How I build resiliency on the financial service application

Danny Chan
Posted on January 20, 2024

What is resiliency?
Basic Architecture for resilient
Terminology
What is an Operational Readiness Score (ORS)?
What is Chaos Engineering?
AWS Fault Injection Simulator (FIS) targets and actions
Action risk level
What is AWS Resilience Hub?
How to plan resiliency?
Best practices for resiliency
What are Static stability patterns?
Advanced Architecture for resilient
What is resiliency?
Resiliency refers to the ability to recover from disruptions and continue operating even when impaired. It also involves dynamically scaling to meet demand.
Example:
In the case of a disruption, RDS (Amazon Relational Database Service) automatically attempts to launch a new instance in the same Availability Zone and attach the EBS (Elastic Block Store) volume, ensuring continuity of operations.
AWS Tools for Resiliency:
Relational Database (RDS):
- AWS provides tools like the AWS Advanced JDBC Wrapper and Amazon RDS Proxy to enhance resiliency and improve database performance and availability.
Elastic Block Store (EBS):
- The Fast Snapshot Restore (FSR) feature offered by AWS helps in quickly restoring EBS snapshots, contributing to faster recovery times and improved resiliency.
Basic Architecture for resilient
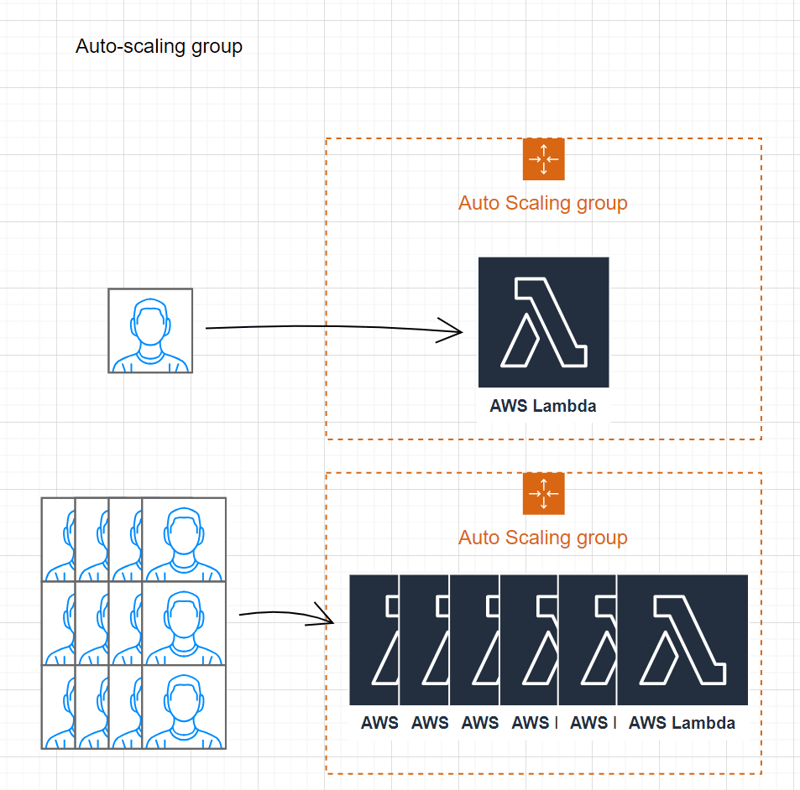
Auto-scaling group
Utilize an auto-scaling group to dynamically adjust the number of instances in response to workload changes, ensuring optimal resource utilization.
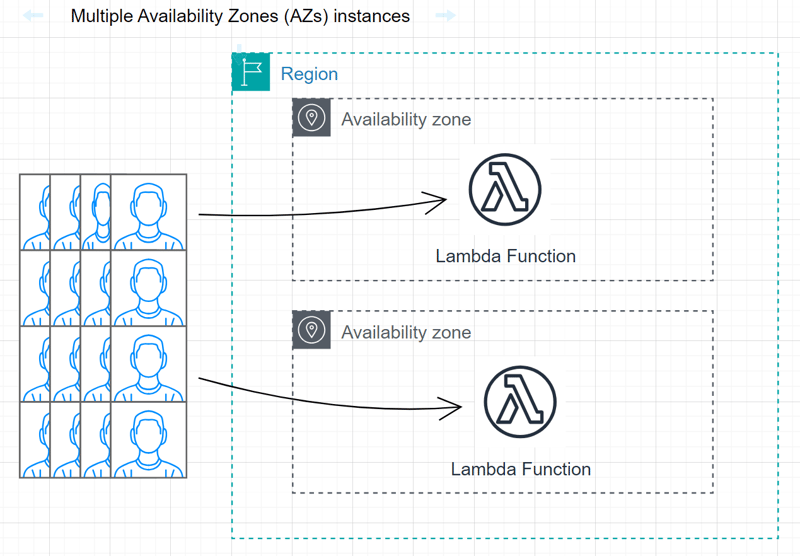
Multiple Availability Zones (AZs) instances
Deploy instances across multiple AZs to enhance fault tolerance and high availability by distributing the workload across different physical locations.
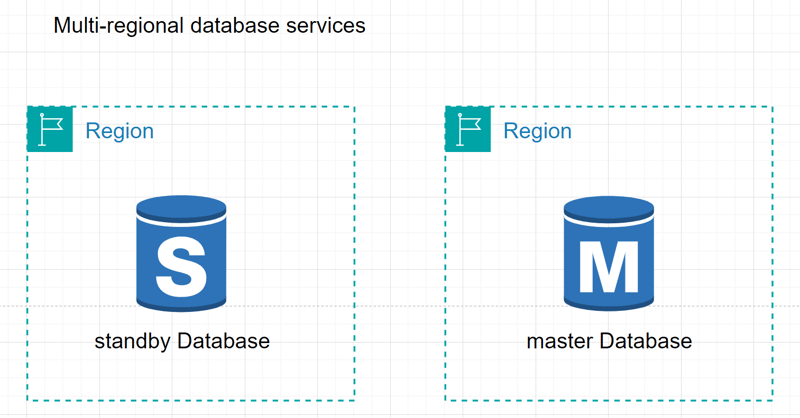
Multi-regional database services
Implement database services across multiple regions to achieve data redundancy, disaster recovery, and improved performance.
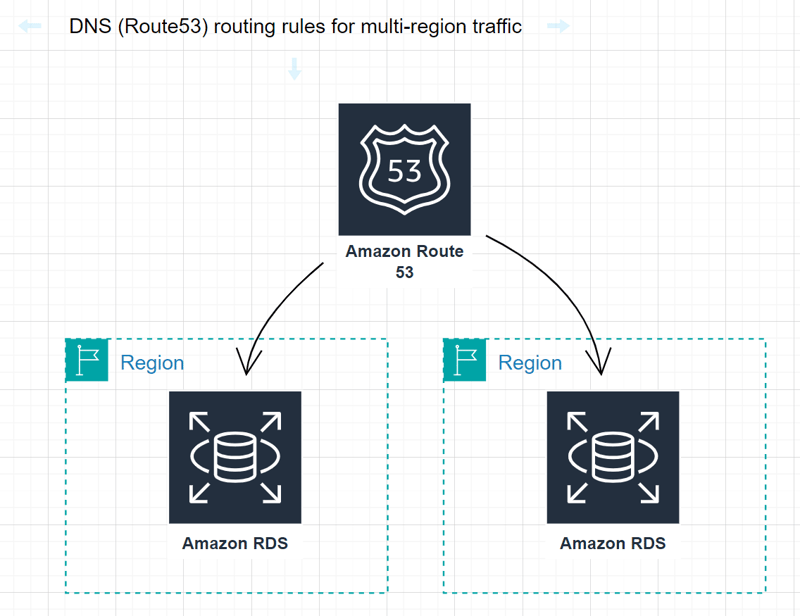
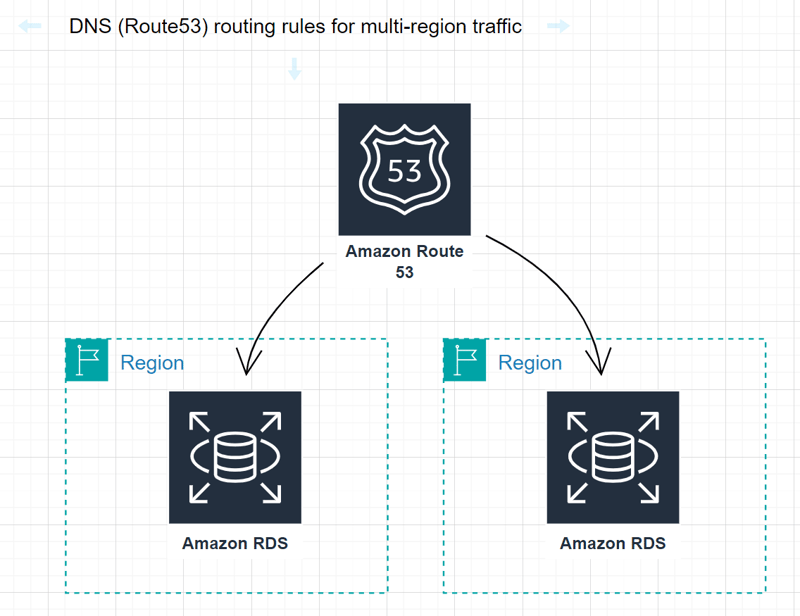
DNS (Route53) routing rules for multi-region traffic
Configure DNS (Route53) routing rules to direct customers' traffic to multiple regions, enabling load balancing and improved responsiveness.
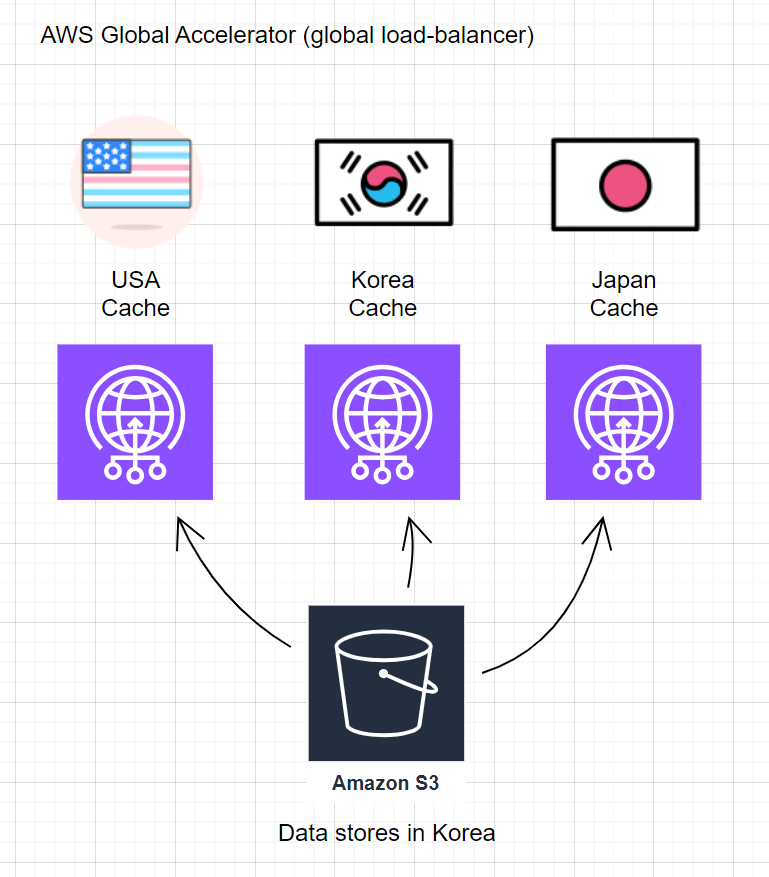
AWS Global Accelerator (global load-balancer)
Utilize AWS Global Accelerator as a global load-balancer to optimize network traffic distribution and improve the performance of applications across regions.
Terminology
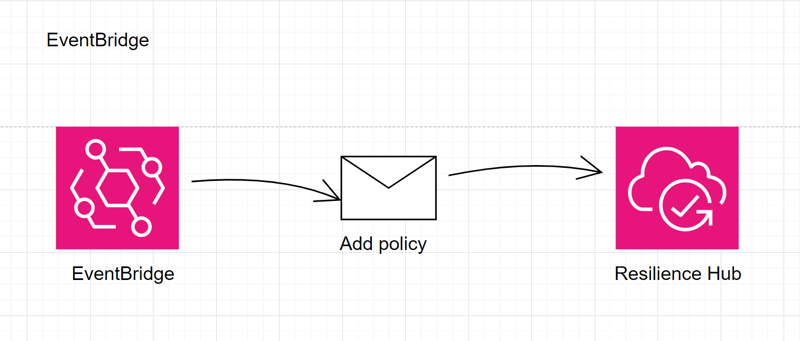
EventBridge
- Generates an event that triggers actions or workflows based on predefined rules.
Amazon Detective
- Investigates the source of a potential threat or security incident, providing insights and analysis.
Route 53
- Domain Name System (DNS) servers
- Facilitates region failover by routing traffic to another region in the event of an outage or disruption.
- Provides failover validation to ensure the failover process is functioning correctly.
Resilience posture
- Overall state or condition of an entity's resilience
- Readiness of the system to recover from disruptions
- preparedness: proactively identifying risks
- redundancy: backup systems
- flexibility: response to changing circumstances
- robustness: building systems that can withstand stress or shocks
- rapid recovery: quick restoration of operations after a disruption
- scalability: scaling resources based on demand
- continuity: uninterrupted functioning of critical operations
AWS Resilience Hub
- Manage and monitor resilience posture and disaster recovery (DR) capabilities across multiple AWS accounts and Regions
- View the resilience status, health, and compliance on the dashboard
- Define resilience readiness goals and track progress
- Assign resiliency posture to applications based on their resilience tier
- Assesses applications against the targets set by their respective tiers, either through the console, scheduled evaluations, or CI/CD pipelines
Resiliency Policies
- the set of guidelines that guide an organization's approach to building resilience
- outline the desired outcomes for managing disruptions
- including technology, operations, security, disaster recovery, business continuity
- consistency, standardization of resilience efforts across different departments
- guidelines for monitoring, testing
- clear communication, awareness, and training throughout the organization
Resiliency Tier
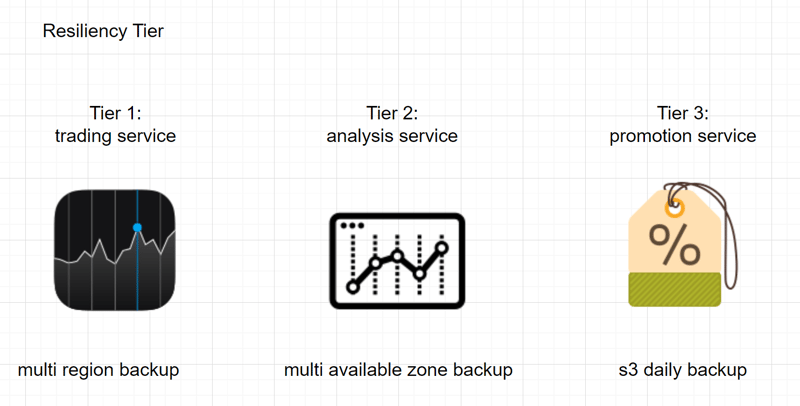
- classification system based on their level of resilience and availability
- defined based on factors such as downtime tolerance, recovery time objectives (RTO), recovery point objectives (RPO)
- higher resiliency tiers indicate greater levels of redundancy, fault tolerance, and recovery capabilities
- setting expectations of service level agreements (SLAs) and recovery capabilities of systems and services
AWS Fault Injection Simulator (FIS)
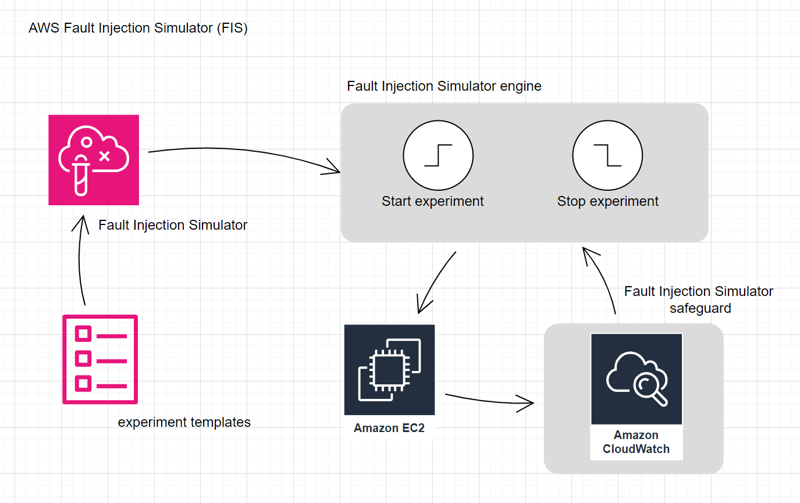
- Perform fault injection experiments on your AWS workloads
- Based on the principles of chaos engineering
- Creating disruptive events to observe system responds
- Improve the performance and resiliency
FIS experiments
- Conducts fault injection experiments on AWS workloads to test resilience and identify potential weaknesses.
Standard Operating Procedure (SOP)
- Refers to a set of step-by-step instructions compiled by an organization to guide workers in carrying out routine operations.
Data sovereignty regulations
- Country-specific requirements that dictate data must remain within the borders of the jurisdiction where it originated, ensuring compliance with data protection and privacy laws.
Security posture:

- Refers to the overall level of cyber security readiness within an organization.
- Prevention, Detection, Response, Recovery, Adaptability
Recovery Point Objective - RPO:
- the maximum amount of data that can be lost after a recovery
Recovery Time Objective - RTO
- the maximum acceptable amount of time for restoring an application
What is an Operational Readiness Score (ORS)?
Ensure compliance with Recovery Point Objective (RPO) and Recovery Time Objective (RTO) Service Level Agreement (SLA) objectives.
Redundancy:
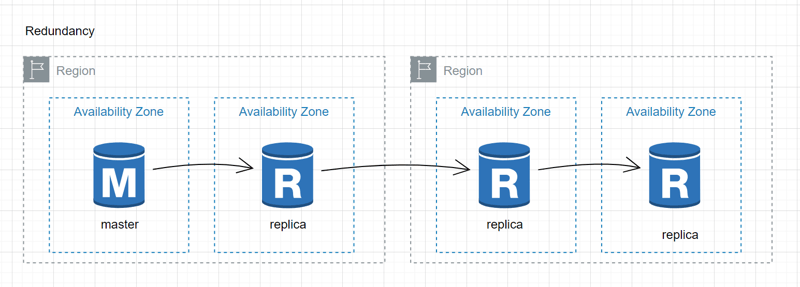
Create copies of volumes within or across Availability Zones to establish redundancy and enhance system resilience.
Disaster recovery:
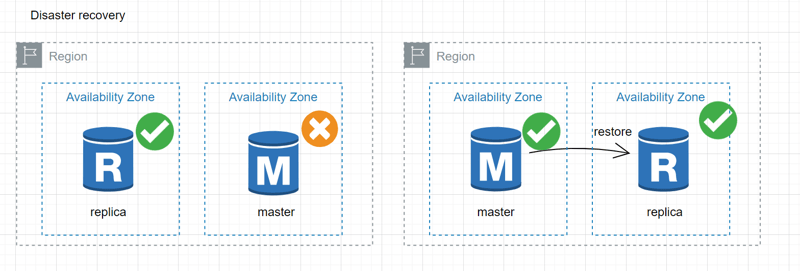
Copy volumes to another region to establish a disaster recovery solution, ensuring data protection and the ability to recover from major disruptions.
Re-deploy production data for test/dev:
Utilize production data for testing and development purposes by redeploying it, allowing for realistic simulations and accurate testing environments.
What is Chaos Engineering?
Goal:
- The goal is to build a more resilient infrastructure.
- The aim is to enable the system to automatically recover from various types of failures.
How:
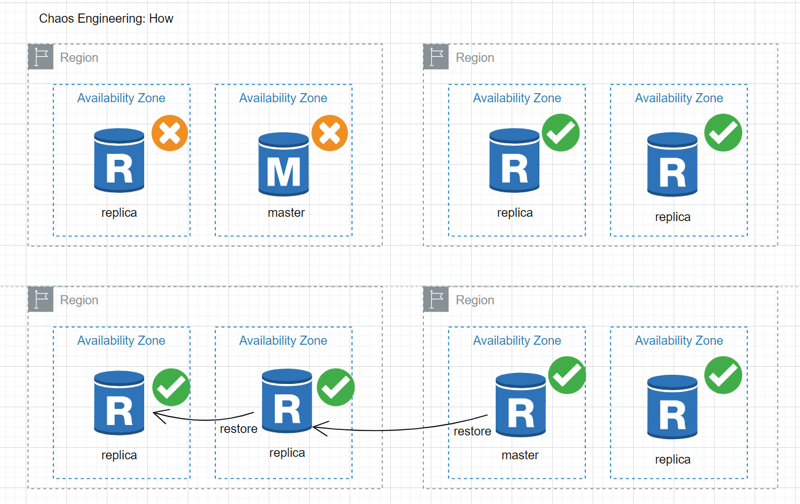
- An environment is established to facilitate Chaos Engineering.
- Production is deliberately disrupted in a controlled manner for learning.
- The intention is to shift the culture and priorities towards resilience.
- The system's ability to automatically recover from failures, such as the loss of an entire region or a spike in traffic, is examined.
- Artificial failures or disruptions, including taking services offline, deleting data centers, or overwhelming the system with fake traffic, are simulated.
What does it do?
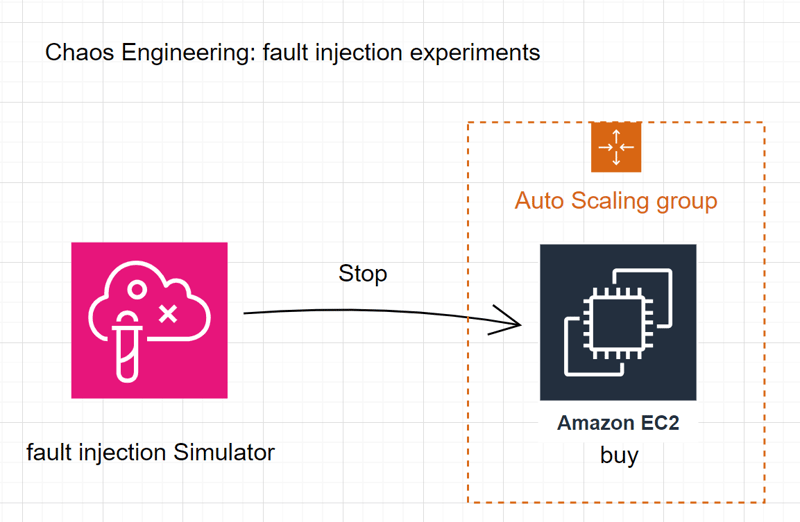
- Chaos Engineering involves conducting purposeful fault injection experiments.
- It helps assess how the system will react to unknowns.
- Real-world conditions are necessary to uncover hidden bugs.
- It aids in managing bottlenecks in distributed systems.
- The system's behavior is continuously tested under unpredictable conditions.
- The goal is to identify weaknesses and single points of failure.
AWS Fault Injection Simulator (FIS) targets and actions
Amazon EC2 actions
- Stop, reboot, and terminate instance
- Spot instance interruptions
- Inject API internal, throttle, unavailable error
- Network Latency
Amazon EKS actions
- Pod CPU stress
- Pod delete
- Pod I/O stress
- Pod memory stress
- Pod network latency
- Terminate Nodegroup instances
Amazon ECS actions
- Task kill process
- Task Stop
- Drain container instances
Amazon S3 actions
- Denies traffic to and from the Regional endpoint
- Add latency to and from S3 from EC2
Networking actions
- Denies the specified traffic to the target subnets
RDS actions
- Failover Cluster
- Reboot Instance
Action risk level
Low risk
- CPU/memory street
- Instance reboots
- Container restarts
- Pause I/O
Medium risk
- Downstream latency increase
High risk
- Availability Zone/Region impaired
- AWS service impaired
What is AWS Resilience Hub?
Central security tool:
AWS Resilience Hub serves as a centralized security tool.
Displays the security and compliance status:
- It provides a visual representation of the security and compliance status.
What it can do?
Analyze applications against targets:
- The Resilience Hub can analyze applications to ensure they meet Resiliency Policies such as Recovery Point Objective (RPO) and Recovery Time Objective (RTO) for app, infrastructure, availability zone, and region.
Aggregate security alerts:
- It aggregates security alerts from various AWS services including AWS Config, AWS GuardDuty, AWS Macie, IAM Access Analyzer, AWS Systems Manager, AWS Firewall, and AWS Health.
Proactively prepare and protect applications:
- The Hub helps to proactively prepare and protect AWS applications from disruptions.
Proactively identify resiliency gaps:
- It identifies resiliency gaps in the infrastructure to take proactive measures for improvement.
Metric-driven approach:
- The Resilience Hub adopts a metric-driven approach, providing scores to assess the resiliency posture of applications
Benefits
Covers multiple accounts:
- It can be used to cover multiple AWS accounts, providing a comprehensive view of the security and compliance status across all accounts.
Finds potential issues:
- The Hub helps in identifying potential issues or vulnerabilities in the infrastructure.
Visualizing dashboard:
- It offers a visual dashboard that displays the security and compliance status of applications.
How to plan resiliency?
Failover plan for resilience:
outlines procedures for replacing failed components, restarting services, or switching to an alternative Availability Zone (AZ) in the event of failures or disruptions, ensuring uninterrupted service availability.
Recovery Time Objective (RTO):
can vary in duration, ranging from minutes to hours, depending on the size and complexity of the system.
RTO Questions:
financial cost? reputational cost? SLA with customers? external compliance or regulatory?
Recovery Point Objective (RPO):
is zero in cases where recoverable instances fail because the EBS (Elastic Block Store) volume can be recovered.
RPO Questions:
the impact of data loss? Can lost data be recreated? How long it takes?
Best practices for resiliency
Goal:
- Fully automate failover processes to prevent data loss.
- Implement a highly available database cluster with synchronous replication across multiple Availability Zones (AZs).
- Ensure data backup is in place.
1
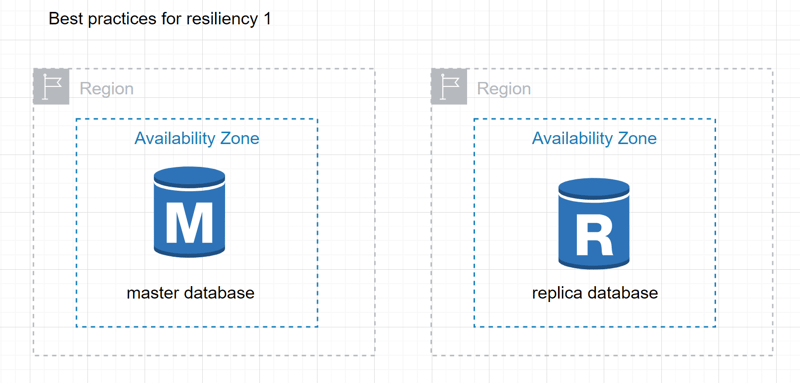
Keep a Single-AZ Amazon RDS and create a read replica in the primary region with an additional read replica in a secondary/different region.
2
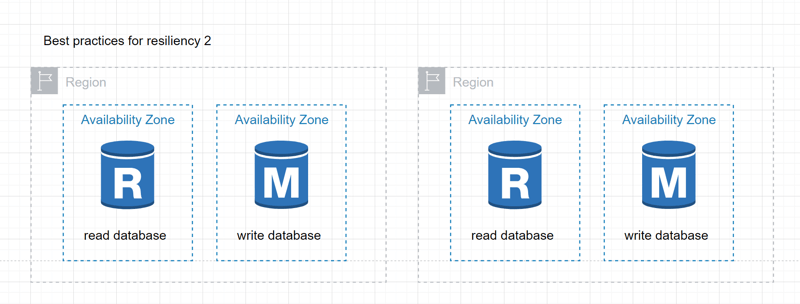
Configure a Multi-AZ setup with a writer and a read replica in two different regions:
- RDS automatically performs failover to the standby database instance.
- The endpoint for your database instance remains the same after a failover.
3
Implement a strong identity foundation:
- Enforce the principle of least privilege and separate duties to enhance security.
4
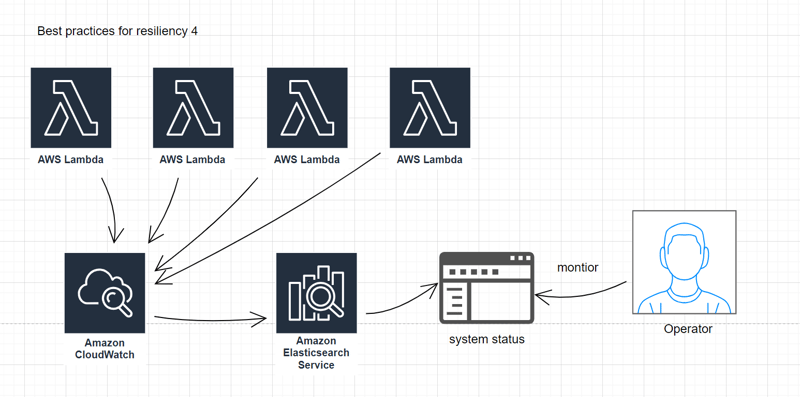
Ensure traceability through logging and monitoring activities.
5
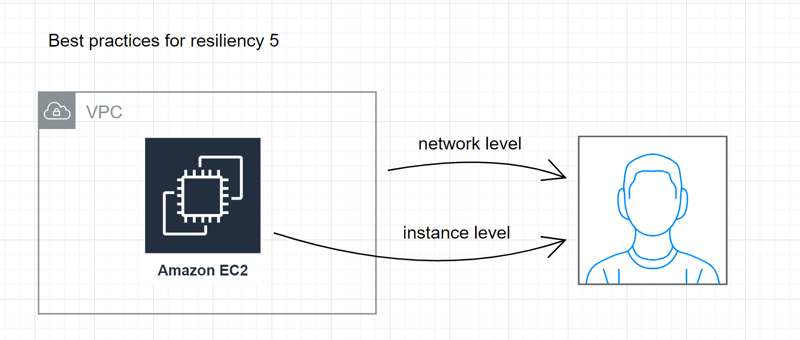
Apply security measures at all layers of the system.
6
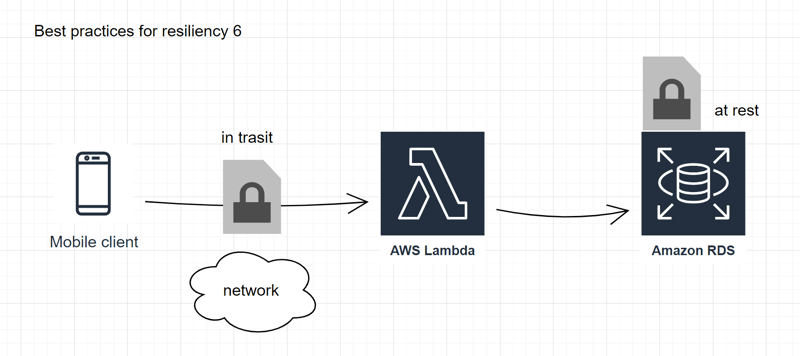
Protect data during transit and at rest:
- Utilize encryption techniques to secure data while it is being transmitted and when it is at rest.
7
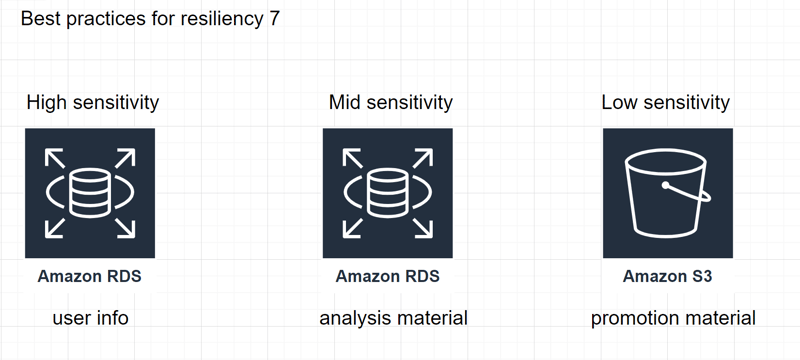
Classify and prioritize data based on sensitivity for appropriate security measures.
What are Static stability patterns?
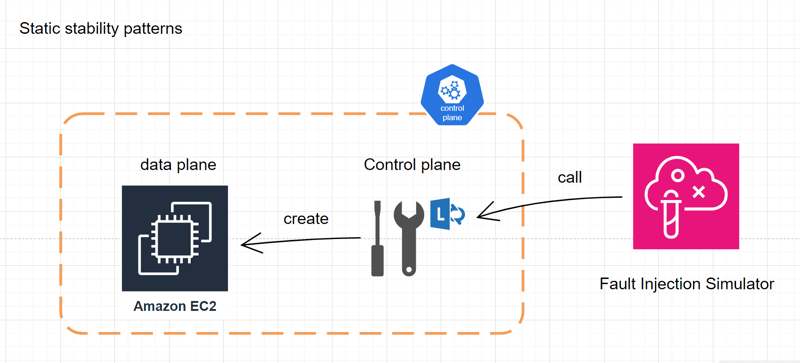
Data plane:
Refers to the physical servers where customers' Amazon EC2 instances run.
Example:
- Reading, and writing to an EBS volume,
- Getting, and putting objects in an S3 bucket
- Route 53 answering DNS queries
Control plane:
The control plane consists of various services that interact with the data plane.
Examples
- Providing administrative APIs used for resource management (create, read, update, delete).
Why is it needed?
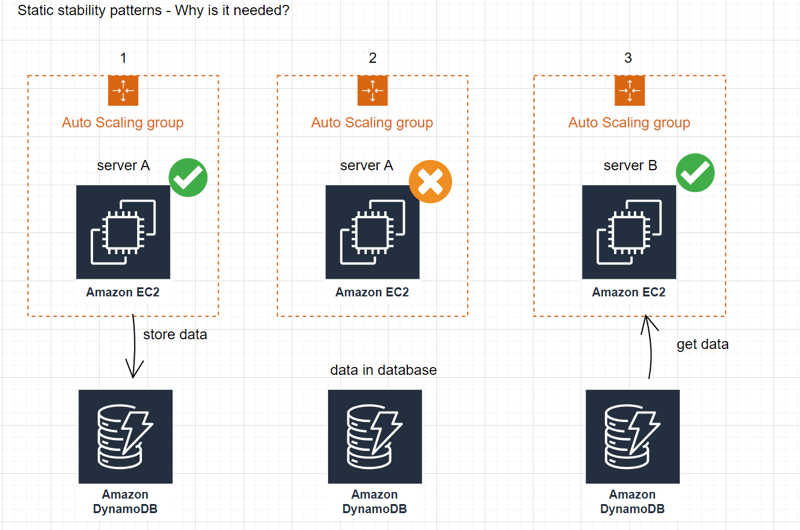
- Static stability is crucial for stateless applications with auto-scaling capabilities.
- Deploying a stateless application allows for easy addition or removal of compute nodes using auto-scaling, ensuring scalability.
- Without static stability, launching new EC2 instances may not be possible.
- The system relies on the Amazon EC2 control plane for the recovery path, which includes tasks like downloading runtime configuration, registering instances with discovery services, and acquiring credentials.
How to apply Static stability patterns?
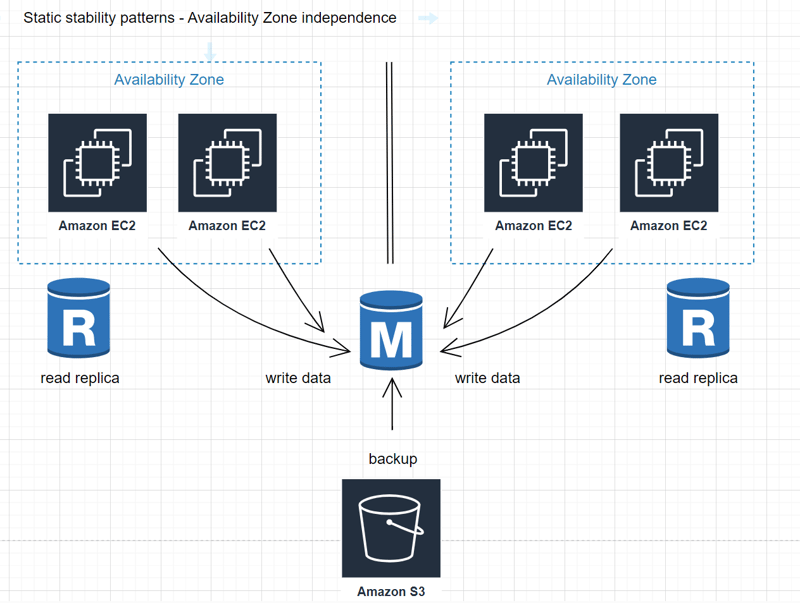
- Aim for Availability Zone independence by keeping packet flows within the same Availability Zone instead of crossing boundaries.
- Keep network traffic local to the specific Availability Zone.
- In case of a connectivity impairment in one Availability Zone, contain the impairment within that zone.
Extra work for Static stability patterns:
- Replicate any hard state across multiple Availability Zones for disaster recovery.
- Store periodic database backups in Amazon S3 and maintain read replicas across Availability Zone boundaries.
Trade-offs:
- Additional complexity may increase costs.
- Data durability should be considered when evaluating the trade-offs.
Advanced Architecture for resilient
Active-active on Availability Zones:
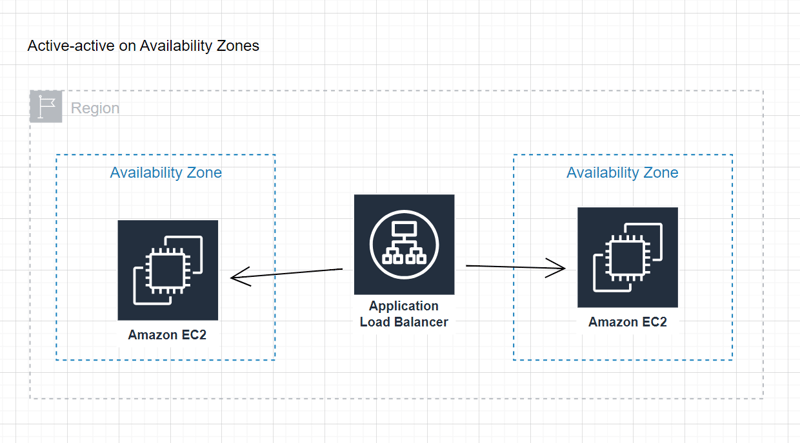
- Refers to a load-balanced service that operates simultaneously across multiple Availability Zones.
- Benefit: Ensures continuous service availability without downtime.
- Tradeoff: This can be costly to implement.
Active-standby on Availability Zones:
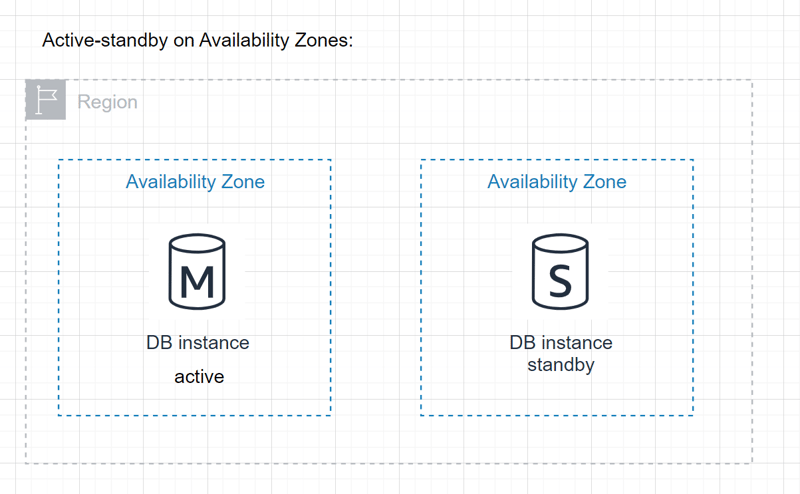
- Involves setting up a relational database with an active instance in one Availability Zone and a standby instance in another.
- Benefit: Provides an affordable solution.
- Tradeoff: May experience downtime during failover as the standby instance needs to scale up to handle the traffic.
Regional-calls-regional:
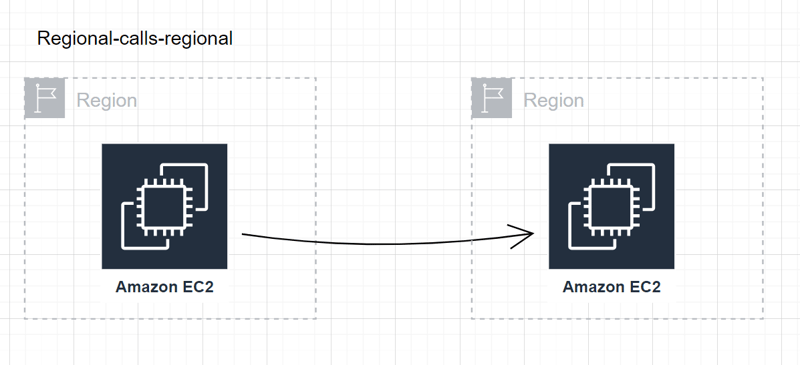
- Use case: External-facing services that operate within the same region.
Regional-calls-zonal and zonal-calls-zonal:
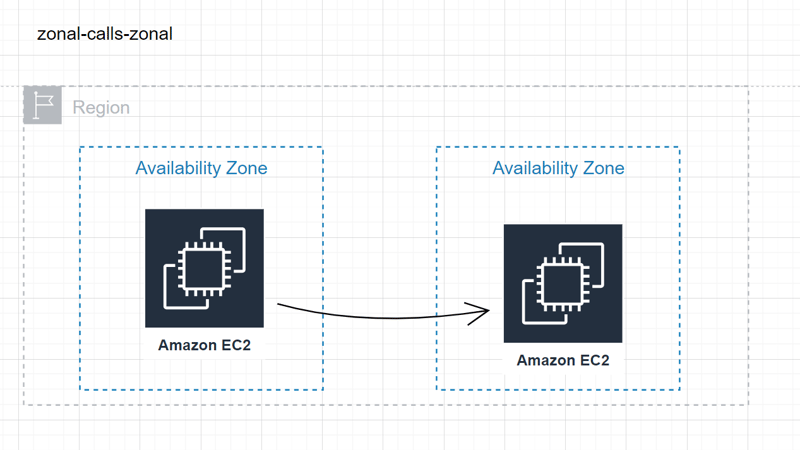
- Use case: Ensures network traffic remains within the same Availability Zone.
- Use case: Helps isolate impairments to specific Availability Zones.
Multi-AZ with static stability:
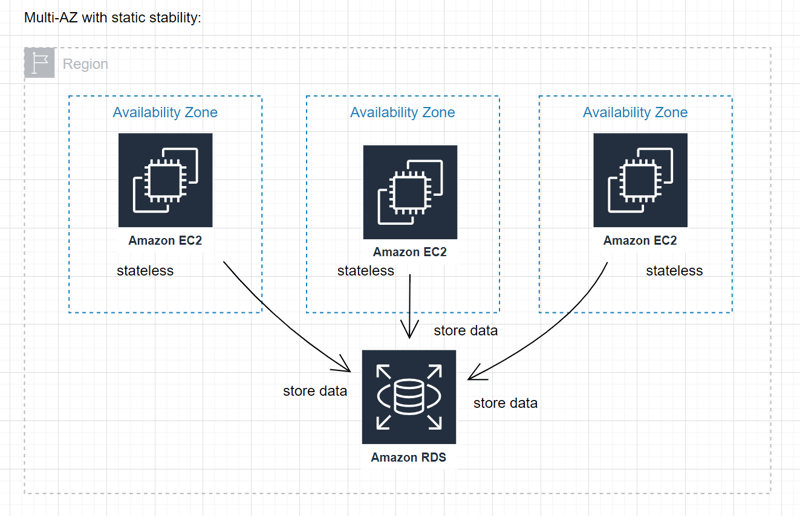
- If your workload is distributed across multiple instances, deploy it to all available AZs (typically 3 or more) within the region.
- Ensures static stability and resiliency.
Application portfolio distribution:
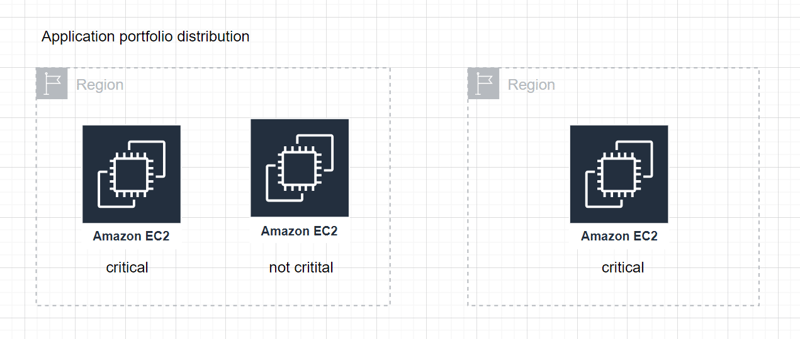
- Distribute critical services across different regions to maintain access during disruptions.
Trade-offs:
- Requires significant operational planning when spanning multiple regions. Functional elements may depend on downstream systems and data sources that are deployed in a single region.
Multi-AZ deployment (multi-Region DR):
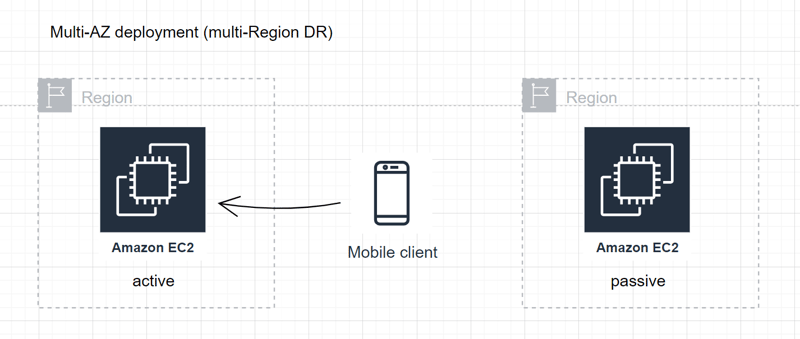
- Includes options like Pilot Light and Warm Standby for disaster recovery across multiple regions.
Multi-Region active-active:
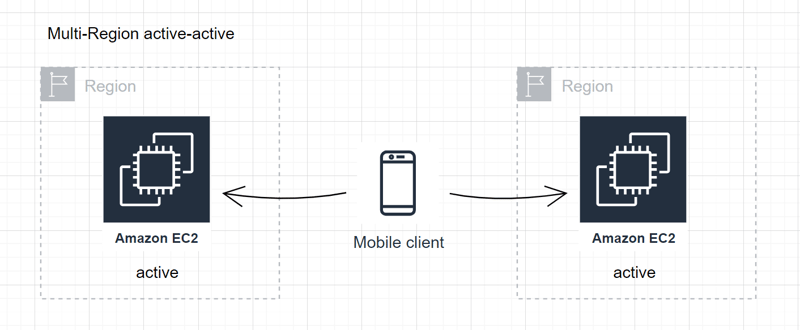
- Enabling active-active architecture across multiple regions for enhanced resiliency and redundancy.
Reference
REL11-BP05 Use static stability to prevent bimodal behavior
Building Resilient Applications in the Cloud
Introduction to AWS Resilience Hub
Understand resiliency patterns and trade-offs to architect efficiently in the cloud
Validating and Improving the RTO and RPO Using AWS Resilience Hub
Establishing RPO and RTO Targets for Cloud Applications
How to use the AWS Resilience Hub score
Build a resilience reporting dashboard with AWS Resilience Hub and Amazon QuickSight
Cyber resilience in applications on AWS-Using AWS Security Hub
Enabling resiliency for a static website hosted on AWS Cloud
AWS Multi-Region Fundamentals - WhitePaper Summary
Resilience lifecycle framework
Testing for resilience with AWS Fault Injection Simulator - DOP318
Comprehensive guide to deploying business applications with Amazon EBS
Posted on January 20, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related