the logic layer to continue to handle the request
Return output from the logic layer back to the caller
As you can see, there’s a complete segregation of responsibilities between the handler and other layers. The handler loads up the function, ensures it’s properly configured, and delegates the input to the logic layer that knows what to do with the information.
Then, when it gets back the output from the logic layer, it returns it in a manner only it knows back to the caller. No other layer will create the caller response. In our example, the Lambda function returns a JSON response to the caller. Thus only the handler will create the JSON and assign the correct HTTP response code. That’s its responsibility.
Error Handling
The handler layer will catch any exception raised due to misconfigurations, global utility errors, and invalid input and return the correct response to the caller. If the handler layer is triggered by an SQS, the handler layer can send the invalid input to a dead letter queue or raise an exception to return the payload to the queue.
The handler layer is also required to catch any global exceptions raised by the logic or data access layer (see the explanation in the error handling section).
Let’s look at the ‘Order’ service ‘create order’ handler. The ‘create order’ Lambda function creates new orders for customers and saves them in the DynamoDB table.
In lines 22–26, we initialize our global utilities: environment variables validator, tracer, and metrics utilities for the current invocation and set the logger correlation id.
In lines 31–36, we fetch our dynamic configuration from AWS AppConfig and parse the response to ensure we work with the correct configuration. Any failure will cause an internal server error HTTP response to return to the caller.
In lines 38–44, we parse and validate the input according to our Input schema. Any error will cause an HTTP BAD Request error to return to the caller (as it should!).
In lines 48–55, we send the customer input to the logic layer. The handler does not know how the input is handled; it just delegates it to the next layer. The logic layer returns a ‘CreateOrderOutput’ object.
In line 58, the handler returns the ‘CreateOrderOutput’ to the caller as an HTTP OK 200 response with a JSON body built from the ‘CreateOrderOutput’ object.
The Logic Layer
As its name hints, the logic layer contains all the business domain logic code, functions, and modules required to process the request. It is where the magic happens. The logic layer can and should be shared by multiple Lambda handlers.
In the context of our ‘orders’ service, the logic layer can have Python functions such as ‘create order’, ‘get order’, ‘update order’, and ‘delete order’. Each function represents an encapsulated business use case and contains the required validations, logical checks, feature flags, and, ultimately the code that implements it.
The logic layers get an input of its required parameters from the handler layer that calls it- mostly a mixture of required configuration (table name from environment variables) and the customer input parameter (in our use case: the number of products to purchase and customer name).
The logic layer handles the request, calls the data access layer (if required), and returns an output object to the handler layer. The logic layer does NOT access any database directly; it always delegates the required action through defined interfaces to the data access layer.
Relationship to Data Access Layer
The logic layer is the only layer that calls the data access layer. As such, it is familiar with its concrete interface implementation; in our case, it will initialize a DynamoDB data access layer handler and provide its constructor with the DynamoDB table name by calling a getter function that returns an object that implements the DAL interface.
The logic layer is the only layer familiar with the handler output schema and the DAL database entry schema. In our case, we create a new order and return the order id, customer name, and amount of purchased products. Order id is generated in the data access layer, representing a primary DynamoDB table key. The logic layer will call the ‘create_order_in_db’ interface function in the DAL layer, get its output object, and convert it to the required output schema object.
Important — don’t use the same schema for both output and database entry, thus making a coupling between them. The DAL and handler layers must remain decoupled, so you won’t need to change your API when you add a field to your database entry schema. In addition, usually, the database entry contains metadata that belongs to the DAL layer but should not be returned to the REST API caller. The conversion function between the DAL entry and to output schema will filter the unwanted fields.
Let’s go over some code examples:
In line 11, we create a new DAL layer handler by calling a DAL handler getter function from the DynamoDB DAL handler module. The function is defined in the DAL layer in the concrete DynamoDB implementation. The class implements the DAL interface functions: ‘create order’, ‘get order’ etc.
In line 12, we call the DAL interface function the ‘create_order_in_db’ function and save the new order. The logic layer works with an object that implements the interface and is unfamiliar with any internal implementation other than the initialization (getter) function.
Order id is generated at the DAL layer. In this example, there is no particular logic surrounding the order creation other than saving it to the DynamoDB table.
In line 14, we convert the DAL entry to the ‘CreateOrderOutput’ schema. As you can see, since it is a simple example, they are identical; however, as mentioned above, in more advanced use cases, only a subset of the DAL schema is returned to the caller.
Both schemas’ definitions are below:
‘OrderEntry’ is defined under the schemas folder of the DAL layer as it represents a database entry. It contains the order id, customer name, and the number of products ordered.
‘CreateOrderOutput’ is defined in the handlers schema folder.
Data Access Layer (DAL)
The data access layer is the only layer that accesses the actual database infrastructure, creates the connections, is familiar with the database implementation details, and calls its APIs.
The DAL layer presents an interface for all required database actions by the logic layer and a concrete database handler that implements it.
The database type and implementation are abstracted away by the concrete database handler that inherits this interface. The interface usage represents another SOLID principle, dependency inversion.
Our ‘order’ service has an database actions interface containing a ‘create_order_in_db’ function and in another a file in the layer, a DynamoDB DAL handler class that implements the interface.
Why should you use an interface and a database handler that implements it?
This interface makes it simple to replace the database in the future. All you need to do is to create a new handler that inherits from the interface. Of course, you will need to handle the IaC (infrastructure as code) part, create the resources, and set the Lambda function’s role the new permissions, but as for the application code, it’s all encapsulated in one new database handler class. Once the new handler is ready, just set the logic layer to create a new instance of the new database handler and use it. You can even use both as a testing phase until you gain enough confidence that it’s working correctly.
Let’s take a look at the interface code example:
In line 9, we define the created order in the database function. Every database implementation will save the customer name and the order item count, but with different API calls. Future interface functions can include getting an order by an id, updating an order, and deleting an order.
Here’s the complete code example for a concrete class that implements the interface for a DynamoDB DAL handler:
In line 16, we inherit the abstract class, thus implementing the interface in Python.
In line 28, we implement the interface ‘create_order_in_db’ function.
In line 29, we generate an order id that serves as the DynamoDB primary key.
In line 32, we create an entry object to insert into the table.
In line 34, we create a boto3 DynamoDB table object. We cache the resource (in lines 22–25) for up to 5 minutes to keep a live connection to the table between invocations as a performance optimization.
In line 35, we insert the new order into the table.
In lines 37–39, we handle exceptions. As discussed before, we log the exception and raise it again as a global exception — an internal server error exception that the handler layer will catch and handle.
In line 42, we return the created entry to the logic layer.
In lines 45–47, we create a concrete DynamoDB Dal handler object and use the ‘lru_cache’ decorator to make it a singleton class instance so it can be reused in multiple invocations. This is the handler that the logic layer uses. It is the only concrete DAL implementation it is familiar with.
Posted on April 24, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

