How Avo Does Tracking Plans: We Pull Back the Curtain

Avo
Posted on March 23, 2021

OK, we’re going to get a little (or a lot) meta with this one. We’re going to pull the curtain back and tear down how we do tracking plans.We help you create great tracking plans, but our own process around them is a healthy mix of best practices and practical improvisation.
But before we dive in, let’s a look at the tour de tracking plans we’ve rolled out in the last month.
Hint: If you’re new to tracking plans, we recommend checking out our foundational pieces and then coming back to this article.
So far, we’ve looked at:
- Why tracking plans are important (Who can forget the Bad Data Day?)
- Who should be involved in tracking plan dev
- A worksheet on tracking plans
- Essential tracking plan events and properties
- The official Avo template for tracking plans
- A roundup of our favorite tracking plan templates
You ready? Let’s get started: Here’s how we (ideally) create Avo’s tracking plans.
Full disclaimer: We don’t always practice what we preach, and, truthfully, there are times that you shouldn’t either. As the old adage goes, you have to know the rules in order to break them (and anticipate the impact of doing so). Once you dial in the practices that we outline below, you can start bending the rules a bit to find the right mix to create the best data possible for your use case.
We kick off with a purpose meeting
Pre-release purpose meetings ensure that everyone’s on the same page. They’re kind of like meal planning for your data. Imagine trying to plan dinner with a group when nobody can agree on an entrée. If you just wing it, you end up with duplicate dishes, too much of one ingredient, or too little of another.
But if you consider these 30-minute meetings your chance to meal prep, you can sort out all your priorities and needs to have a hearty data feast, with none of the drama.
Like all good recipes, these meetings come down to a few main ingredients. Each of which builds on the last.
Topics are the main course of your purpose meeting 🥘

The key to a successful purpose meeting lies in establishing the topic your meeting will be about. If you don’t have common topics identified for the team to focus on, you won’t have a foundation to build your goals and metrics on.
Instead, by defining topics early on, you anchor your purpose meeting behind a common vision.
Let’s look at, for instance, our purpose meeting for our Publishing functionality, which lets you configure Avo to automatically publish your tracking plan to your analytics platform of choice. When we did our initial purpose meeting for this feature, we established three topics:
- Making Publishing available to the public (it was previously behind a feature flag and wasn’t super easy to find)
- Making Publishing hackable (so that you could use webhook functionality to post to your own end point)
- Automating the publishing of tracking plan changes to integration so that your plan was updated via the merging of a new branch
Our three topics were the main dish of our tracking plan, which would be complemented by all future additions. After we set them, we were able to create context around our OKR of helping companies keep their ingestion time validation tool (e.g. Lexicon) up to date and drive more relevant goals later on.
Before you can get to your delicious data dessert (goals), you have to make it through your vegetables (problems).
Problems are your hearty side dishes 🥗

The second part of your purpose meeting should focus on identifying the problems that you and your product are solving for. After all, if the data you’re measuring isn’t focused on the challenges your users face it’s difficult to know whether or not you’re actually delivering value and making their lives easier.
To use our Publishing example, during our purpose meeting, we identified the following key problems our users faced with the existing integrations functionality:
- People forgot to manually publish existing functionality because it wasn’t automatic (this meant data was out of sync).
- People had a hard time finding the functionality because it wasn’t visible, and they had to manually request it from the Avo team.
- Tracking plans stayed stuck in Avo if customers weren’t using Segment, Amplitude, or Mixpanel.
Once we understood these three problems, we could start setting goals around what “success” looked like.
Now, after we’ve devoured your topics and wrestled with our problems, our team gets to tackle our favorite part of the data feast: dessert (aka goal-setting, for you less-food-minded folks).
Goals are your delicious data desserts 🍰

The goals we set during our purpose meetings help us define success throughout future iterations of our tracking plan. They’re unique to the features and product we’re working on and always map back to the problems we’re trying to solve.
Our goals are typically focused on how we can reduce friction to help customers better understand and leverage their event data. For our Publishing example, this translated to goals that looked like the following:
- Making Publishing discoverable and easy to set up
- Making Publishing feel safe and secure
- Ensuring that tracking plan dependencies were always up to date
- Allowing developers to build custom services on top of their tracking in Avo
After we identified these goals, we got to work on designing our data. We always recommend identifying metrics during those purpose meetings and even the events and properties needed to construct the metrics. This is where we sometimes break from our own sage wisdom. 🧙
We sometimes don’t go into metrics in this meeting and usually don’t get to the events; instead, our developers take the insights from our purpose meeting and collaborate to design data with data experts post-meeting (but pre-release). This approach lets us focus our purpose meetings on big-picture goal-setting (and helps our devs avoid sitting through meetings they don’t necessarily need to attend).
We design events for the start and end points of a user’s journey
To capture the entire user journey for our features, we start by identifying the first touchpoint a user will have with our feature, as well as their final “completed” action.
It’s tempting when tracking user actions to focus on the final conversion that shows you whether or not someone has successfully completed their journey. But this doesn’t give you all that much insight into everything that happened leading up to their conversion (or what happened to the folks that fell off before they finished).
Clearly identifying both the start and the finish of the user journey for each feature lets us compare how many folks entered from the front door, how many left through the back, and how many got stuck wandering in the UX house.
Instead of lumping events together, we focus on creating starts and ends of user actions so we frame the user journey and can get a clear picture of how folks move from point A to point B. This is especially important for flows like sign-ups, logins, games, and checkouts.
For example, in the case of the Publishing flow we outlined above, we could have just created an event for “integration published,” right? Well, yeah. But it doesn’t tell us how a user got there, or if folks might be dropping off. So, instead, we created two events that show us how the user is progressing: one for when they initially click “Add Integration” and one for when they hit “Publish to Lexicon/Govern/Protocols/Webhook” and get value out of the feature.
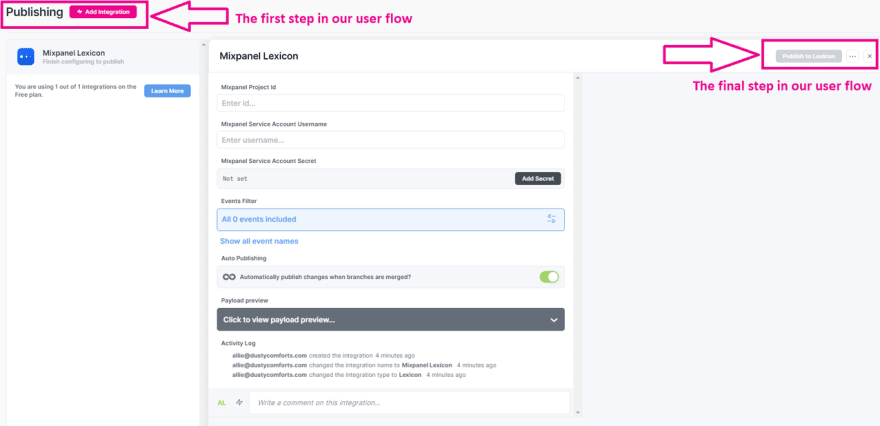
By clearly defining the start and the end of the user flow for our Publishing feature, we can begin to see how folks interact with our funnel, and how many are falling out of it in the process.
We fill out our user journey with the events and properties that matter most
Users do a lot in our product. They can create new tracking plans, change configurations, add comments to branches, change individual values. All are important for the user experience, but we don’t necessarily want to track all this data all the time. As we’ve said in the past, more data isn’t necessarily best.
Instead, each time we design data for a new tracking plan, we identify which user actions matter most in the user journey and then track those. The process of designing this data starts with the beginning and the end of the funnel, as we talked about above. Then, we walk through our feature as if we were using it and pinpoint which actions most impact our progress.
For instance, in our Publishing tracking plan, we knew that our users started their journey with the “Add Integration” tab and ended with the “Publish to Lexicon” button.
Between these two points, users entered a lot of information. They selected which integration type they were adding—Segment Protocols, Amplitude Taxonomy, Mixpanel Lexicon, or Webhooks—and gave the integration a name before hitting the “Create Integration” button. Now, while the Integration Type and name is important info for the functionality of the feature, which option they select doesn’t tell us they’re moving down their journey. So, we focused an event on the “Create Integration” action.

After they hit “Create Integration,” our users land on the main form, where they can enter their project ID, account username, account secret, and events filter. This is also the spot where they can toggle on or off the “Auto Publishing” feature that automatically pushes tracking plan updates whenever changes are made (pretty sweet, huh? 😉).
Again, while the information that users add is valuable, we don’t need to track every nuance. Instead, we focused on creating events on the “Auto Publishing” toggle and the final step, “Publish to Lexicon.”
This intentional event tracking doesn’t just make our data designing easier (in fact, it actually takes more forethought than just casting a wide data net). By limiting the events and properties we track to only those that most directly reflect our user journeys and goals, we avoid unnecessary data noise.
We build fat events
When we say we build “fat” events, we mean that we design events with a number of related properties that give deeper information about the action the user made.
Think of these fat events like a deep well: It’s really easy to pull water (insights) out of the well (data) because it’s all captured in one place, and you can dip your bucket (query) into the well and easily find what you need. The alternative to the data well is a shallow data pool, where the water is spread out over a mile of concrete but is only an inch deep. To get the same amount of water, you have to drag your bucket across the surface of it multiple times before you get what you need.
If we don’t build fat events, we have to do a lot of work to gather data from a bunch of different sources and collect it into something useful.
By building fat events, data teams can segment events based on properties to compare different flavors of the same user action, rather than having to pull together multiple events to analyze them. This allows teams to keep the number of events down to a manageable level, which makes it easier to find what they’re looking for and more easily onboard new data consumers to the existing analytics.
We also make sure to name these fat events in a way that is clear and communicates what product and funnel the event corresponds to (e.g., not just “source” or “plan” but “[Product] Plan” and “[Product] Source”).
In our Publishing tracking plan, an example of a fat event is our Integration Configured event, which, you guessed it, tells us when someone makes a change to their integration setup. Now, we could set up individual events for Integration Type Updated, Integration Name Updated, Downstream Project Name Updated, etc. But that would get messy, fast. Instead, we create one main fat event (Integration Configured) and then properties underneath it that capture all the kinds of types of integrations that you might update.

Fat events make it easy for us to see, at a glance, what kinds of actions are possible for integration configuration and keep the tracking of those changes easy to understand and analyze.
We (try to) avoid using Boolean properties
Boolean values are fundamental for functional programming, but they aren’t the best option for reflecting human behaviors (after all, people’s choices are rarely binary). We don’t simply log into an app or not.
For example, if your app uses only one authentication method (let’s say email, for instance) you don’t really need a property to track authentication method. But down the line you’ll probably want to add more methods, like Facebook or Google authentication. Bad Boolean practices would be to create a property for “Facebook” or “Is Facebook Authenticated,” as well as a property for “Is Google Authenticated.” All of which gets messy, and makes it difficult to compare how many authentications are happening via email, Google, or Facebook.
In short, we try to avoid using Boolean properties because they don’t scale as our products and features become more complex.
If we do use Booleans (or when we have in the past) our features and products quickly outgrow the data that our analytics can collect. This makes it difficult (read: nearly impossible) to compare data between eras of our product.
Using Boolean values for seemingly binary actions is a trap that so many early data teams often fall into. They start with exactly the use case being built right now. And then, later, they have to add a bunch more Boolean properties (or revamp their data design). It’s hard to segment on all the possibilities.
Instead, we design our data types for events and properties as strings or other more open-ended data types from the beginning so we’re not limited to whether a functionality is just “on” or “off.”
For instance, in our Publishing feature example, we have a property called Integration Stage. Now, there’s only two options—"Created" and "Published"—so we could just use a Boolean value. However, we know that down the road we’ll probably add more stages, such as "Published to Staging" or "Draft Stage" or something, and we don’t want to limit ourselves.
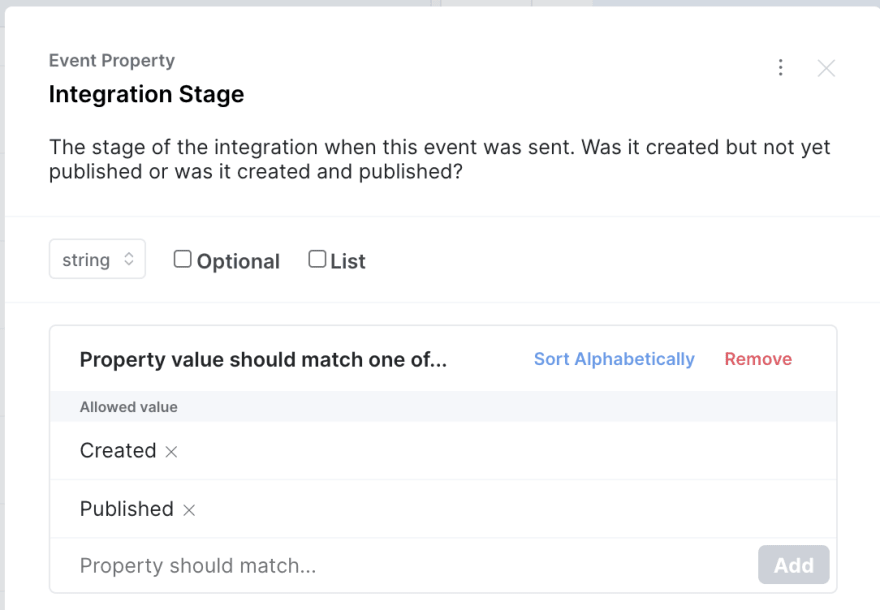
Boolean values might seem easier to implement at first, but you’re setting yourself up for heartbreak down the road.
We use constraints when defining properties
It’s not enough to say that you want to collect data from your users and your product. You need to explicitly outline for developers what kind of data you’ll accept (communicate your needs, basically).
If you don’t, you’ll end up with folks telling you that their age is 178,000 years, or that they live on Mars. Or you’ll end up with data that you can’t compare because you took in apples when you really needed oranges.
We use constraints when defining data values so that we have a contract about the kind of data we receive (and so that we know it’s useful). These constraints also help us ensure the data is consistent, so it can be compared and analyzed downstream.
In our Publishing tracking plan, for example, we have an event called Integration Configured with a property called Integration Item Type that tells us what part of the integration you’re interacting with. To ensure that these item types are correctly tracked by developers implemented, we explicitly outline the string values, and their formatting, that we’ll accept (e.g., Integration Type not integration type or integration typo).
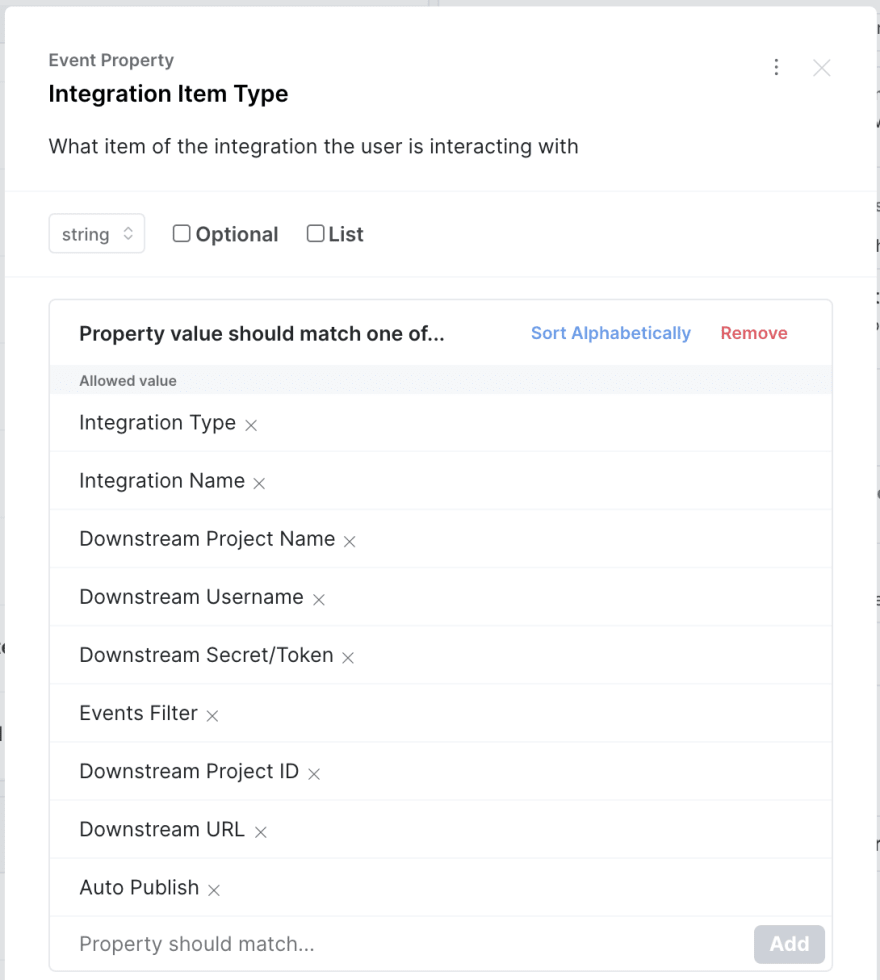
We do something similar for numerical values by setting a min of 0 to prevent erroneous negative values (or the 1,000-year-old vampire customer from signing up for a service).
It may take a while, but it does pay off to list all of the options a property can take if those options are finite (obviously, you can’t know every URL in existence, so some things should be left open).
We improve and revise our tracking plans when it makes sense
We’re always learning and improving. As a result, our tracking plans improve, too. We revise our tracking plans when product changes call for it or if we come into contact with out-of-date best practices.
If we don’t improve our best practices, we leave our old data and tracking plans frozen in time. This creates unnecessary confusion for whoever interacts with that old data (and more bad data as time goes on). Instead, when we come across an inconsistency that makes sense to correct, we update the tracking plan element so it’s more in line with our current best practices.
Tracking plans are a living document. If your data needs change or your product functionality shifts, it’s important that you have a system for documenting how your tracking plan evolves alongside it.
At Avo, we’re diligent notetakers. We maintain, as comments on our branches, a record of the changes (or change requests) that take place. This helps us understand how our plan evolved over time, or if certain parts of our tracking plan had to be sliced out in order to ship code on time (as was the case with some of our Publishing tracking plan).
Sometimes, after we launch a new feature, we discover that we need to add an event to better understand why our users are dropping off between the main user actions we’ve already identified, or we find that we need to add a new property to segment on a flavor of event we didn’t think of at the start.
For example, we recently started noticing that people were creating integrations, but not publishing them. We weren’t sure why that was, however, because we didn’t have events and properties that showed if they were trying to publish something, or just testing out the product. So, we added an “Integration Archived” event to see if folks were just creating events to archive them, or if they were getting stuck publishing.
However, while we’re all for a data ✨ glow-up ✨, it’s important to remember that data is permanent. We don’t want to change too much, because then we lose context by completing deleting those shallow events. Instead, we can preserve context and improve tracking by consolidating these shallow events into fat events.
We use Avo to help us build better, collaborative tracking plans

Collaborative data management at Avo is rooted in collaborating, in communicating, and in dogfooding our own product so that we can capture all of the ideas and expertise of our team and product design. This helps us avoid conflicts, keeps our plan up to date, and ensures that we design good data.
If we didn’t leverage Avo as a single source of data truth that’s directly connected to the implementation, our data experts, developers, and product managers would exist in silos. We’d run the risk of our tracking plan not being in sync with the implementation, constantly making changes to our source of truth that conflict with each other, and designing our data in an unideal way (because experts in different areas are not collaborating). Remember that imaginary dinner, where we didn’t plan what ingredients we needed? Now imagine we’re putting together a potluck, where everybody has to make their own dish, but nobody knows what anyone else is making, or even where the event is being held. That would just multiply the number of duplicate and downright disgusting dish combinations that made it to our table.
We avoid a similar data disaster by dogfooding Avo as our main source of data truth, which includes those in-app comments and suggestions between the team on different branches of our tracking plan we mentioned earlier. Rather than spending our time getting lost in our tracking plan (and finding our way out), we can focus conversation around the changes needed. This comment log and versioning is the functional group text that the disaster potluck needs.
Avo lets our developers flag data experts to review new features before merging changes with the main branch. All of this is coupled with Avo’s built-in branching mechanism that allows data teams to make changes to tracking safely in isolation without impacting the core source of truth for the worse.
If there’s one thing you take away from all of this, let it be this: communication is the key to collaborative success. Avo simply makes that communication much, much easier.
Be More Like Avo: Use Avo
As long as you’re generally adhering to these best practices—and using a tool like Avo to make following those rules easier—you, too, can have an efficient, collaborative tracking plan process.
Avo lets you combine all the data best practices we’ve outlined in our tracking plan series (and all the tips and tricks we’ve outlined right here) into one collaborative, single source of data truth.
Check out Avo today to level up your tracking plan and be more like Avo. (We promise, we’re pretty awesome.) 🥑
Posted on March 23, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related