SQL is 50 Years Old. What Can We Learn From Its Success?

Derek Xiao
Posted on January 18, 2021

Arctype writer: Felix Schildorfer
In March 1971, Intel introduced the world's first general microprocessor, the Intel 4004. It had ~2,300 transistors and cost $60.
Fast forward almost 50 years, and the newest iPhone has nearly 12 billion transistors (but unfortunately costs a little more than $60).
Many of the programming languages we use today were not introduced until the 90s (Java was introduced in 1996). However, there is one programming language that is still as popular today as it was when it was introduced nearly 50 years ago: SQL.
This article will discuss the events that led to the introduction of relational databases, why SQL grew in popularity, and what we can learn from its success.
Table of Contents
- A History of Early Database Management - IDS and CODASYL
- The Network Data Model - Better Than Today's Relational Model?
- Arrival of The Relational Model
- Relational vs. Network Data Models
- The Rise and Reign of SQL
- The Secret to SQL’s 50 Year Reign - And What We Can Learn
History of Early Database Management - IDS and CODASYL

In 1962, Charles W. Bachman (no relation to Erlich Bachman) was working as part of a small team at General Electric. One year later, Bachman’s team introduced what would later be recognized as the first database management system - the Integrated Data Store (IDS).
10 years later, Bachman would receive the coveted Turing Award, often called the Nobel Prize of computer science, for his contributions to computing with IDS.
What was IDS?
In the early 1960s, computer science was just beginning as an academic field. For context, ASCII was not introduced until 1963.
To understand IDS we have to first understand the two main forces that led to its development:
- The introduction of disk storage
- A migration to high-level programming languages
Disk storage

In 1956, IBM introduced the first commercial hard disk drive, the RAMAC 305%20system.).
The introduction of disk drives allowed programmers to retrieve and update data by jumping directly to a location on the disk. This was a vast improvement from its predecessor, tape drives, which required moving sequentially through the tape to retrieve a specific piece of data.
But developers now had to figure out where records were stored on the disk. Due to the limitations of file management systems in early operating systems, this was an advanced task reserved only for experienced programmers.
Developers needed a solution to simplify working with disk drives.
High-level programming
At the same time, computer science was beginning to move from innovators to early adopters on the adoption curve. Low level programming languages like Assembly were popular among the early academics, but regular programmers were switching to higher level programming languages like COBOL for their usability.
So what was IDS? IDS solved for disk storage and high-level programming. IDS allowed developers to use high-level programming languages, like COBOL, to build applications that input and retrieve data from disk storage. Because of this function, IDS has received the distinction as the first database management system.
CODASYL - A new standard for database management
In 1969, the Committee of Data Systems Languages (CODASYL) released a report proposing a standard for database management. Bachman was part of the committee, and the report drew heavily from IDS.
The CODASYL Data Model introduced many of the core features in database management systems that we use today:
- Schemas
- Data definition language (DDL)
- Data manipulation language (DML)
Most importantly, IDS and CODASYL introduced a new way for modeling data that influenced the eventual development of SQL - the network data model.
The Network Data Model - Better Than Todays Relational Model?
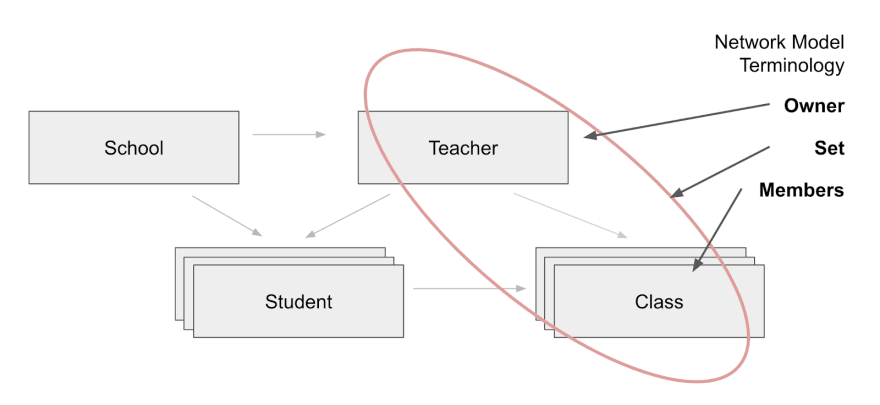
A data model is a standardized way to describe (model) the world (data).
The previous hierarchical data model used tree structures to describe data, but these were limited to one-to-many relationships. The new network model allow records to have multiple parents, which created a graph structure. By allowing multiple parents, network models were able to model many-to-one and many-to-many relationships.
In the network model, relationships between tables were stored in sets. Each set had an owner (i.e. teachers) and one or more members (i.e. classes and students).
One of the key benefits of the network model is that related records in a set were connected directly by pointers. Sets were implemented using next, prior, and owner pointers, which allowed for easy traversal similar to a linked list.
The low-level nature of network data models offered performance benefits, but they came at a cost. The network data model had increased storage costs because every record had to store extra pointers to its previous and parent record.
Arrival of The Relational Model
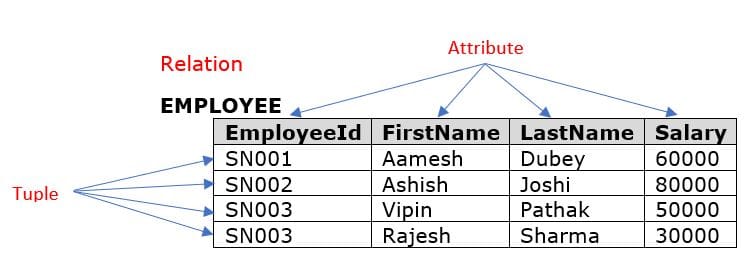
In 1970, 8 years afters IDS, Edgar F. Codd introduced the relational model in his seminal paper “A Relational Model of Data for Large Shared Data Banks” (also earning him a spot with Bachman as a Turing Award recipient).
Codd showed that all data in a database could be represented in terms of tuples (rows in SQL) grouped together into relations (tables in SQL). To describe the database queries, he invented a form of first-order predicate logic called tuple relational calculus.
Tuple relational calculus introduced a declarative language for querying data. Declarative programming languages allow programmers to say what they want to do without describing how to do it.
This new declarative language was much easier to use for developers. The relational model laid out all the data in the open. Developers could retrieve all the data from a table, or read a single row, in one command. (thanks query optimizer)
Gone were the days of following a labyrinth of pointers to find your data.
Relational vs Network Data Models
Relational databases decreased the high storage costs that network databases had by normalizing data. Normalization was a process of decomposing tables to eliminate redundancy, and thereby decrease the footprint of data on disk.
However, relational databases had an increased CPU cost. In order to process normalized data, relational databases had to load tables in memory and use compute power to “join” tables back together. Let’s walk through the process for finding all classes and students for a given teacher with a relational model.
The database system would first perform an operation to retrieve all relevant classes. Then it would perform a second operation to retrieve student data. All of this data would be stored in memory, and it would run a third operation to merge the data before returning the result.

In a performance case study using real data, Raima found that network database models had 23x better insert performance and 123x faster query performance.
So why are relational databases the leading database solution?
Usability.
The relational model was more flexible to changes, and its declarative syntax simplified the job for programmers.
And Moore’s law was working its magic in the background. The cost of computing continued to decrease, and eventually the increased computing cost of relational models was outweighed by the productivity gains.
Fast forward 50 years, and now the most expensive resource in a data center is the CPU. Sign up for Arctype and get notified of a future post where I discuss what databases might look like over the next 50 years.
The Rise and Reign of SQL

And finally, we've come to the arrival of the SQL that we all love.
4 years after the publication of Codd’s paper, Donald Chamberlin and Raymond Boyce published “SEQUEL: A Structured English Query Language”.
They described SEQUEL as “a set of simple operations on tabular structures, […] of equivalent power to the first order predicate calculus.” IBM saw the potential and moved quickly to develop the first version of SEQUEL as part of their System R project in the early 1970s.
The name would later change to SQL due to trademark issues with the UK-based Hawker Siddeley aircraft company.
The next big step in SQL's adoption was almost a decade later. In 1986, the American National Standards Institute (ANSI) and the International Organization for Standardization (ISO) published the first official SQL standard: SQL-86. The standard broke down SQL in several parts:
- Data Definition Language (DDL): commands to define and modify schemas and relations
- Data Manipulation Language (DML): commands to query, insert and delete information from a database
- Transaction Control: commands specifying the timing of transactions
- Integrity: commands to set constraints in the information in a database
- Views: commands to define Views
- Authorization: commands to specify user access
- Embedded SQL: commands that specify how to embed SQL in other languages
Competitors to SQL
Between 1974 to today there have been numerous competitors that have tried stealing market share from SQL’s dominance as a query language. These new syntaxes often catered to a specific, new technology:
- Lisp -> CLSQL
- .NET -> LINQ
- Ruby on Rails -> ActiveRecord
Fast forward 35 years and SQL is still ubiquitous with databases. How has SQL maintained its reign as a query language, and what can we learn from its story?
The Secret to SQLs 50 Year Reign - And What We Can Learn
We started this story with Bachman’s introduction of the first database management system, IDS. We talked about how the shift to disk storage and high-level programming necessitated a new way of working with data. Then CODASYL came and standardized database management. IDS and CODASYL introduced the new network data model, and finally Codd dropped the relational model.
This happened over eight years.
How did SQL manage to stick around for the next 50 years? I think these are the four main reasons:
- Built on first principles
- Bushnell’s law
- Listening and adapting
- Adoption of APIs
Built on First Principles
A first principle is a foundational proposition that can not be deduced from any other proposition or assumption. For instance, combining hydrocarbons with oxygen to create a chemical reaction. And this is still the principle that powers the internal combustion engines in every cars.
In 1970, Codd created a new first principle for databases: tuple relational calculus. This new logic created led to the relational model, which then led to SQL. Tuple relational calculus is the chemical reaction, relational models are the internal combustion engines, and SQL is the car.
In a later post, we’ll discuss new technologies that are trying to create the electric engine for databases.
Bushnell’s Law
Building on first principles alone can not guarantee success. Assembly is as close as programmers can get to typing 1s and 0s, but it was still replaced with COBOL (and later C).
The missing ingredient was usability.
We saw the same story play out with the switch from the network to relational model. The network model had faster performance, but every company today uses relational databases because of its simplicity (to get started).
"The best games are easy to learn but hard to master" - Nolan Bushnell, founder of Atari
Nolan Bushnell knew the secret to getting people to use a new product. Assembly unfortunately was both difficult to learn and difficult to master.
SQL found the perfect balance. With ~10 SQL commands, anyone can learn the 20% that will get you 80% of the way there. But there is a long path of indexing, views, and optimization to becoming a master.
Listening and Adapting
Query languages are not timeless monoliths but adaptive groups of standards that change over time. The SQL standard has continued to adapt over time and incorporate feedback from its users.
Since the original conception we have seen 10 different SQL standards all with important updates. Here were 3 big ones:
- SQL:1999: Added regular expression matching, recursive queries (e.g. transitive closure), triggers, support for procedural and control-of-flow statements, non-scalar types (arrays), and some object-oriented features (e.g. structured types). Support for embedding SQL in Java (SQL/OLB) and vice versa (SQL/JRT).
- SQL:2003: Introduced XML-related features (SQL/XML), window functions, standardized sequences, and columns with auto-generated values (including identity-columns).
- SQL:2016: Adds row pattern matching, polymorphic table functions, JSON.
SQL also demonstrates the power of creating rails that other products can build on. Instead of enforcing a syntax, SQL provides a standard for each database to create their own implementation (T-SQL, MySQL, PSQL, etc).
Adoption of APIs
The final secret behind SQL’s success has been the rise of application programming interfaces (API). APIs simplify programming by abstracting the underlying implementation and only exposing objects or actions the developer needs.
APIs allow SQL to continue to adapt to new technologies with specialized syntax. In 2006 Hadoop introduced the distributed file system (HDFS), which was initially inaccessible to the SQL syntax. Then in 2013 Apache created Apache Impala, which allowed developers to use SQL to query HDFS databases.
The Fascinating Story of SQL
SQL is one of the most ubiquitous programming languages today, but we often forget how long of a history it has had. Its journey started at the dawn of modern computing and was brought to life by 2 Turing award recipients.
I've shared my thoughts on why SQL has been able to maintain its dominance: first principles, Bushnell’s law, adapting, and APIs. Leave a comment and let me know what you think were the major factors that contributed to SQL’s success.
There is one more technology to talk about that hasn’t changed in 50 years.
SQL editors.
Working with databases is becoming an increasingly collaborative process as more people learn SQL. Developers today may be seen working with individuals on a marketing team to analyze user data, or debugging queries with a data scientist.
Arctype has built a collaborative SQL editor that allows you to easily share databases, queries, and dashboards with anyone. Join our growing community and try out Arctype today.
Posted on January 18, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related