Do You Have a Look-alike?

Amit Kayal
Posted on March 6, 2021
DoppelGanger tool
This project aims to find a doppelganger or look-alike to a given person within a celebrity dataset.
The repo after unzipping the data.zip should be organized as follow:
DoppelGanger
├── DoppelGanger.ipnyb
├── README.md
└── data
├── celeb_mapping.npy
├── encoding_celeb_mini.dat
└── images
└── celeb_mini
│ ├── n00000001
│ │ └── *.JPEG
│ ├── n00000003
│ │ └── *.JPEG
│ ├── ...
└── test-images
└── *.jpg
What are Embeddings
To identify a human face, we need to identify the specific facial features. Examples would be the length of our nose, the distance between our eyes, the angle between nose and mouth, …
We humans have perfected recognizing this features and can identify subconsciously millions of them. However, to program that by hand would be impossible. Therefore, we are using cv2.dnn.blobFromImage network to find a good representation of those facial features and its combinations and project them into a lower dimensional space. This lower dimensional space which incorporates the high dimensional space of the facial feature information is called embedding.
How a Face Recognition System works?
Here is a sample implementation architecture which helps to identify face. So, we need a FaceDatabase which is nothing but Face Descriptors.

It is always essential for us to have frontal face detection to ensure that we get face feature descriptors properly.
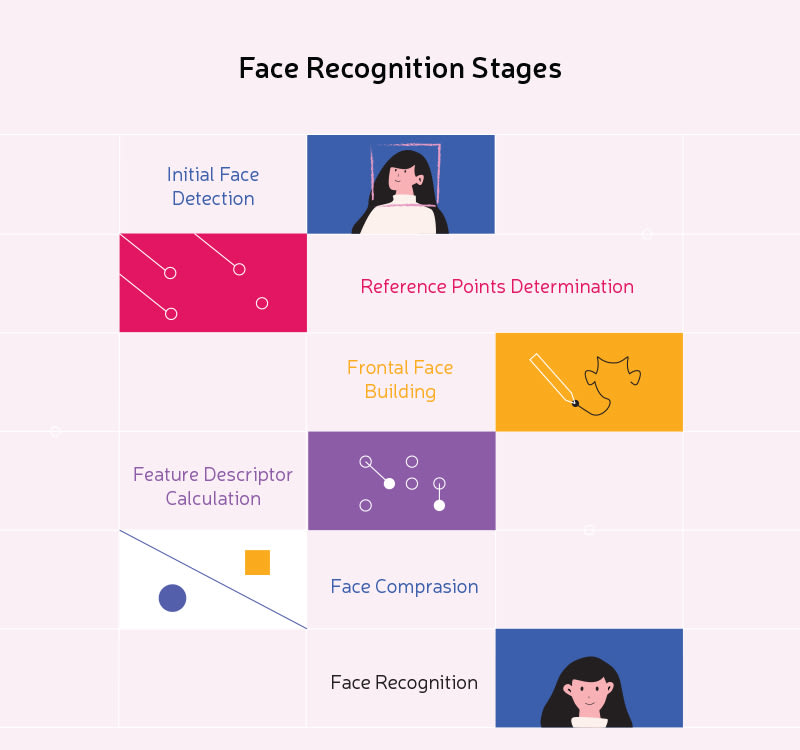
How dlib face deetction does it work?
Our face has several features that can be identified, like our eyes, mouth, nose, etc. When we use DLib algorithms to detect these features we actually get a map of points that surround each feature. This map composed of 67 points (called landmark points) can identify the following features:
- Jaw Points = 0–16
- Right Brow Points = 17–21
- Left Brow Points = 22–26
- Nose Points = 27–35
- Right Eye Points = 36–41
- Left Eye Points = 42–47
- Mouth Points = 48–60
- Lips Points = 61–67

Face Compare Application
Enrolment/Encode the known faces
This sections will load all the test images and Persons’ images that are stored in DATA_PATH/images/faces folder will have subfolders. Each subfolder has images of one person. We will store this mapping of images and their corresponding labels to use it later in testing.
High level steps for enrolment are:
- data is organized assuming following structure
- faces folder has subfolders.
- each subfolder has images of a person
- read subfolders in folder "faces"
- We, then define a dictionary named labels which will contain integer labels for corresponding image in imagePaths as shared in sample output below. So key here is the image path and value is the celebrity name indicator or the subfolder name.
dict_keys(['/content/celeb_mini/n00001446/n00001446_00000913.JPEG', '/content/celeb_mini/n00000739/n00000739_00000390.JPEG', '/content/celeb_mini/n00000739/n00000739_00000579.JPEG', '/content/celeb_mini/n00000739/n00000739_00000522.JPEG', '/content/celeb_mini/n00000739/n00000739_00000847.JPEG', '/content/celeb_mini/n00000739/n00000739_00000514.JPEG', '/content/celeb_mini/n00000163/n00000163_00000837.JPEG', '/content/celeb_mini/n00000611/n00000611_00000028.JPEG', '/content/celeb_mini/n00000611/n00000611_00000025.JPEG', '/content/celeb_mini/n00001020/n00001020_00000076.JPEG', '/content/celeb_mini/n00001020/n00001020_00000083.JPEG'])
-
After this the face descriptor generation process kicks off (we have assumed here each image has one face only which may not be valid sometime)
- Process enrollment images one by and one.
- Convert image from RGB to BGR, because Dlib uses BGR as default format.
- Detect faces in the image. For each face we will compute a face descriptor.
- For each face get facial landmarks.
- Compute face descriptor using facial landmarks. This is a 128 dimensional vector which represents a face. We will convert face descriptor from Dlib’s format to a NumPy array for ease of mathematical computations and read/write on disk.
- For each face descriptor we will also save the corresponding label. Order of face descriptor for each face in faceDescriptors NumPy array’s rows is same as the order of labels in variable index
- So now we have label and its corresponding face descriptors. Now save descriptors and the descriptor-label mapping to disk.
- A face descriptor same value will be as shared below.
array([-0.12628451, 0.1418225 , 0.12840877, -0.08114216, -0.15471405,
-0.0478919 , -0.02732727, -0.13895543, 0.14248449, -0.06592183,
0.17603964, -0.07321192, -0.2755293 , -0.03996106, -0.02778118,
0.15708025, -0.18403991, -0.20414677, -0.04625163, 0.00582148,
0.00072036, 0.04701969, 0.05542792, 0.09160887, -0.10294718,
-0.32763368, -0.07201297, -0.01759379, 0.01539746, -0.11150647,
-0.06122024, 0.07024163, -0.26702914, -0.05566515, 0.0628224 ,
0.25546333, -0.12654914, -0.14244375, 0.22005849, 0.0302763 ,
-0.17283939, -0.06293783, 0.10661078, 0.27153793, 0.28196251,
-0.03696643, -0.03208613, -0.07497264, 0.12953417, -0.32792288,
0.08953883, 0.20995598, 0.07063661, 0.1470409 , 0.02476202,
-0.19132754, 0.02425877, 0.13574196, -0.24825127, 0.01421646,
0.09448326, -0.16684172, -0.01213282, -0.09918778, 0.26380458,
0.14026739, -0.12445666, -0.16065101, 0.20945829, -0.17040111,
-0.03908831, 0.0788178 , -0.11134427, -0.11543901, -0.25824887,
0.01017199, 0.39593434, 0.10053834, -0.12500034, 0.02014588,
-0.1384005 , -0.10397173, -0.10062244, 0.09627406, 0.00835954,
0.00835303, -0.12891442, 0.07478838, 0.21302247, -0.03757607,
0.02387221, 0.2324305 , 0.01796461, 0.00087321, 0.08747191,
0.03362498, -0.12506446, -0.02355893, -0.20592356, -0.02991434,
-0.12417389, -0.15015683, -0.02568636, 0.10652462, -0.16659626,
0.16554774, 0.04287212, -0.06953543, -0.06864648, -0.13304259,
-0.11927435, -0.05156082, 0.1704922 , -0.32410818, 0.24830483,
0.11175595, 0.05624811, 0.18281324, 0.01676171, 0.13893685,
0.01264865, -0.07391733, -0.0738699 , -0.06425698, 0.01094038,
0.00706462, 0.05539028, 0.09609816])
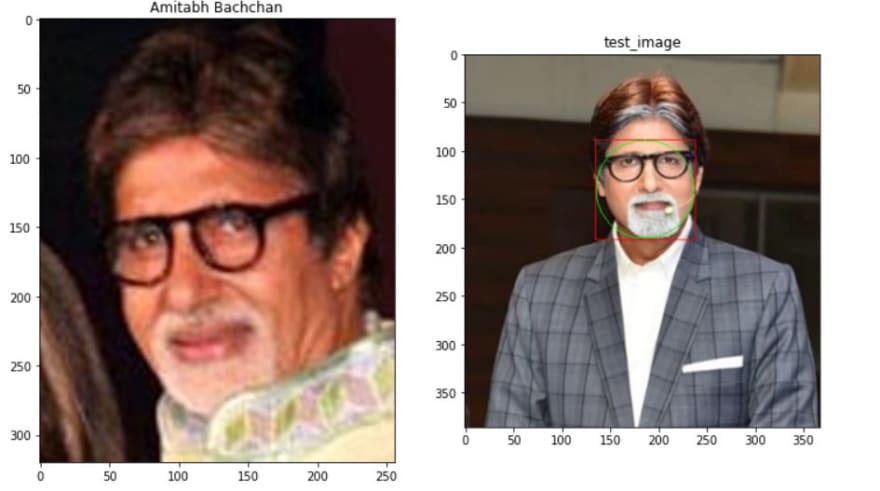
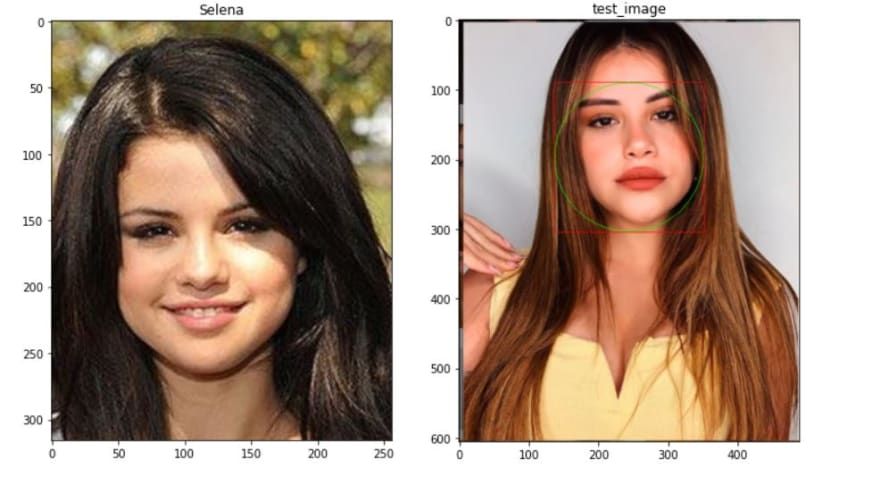
Compute and compare the similarities for Test Image
Once we have the encodings of our dataset, the goal is to compute the similarities between the encoding of a given image and the known encodings. The doppelganger or looka-like celebrity will then be the one with the more similarities.
Primarily dlib has been used here for face detection and shape detection. Dlib is a modern C++ toolkit containing machine learning algorithms and tools for creating complex software in C++ to solve real world problems. It is used in both industry and academia in a wide range of domains including robotics, embedded devices, mobile phones, and large high performance computing environments.
Key points are:
- dlib.shape_predictor uses “shape_predictor_68_face_landmarks.dat” file
- This model file is designed for use with dlib's HOG face detector. That is, it expects the bounding boxes from the face detector to be aligned a certain way, the way dlib's HOG face detector does it. It won't work as well when used with a face detector that produces differently aligned boxes, such as the CNN based mmod_human_face_detector.dat face detector.
- dlib.face_recognition_model_v1 uses “dlib_face_recognition_resnet_model_v1.dat”
- This model is a ResNet network with 29 conv layers. It's essentially a version of the ResNet-34 network from the paper Deep Residual Learning for Image Recognition by He, Zhang, Ren, and Sun with a few layers removed and the number of filters per layer reduced by half.
- The network was trained from scratch on a dataset of about 3 million faces.
- The DLib function
get_frontal_face_detector()will return adetectorthat is a function we can use to retrieve the faces information. Each face is an object that contains the points where the image can be found. - The DLib offers a function called
shape_predictor()that will help in identifying face features but with a caveat, it needs a pre-trained model to work and that’s why we are using dlib_face_recognition_resnet_model_v1.dat
PREDICTOR_PATH = DATA_PATH + 'shape_predictor_68_face_landmarks.dat'
FACE_RECOGNITION_MODEL_PATH = DATA_PATH + 'dlib_face_recognition_resnet_model_v1.dat'
# landmarkDetector = dlib.shape_predictor(PREDICTOR_PATH)
# Initialize face detector,
# facial landmarks detector and face recognizer
faceDetector = dlib.get_frontal_face_detector()
shapePredictor = dlib.shape_predictor(PREDICTOR_PATH)
faceRecognizer = dlib.face_recognition_model_v1(FACE_RECOGNITION_MODEL_PATH)
High level steps will be
- Initialize Dlib’s Face Detector, Facial Landmark Detector and Face Recognition neural network objects
- Read the query image and convert it from BGR to RGB. Because Dlib uses RGB as default format.
- Detect faces in query image. For each face detect facial landmarks.
- For each face computer face descriptor using facial landmarks. Convert descriptor to a NumPy array.
- Calculate Euclidean distance between face descriptors in query images versus face descriptors of enrolled images. Find the enrolled face for which distance is minimum.
- Dlib specifies that in general, if two face descriptor vectors have a Euclidean distance between them less than 0.6 then they are from the same person, otherwise they are from different people.
- If minimum distance if less than threshold, find the name of person from index, else the person in query image is unknown.
Compute and compare the similarities for Test Image
Posted on March 6, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


