Hosting Hugging Face Models on Amazon SageMaker

Alex Bzdel
Posted on February 22, 2024

This tutorial goes more in depth in the associated GitHub repo. Here, you can also find the accompanying files if you'd like to reproduce the project yourself. This post also assumes you're comfortable authenticating via the AWS CLI. If you'd like a walkthrough of this, definitely check out the repo linked above!
Welcome to the comprehensive guide on hosting your own inference environment for Hugging Face models using Amazon SageMaker!
For our application, we'll be hosting our own instance of GPT2 for text generation!
Why SageMaker? Why Hugging Face?
SageMaker offers managed solutions for the entire machine learning lifecycle. It provides a hassle-free environment to deploy, manage, and scale your models. If you're looking for ways to get your models into production without needing to worry too much about the underlying complexities of model hosting, SageMaker is your tool.
As for Hugging Face - you and I don't have millions of dollars to throw at training advanced neural networks (at least not yet 😉) with billions of parameters. Luckily for us, Hugging Face has changed the game and allowed users to host their own custom models that we can download, fine-tune, and host either in-house in Hugging Face Spaces or seamlessly transfer over to AWS. Hugging Face allows mass availability of open-source models designed with the most cutting-edge methods. I believe expertise around using pre-trained models will grow in demand for MLOps practitioners in the near future, as it's simply too efficient and cost-effective to ignore.
What you'll Learn
- Setting up an Amazon SageMaker instance
- Preparing your Hugging Face model for deployment
- Deploying your model on SageMaker with ease
- Accessing your deployed model
Prerequisites
Before getting started, ensure you have:
- An AWS Account
- A trained Hugging Face model you'd like to host
- Basic knowledge of Python and Linux
- Basic knowledge of AWS services (specifically SageMaker) will be helpful but not required
Step 1: Authentication
For our purposes, we authenticate with an IAM User (for our local environment) and an IAM Role (for our Python deployment file). If you'd like a walkthrough of this step, check out the more detailed instructions in the GitHub repo.
Step 2: Setting up Deployment Steps
Choose the Hugging Face model you'd like to be hosted. For this project, we'll host our own version of DistilGPT2
I've split up this process into two files. To get access to these, I suggest cloning the associated GitHub repo. I've made the following changes to the default py deployment file you can find on Hugging Face:
- host.py
- changed the top few lines to load in Role from environment variable
- added some print statements
- removed model querying - this notebook should only deploy the model to SageMaker
- query.py
- this takes command line input that will be passed to our model
- we're using a text generation model, so this will tell the model what to generate
I recommend using these two python files, but if you'd like to create your own you can find the boilerplate on your model's hugging face page:
On the right side of the page, look for Deploy->Amazon SageMaker
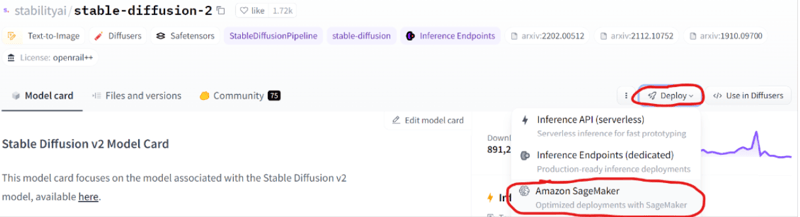
From here, you can copy and paste the python code into your own file and make changes as you see fit.
Step 3: Host your model
Now comes the fun part. Run
python host.py
This will take a few minutes - this is the step that deploys your model to SageMaker for inference.

Step 4: Query your model
You may need to open query.py and change endpoint_name to your model endpoint's name. To find this, go to your AWS Management Console and head over to SageMaker. On the left side, look for Inference->Endpoints, and copy the name of the endpoint you just created via the host.py script.
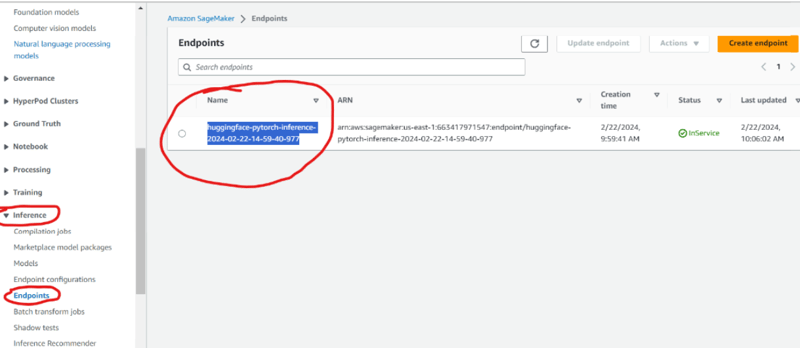
Then, run query.py and see your deployed text generation model in action:

As can be seen, the output is truncated due to model constraints, and it doesn't give an output we'd consider ideal given out input. This is a drawback of using a smaller model. For larger models, we'd either have to increase the instance size, or look to another inference solution altogether.
Step 5: IMPORTANT!! Delete your resources!
Once you're done using your model, you don't want to be billed for the idle resources. Navigate to SageMaker on the AWS Management Console and scroll down the left hand side until you find "inference". The Model, Endpoint, and Endpoint Configuration should all be deleted.
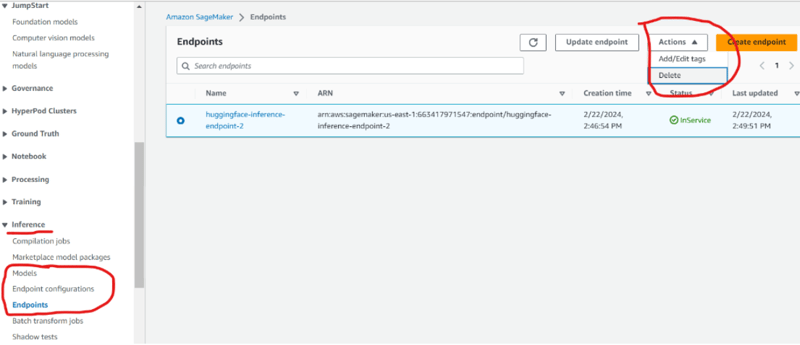
Fortunately, the python files in this project lend themselves to high reproducibility, and this solution can be spun-up again in minutes.
Posted on February 22, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related