
Arpan Bandyopadhyay
Posted on June 7, 2022

Now a days all of our application is storing data for different purpose (it can be operational purpose , it can be analytics purpose) and data is evolving day by day and companies are growing by analyzing those data .
The Evolution Of Data Platforms:
It is important to understand the evolution of data platform within the enterprise.
- First Generation data platform – Data Warehouse
- Second Generation data platform – Data lakes
- Third Generation data platform – Batch and Streams
Let’s quickly understand what these three types of data generation platforms means :
1. Data Warehouse : It’s a centralized location where all data of enterprise company is stored. But before storing data into the Data warehouse we need to define the business requirement i.e. why we are going to store this data in to Data warehouse .
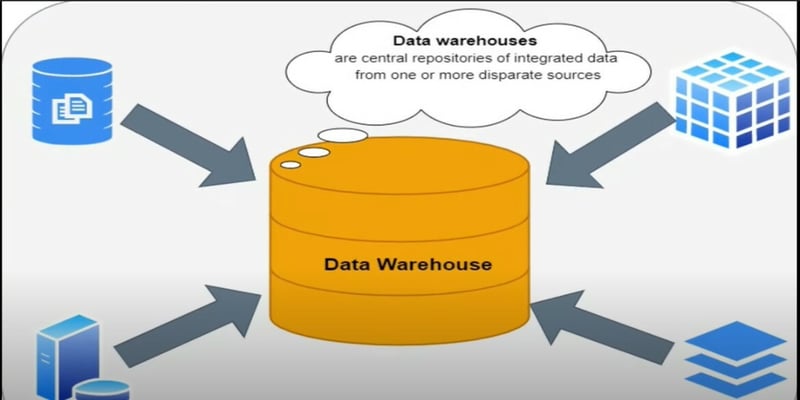
Here we need to extract data from different source system as per business need and using ETL pipeline we store all these data into Data Warehouse and now different consumers are now started consuming data from warehouse and perform their activities .
** An ETL pipeline is the set of processes used to move data from a source or multiple sources into a database such as a data warehouse.
Data warehouse is very successful, but it has some drawbacks :
• It can store only structured data
• It is very costly because lot of ETL pipeline need to be applied
• Technical expertise required
• We need to define business requirement first then set up Data warehouse and load data into it.
• As it is centralized the Data Platform team needs to have broad experience regarding the all domains and supports Consumers in term of domains Which is a bottleneck .
• Access control is implemented centrally.
2.Data lake :
Now a days with growing technology advancement , data volume is also increasing. Now every small system, application is generating data .It can be structured data , semi- structured data and unstructured data .Also every business/company wants all of these data as for them only operation data is not enough to grow . They want data to perform analysis so that they can grow and understand customer requirement in better way . Now we cant do all of these using Data warehouse as it supports only structured data and before storing data to Data Warehouse we need to define business requirement first .
Now Data lake tells : Load first , analysis later . means we will load all the data (structured, semi- structured and unstructured ) to a centralized space then we will analyze the data how to use it .
Now let’s think about a lake. There can be different source of water for a lake . It can be rainwater , It can be sea water , It can be River water etc etc.
Same way from different source system data can be stored in Data lake in raw format. Hence data lake acts as a central reservoir which stores all kind of data (it can be structured, semi- structured and unstructured, images , videos etc) without pre-analysis of data . Like lake water can be used for drinking purpose after purifying it , it can be used in industry and many other purpose , Once data is in data lake we can use in for multiple purpose as per business need.

But there are few drawbacks of data lake :
• We should be very careful while storing data to data lakes otherwise it will soon become data swamps
• It does not support ACID properties
• Very specialized skill set required to build and maintain data lake
• As it is centralized the Data Platform team needs to have broad experience regarding the all domains and supports Consumers in term of domains Which is a bottleneck .
• Access control is implemented centrally.
3.Batch & Streaming :
Data from multiple source systems(it can be structured, semi- structured and unstructured, images , videos etc) will be stored in to one centralized storage and then served those data to different consumers.
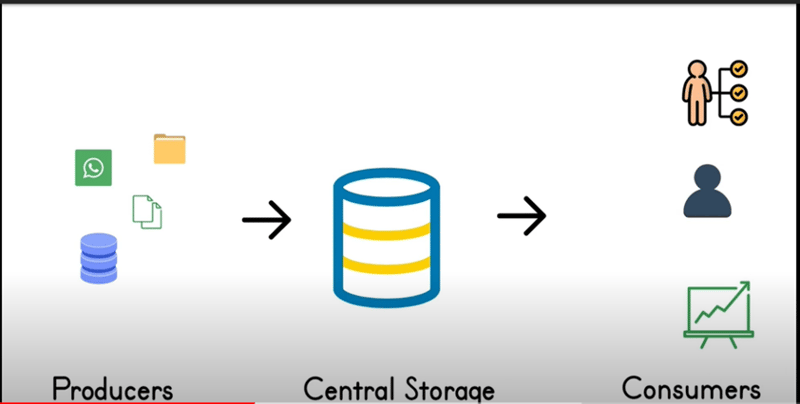
There are few disadvantages here:
• Huge time and effort needed to integrate new data source.
• Huge effort in specialized skill set to manage.
• As it is centralized the Data Platform team needs to have broad experience regarding the all domains and supports Consumers in term of domains Which is a bottleneck .
• Access control is implemented centrally.
Now to resolve all of these issues one new architecture came into the picture called Data Mesh .
What is Data mesh :
Data Mesh tells instead of flowing data from different domains and putting all these together into a centralized storage , we will divide in different domain .
Earlier it was centralized, and it has single ownership and control.

Now we have segregated data into different data domains and it’s not centralized . Access control is maintained by different data domain separately not in centralized way .

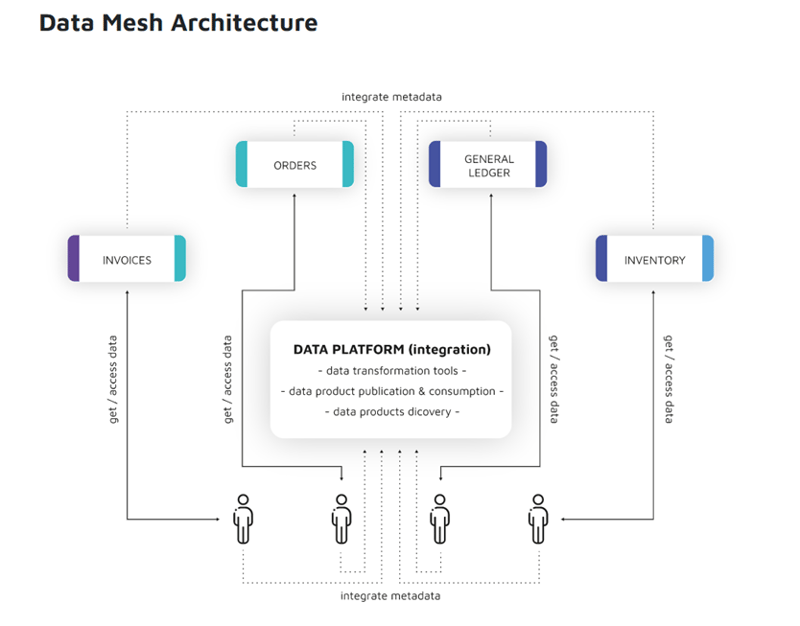
Below are the key characteristics of the Data Mesh architecture:
• Data Mesh is decentralized, so each domain has its own resources and implementation, they don’t influence each other.
• The Data Platform team doesn’t need to have broad experience regarding the domains but should be skilled in Software Development and Data Engineering (act also as support for the domain in terms of technical knowledge).
• Ownership is clear, Domain Teams are responsible to provide reliable data from the sources to consumers, with Platform Teams supporting the integration.
The idea of Data Mesh isn’t much different from a lot of current “Software as a Service” applications. It offers a service, like let’s say an online banking system. It helps to gather customers, online transactions, offer the different products, sell them .It’s done by the experts in all these domains, so other experts can focus on their products – improving them, adjust the offer to their customers’ needs.
Now a days we can see underlying database technologies , logics ,pipeline are evolving rapidly . They are also fragmenting continuously . we need a way so that our customers/analytics can access data easily because if we generate data and don’t use them it’s useless for business . Here we need one separate API layer which integrates Presentation layer with data layer .
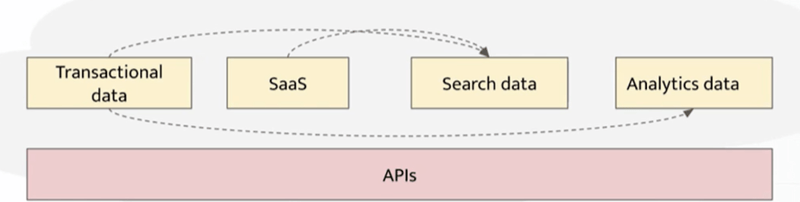
But before developing API layer we need to keep below points in our mind :
• API should be flexible that keeps up with data evolution .
• It should be secured.
• It should assure good performance.
GraphQL can help us on above aspects .
Now question is “Can GraphQL ships data faster to consumers?”
Ans is : Yes .
It is not like that we can’t achieve this with other technologies . There are no such technical constraints .
Here are some key benefits of GraphQL :
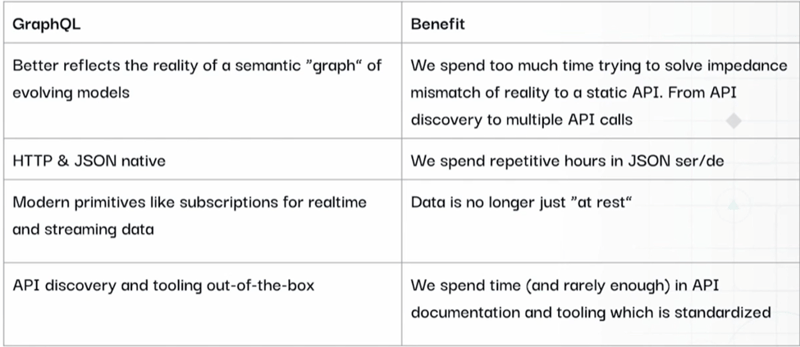
(Source: hasura.io/enterprisegraphql/build-a-graphql-powered-data-mesh-for-your-polyglot-data/)
What should be our API building strategy ?
- Domain Models : Which creates direct or indirect mapping with underlying data models
- We should query our required data based on business need .
- API should support streaming data.
- API should be secured :
- Row level security
- Column level security
- API documentation should be generated automatically without an extra effort .
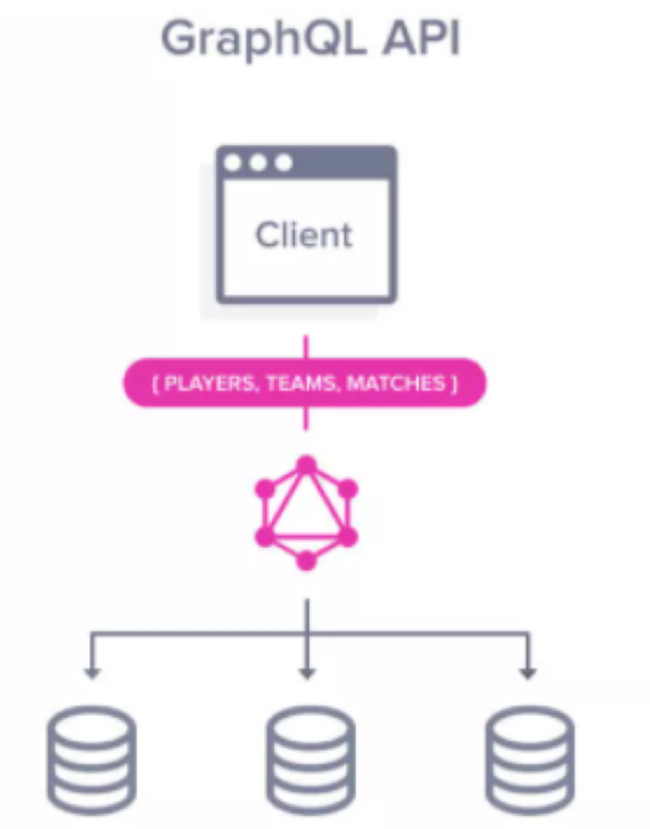
All of the above we can achieve using GraphQL .
• We can make use of Data virtualization tool like “Denodo” (which exposes its own GraphQL endpoint) to generate domain models with the help of meta data from underlying data models automatically .
• We can query data based on business need in GraphQL. We can ask only our required part of data not the whole data . It reduces network load.
• In GraphQL there is an operation called Subscription which helps to keep up with revolving the data.
• We can apply Row level and Column level security in GraphQL .
• API documentation can be generated automatically in GraphQL.
• We can apply aggregation of data in GraphQL easily which helps analytics to analyze data.
• All data/domain models from different source system are documented into one single document in GraphQL so that they are discoverable easily .
• Also consumer can fetch data easily based on their role from different domains using one single API call using GraphQL. No need to call multiple API calls to retrieve data from multiple data domains.
Thus GraphQL acts as an Unified API is an abstraction layer that easily handles communication with backend data models / data domains from different/ same data storage and supports Data Mesh architecture.
Let's connect:
LinkedIn : https://www.linkedin.com/in/arpan-bandyopadhyay-bb5b1a54/
** Image reference - internet
Posted on June 7, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related