
Austin Brown
Posted on July 19, 2020
In SQL and many other database programming languages, databases are set up in a specific way that is meant to minimize the amount of computing power needed to both update and make queries to the stored data. Because of this, some of the methods that they use may initially seem unintuitive to humans, but it makes a significant difference when dealing with databases that have hundreds of thousands of records in them and beyond. Inner join tables are a prime example of this and one of the first you may encounter when learning SQL.
Inner join tables are used by the computer to cross reference multiple categories (tables) of information to find information from one table that is associated with information from another table.
Imagine a scenario where a police department wants a list of everyone in a particular city that drives a certain type of car. Their database would likely have a massive amount of people to search through that is frequently changing, so a system that checked each person and each car one by one would take too long. Instead, they could set up a database that might have one table that holds addresses of people and a separate table that holds registered vehicles, each table with unique indexes that the data base can look up instantly when provided with said index. Making a query with an inner join table will return with records that have something in common between the two (or more) tables. Conceptually you could think of it like a Venn diagram.

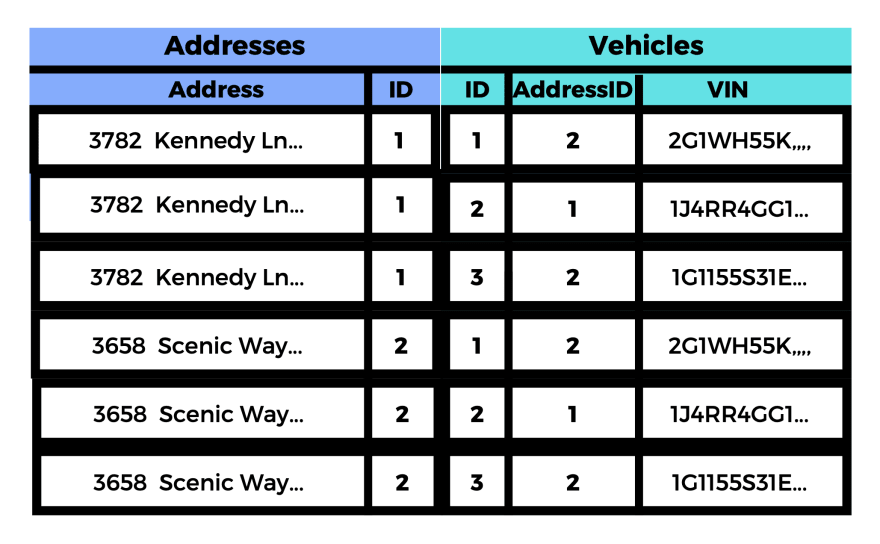
So far this should seem pretty straightforward, but it's the actual process of comparing these tables used by inner join that can seem confusing at first. First, let's consider this very small scale example below of an Addresses table consisting of 2 addresses and the Vehicles table consisting of 3 vehicles. Assuming that the vehicles table is referring to every individual registered vehicle, this would be considered a one-to-many relationship, since any given address can be associated with multiple different vehicles but a vehicle can only be registered to one address at a time.

If you are familiar with permutations, this next part should seem familiar as well. To form a join table, the computer essentially will take every row from both tables and temporarily form this table of every possible combination from the two tables. The total number of rows would equal the product of the total rows of the 2 being joined—thus it would have 6 rows. (2 x 3)
The code to actually create this table would look something like this:
SELECT * FROM addresses INNER JOIN vehicles;
However, since this table is not very useful as it is, instead you might have a command like this:
SELECT * FROM addresses INNER JOIN vehicles
ON addresses.id = vehicles.addressId;
By matching the Addresses IDs with the ON addresses.id = vehicles.addressId does is it filters out the paired rows that have completely irrelevant side by side information so that you will only see the relevant ones. So the addresses now have their associated vehicles next to them.
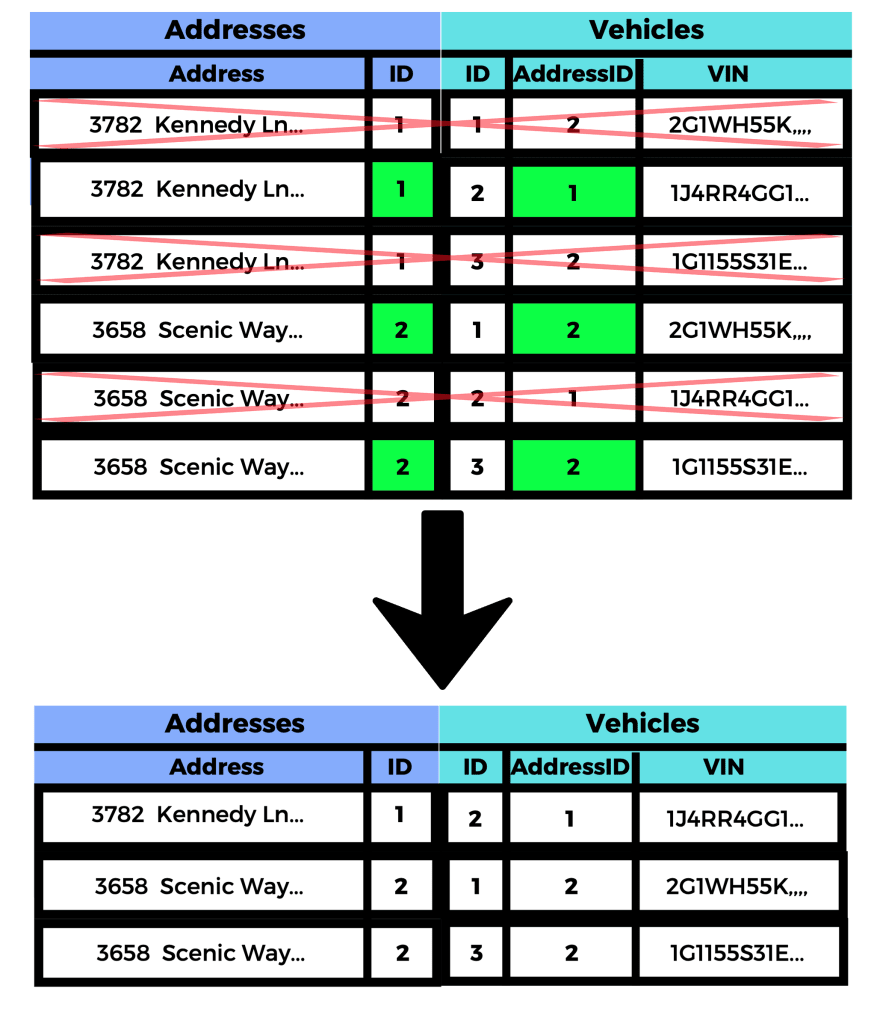
Now if you wanted to filter these results to just look at one address, you could just add on something like this:
SELECT * FROM addresses INNER JOIN vehicles
ON addresses.id = vehicles.addressId AND addresses.address = '3782 Kennedy Ln' ;
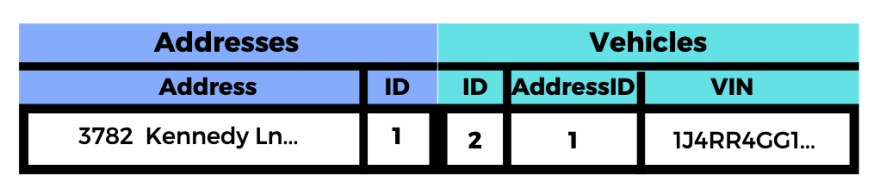
And voila! A successfully retrieved address with its associated vehicle.
Conclusion
There are many more types of tables not covered here such as outer joins, left inner joins and so on, but inner joins are the most common and a good entry point for understanding the basics. While it is not technically necessary to know how a join table actually works or the reason that they are set up the way they are to perform a query with one, it can definitely be helpful when working with large databases and is one hundred percent necessary for the creation of a database.
Posted on July 19, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


October 12, 2024