Back to the roots: towards true Continuous Integration (part one)

Apiumhub
Posted on April 17, 2018
In this article, I would like to show you what many people believe CI is, what is true Continuous Integration, and what is not CI. Also, I will give you some examples to better understand it.
What is CI?
CI (Acronym for continuous integration) is a software development practice in which a continuous integration server polls a version control repository builds an artifact and validate the artifact with a set of defined tests. It is a common practice for most enterprises and individuals… and this is not the true Continuous Integration definition, sorry for the joke.
What is true Continuous integration?
Well, true Continuous Integration is not “simply” some kind of “Jenkins | Travis | Go | Teamcity” that polls the git repository of the project, compiles it and run a bunch of tests against the artifact. In fact, this is the less interesting part of CI which is not a technology (Jenkins) but an agile practice created by Grady Booch and adopted and prescribed by the Extreme programming methodology.
As an analogy with another Extreme programming technique TDD is not about unit testings (although it uses unit testing), but about feedback, about obtaining feedback as soon as possible to speed up the development cycles (which is implemented in a concrete usage of unit testing).
With CI the software is built several times a day (ideally every few hours), every time a developer integrates code in the mainline (which should be often) in order to avoid “integration hell” (merging code from different developments at the end of a development interaction). CI avoids this “integration hell” by integrating code as soon as possible and forcing team members to view what other developers are doing to take shared team decisions about new code.
The methodology states that every team member integrates into the mainlines often as possible. Every contribution to the VCS (Version Control System) is potentially a release so every contribution should not break functionality and should pass all known tests.
A CI Server will construct an artifact from the last sources of mainline and pass all known tests. If there is a failure the CI will warn all members of the team of the state of the build (RED).
The maximum priority of the team is to keep the build in its default value (GREEN).
What is not CI?
Once we realized that CI is far more than the simple usage of a CI Server we can state that:
- Working with Feature branches and have a CI checking master is not CI
- Working with Pull Requests is not CI
It’s important to note that I’m not judging in terms of good/bad practices, both feature branches and pull requests they are simply other methodologies different than CI.
Both Feature branches and pull requests rely working on a different branch than the master (the one monitored by the CI Server) this leads to longer cycles before they could be merged into master.
Feature branches and pull requests that rely profoundly on team resource/task planification to avoid refactors on one task(branch) that affects developments on another task(branch) minifying the threaded “integration hell”.
Example of an integration hell: We have the following code, two classes that leverage the API rest calls to an external API:
APIUsersAccessor
class APIUsersAccessor
{
const USERS_API_PATH = "/users";
/**
* @var string
*/
private $host;
/**
* @var string
*/
private $username;
/**
* @var string
*/
private $password;
public function __construct(string $host, string $username, string
$password)
{
$this->host = $host;
$this->username = $username;
$this->password = $password;
}
public function getAllUsers(): array
{
$data = array(
"email" => $this->username,
"password" => $this->password
);
$headers = array(
"Content-Type" => "application/json;charset=UTF-8"
);
$request = \Requests::GET($this->host.self::USERS_API_PATH,
$headers, json_encode($data));
return json_decode($request->body);
}
}

APIProductsAccessor
class APIProductsAccessor
{
const PRODUCTS_API_PATH = "/products";
/**
* @var string
*/
private $host;
/**
* @var string
*/
private $username;
/**
* @var string
*/
private $password;
public function __construct(string $host, string $username, string
$password)
{
$this->host = $host;
$this->username = $username;
$this->password = $password;
}
public function getAllProducts(): array
{
$data = array(
"email" => $this->username,
"password" => $this->password
);
$headers = array(
"Content-Type" => "application/json;charset=UTF-8"
);
$request = \Requests::GET($this->host.self::PRODUCTS_API_PATH,
$headers, json_encode($data));
return json_decode($request->body);
}
}
As you can see both codes are very similar (is the classical code duplication). Now we are going to start two development features with 2 development branches. The first development must add a telephone number to the request to the Products API, the second one must create a new API to query all cars available at a store. This is the code in the Products API after adding the telephone number:

APIUsersAccessor (with telephone)
class APIUsersAccessor
{
....
public function __construct(string $host, string $username, string
$password)
{
.......
$this->telephone = $telephone;
}
public function getAllUsers(): array
{
$data = array(
"email" => $this->username,
"password" => $this->password,
"tel" => $this->telephone
);
..... }
}
Ok, the developer has added the missing field and has added it to the request. The developer of branch 1 expects this diff as the merge with a master:
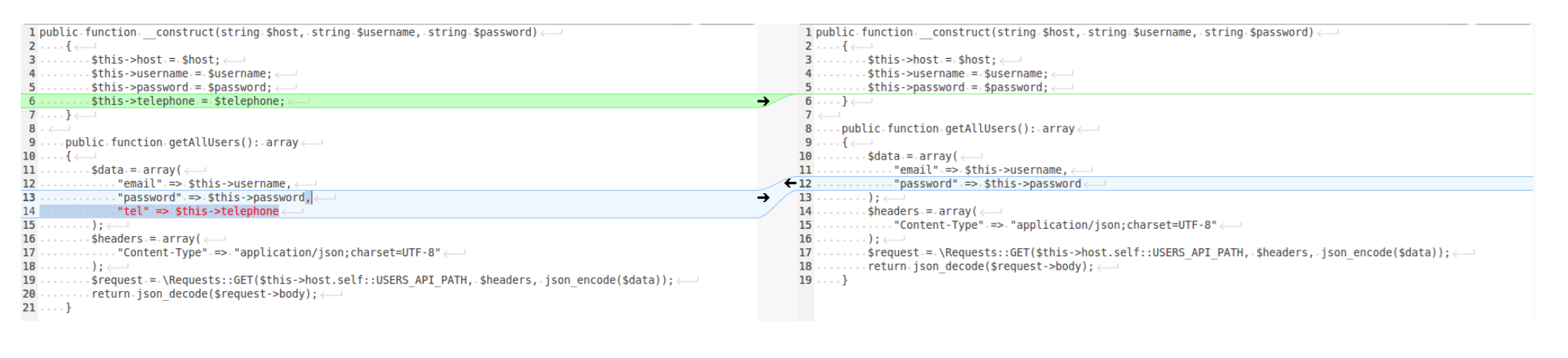
But the problem is that developer1 does not know that developer 2 has made a refactor in order to reduce code duplication because CarAPI is too similar to UserAPI and ProductAPI, so the code in his branch will be like this:
BaseAPIAccessor
abstract class BaseAPIAccessor
{
private $apiPath;
/**
* @var string
*/
private $host;
/**
* @var string
*/
private $username;
/**
* @var string
*/
private $password;
protected function __construct(string $host,string $apiPath, string
$username, string $password)
{
$this->host = $host;
$this->username = $username;
$this->password = $password;
$this->apiPath = $apiPath;
}
protected function doGetRequest(): array
{
$data = array(
"email" => $this->username,
"password" => $this->password
);
$headers = array(
"Content-Type" => "application/json;charset=UTF-8"
);
$request = \Requests::GET($this->host.$this->apiPath, $headers,
json_encode($data));
return json_decode($request->body);
}
}
concrete APIs
class ApiCarsAccessor extends BaseAPIAccessor
{
public function __construct(string $host, string $username, string
$password)
{
parent::__construct($host, "/cars", $username, $password);
}
public function getAllUsers(): array
{
return $this->doGetRequest();
}
}
class APIUserAccessor extends BaseAPIAccessor
{
public function __construct(string $host, string $username, string
$password)
{
parent::__construct($host, "/users", $username, $password);
}
public function getAllUsers(): array
{
return $this->doGetRequest();
}
}
class APIProductsAccessor extends BaseAPIAccessor
{
public function __construct(string $host, string $username, string
$password)
{
parent::__construct($host, "/products", $username, $password);
}
public function getAllProducts(): array
{
return $this->doGetRequest();
}
}
So the real merge will be:
 So basically we will have a big conflict at the end of development cycle when will merge branch1 and branch2 into mainline. We will have to do a lot of code reviews, which will involve an archaeological process of reviewing all pasts decisions in a development phase and see how to merge the code. In this concrete case, the telephone number will also involve some kind of rewrite.
So basically we will have a big conflict at the end of development cycle when will merge branch1 and branch2 into mainline. We will have to do a lot of code reviews, which will involve an archaeological process of reviewing all pasts decisions in a development phase and see how to merge the code. In this concrete case, the telephone number will also involve some kind of rewrite.
Some will argue that developer2 should not have done refactor because planning stated that he has to develop ONLY CarApi, and planning stated clearly that there should be no collision with UserAPI. Well yes…but to make that this kind of extreme planification work, there should be a good planning of all resources, we should have a lot of architectural meetings involving developer1 and developer2.
In this architectural meetings developer1 and developer2 should have realized that exists some kind of code duplication and they have to decide o intervene and replan, or do nothing and increase technical debt, moving the refactor decision to future iterations. This may not sound to agile, right? but the point is that is difficult to mix agile and non-agile practices.
If we do feature branch / pull requests full iterative planification process works better if we’re doing agile continuous integration, is the right tool. Again I’m not stating that feature branches/pull requests are good/bad tools, I’m simply stating that they are non-agile practices.
Agile is all about communication, is all about continuous improvement and it’s all about feedback as soon as possible. In the agile approach developer1 will be aware of the refactoring of developer2 in the beginning, being able to start a dialog with developer1 and check if the type of abstraction that it’s proposing will be the correct one to fit also the addition of a telephone number.
Ok….but wait! I need a feature branch! What if not all features are deliverable at the end of an iteration?
Feature branches are a solution to a problem: what to do if not all code is deliverable at the end of an iteration, but it is not the only solution.
CI has another solution to this problem – “Feature toggles”. Feature branches isolate the work-in-progress feature from the final product via a branch (the w.i.p. lives in a separate copy of the code), Feature toggles isolate the feature from the rest of the code using.. Code!
The simplest feature toggle one can write is the dreaded if-then-else, is the example you will find in most sites when you googled “feature toggle”. It is not the only way to implementing, as any other type of software engineering you can replace this conditional logic with polymorphism.
In this example in Slim we are creating in the current iteration a new REST endpoint, we do not want to be ready for production, we have this code:

code prior the toggling
<?php
require '../vendor/autoload.php';
use resources\OriginalEndpoint
$config = [
'settings' => [
'displayErrorDetails' => true,
'logger' => [
'name' => "dexeus",
'level' => Monolog\Logger::DEBUG,
'path' => 'php://stderr',
], ],
];
$app = new \Slim\App(
$config );
$c = $app->getContainer();
$c['logger'] = function ($c) {
$settings = $c->get('settings');
$logger = LoggerFactory::getInstance($settings['logger']['name'],
$settings['logger']['level']);
$logger->pushHandler(new
Monolog\Handler\StreamHandler($settings['logger']['path'],
$settings['logger']['level']));
return $logger;
};
$app->group("", function () use ($app){
OriginalEndpoint::get()->add($app); //we are registering the endpoint
in slim });
We can define the feature toggle with a simple if clause

if clause feature toggle
<?php ....
$app->group("", function () use ($app){
OriginalEndpoint::get()->add($app);
if(getenv("APP_ENV") === "development") {
NewEndpoint::get()->add($app); // we are registering the new
endpoint if the environment is set to development (devs machines should
have APP_ENV envar setted to development)
} });
and we can refine our code to express better what we’re doing and be able to have several environments (maybe for having a test AB situation?)

configuration map feature toggle
<?php
......
$productionEnvironment = function ($app){
OriginalEndpoint::get()->add($app);
};
$aEnvironment = function ($app){
productionEnvironment($app);
NewEndpointA::get()->add($app);
};
$bEnvironment = function ($app){
productionEnvironment($app);
NewEndpointB::get()->add($app);
};
$develEnvironment = function ($app){
productionEnvironment($app);
NewEndpointInEarlyDevelopment::get()->add($app);
};
$configurationMap = [
"production" => $productionEnvironment,
"testA" => $aEnvironment,
"testB" => $bEnvironment,
"development" => $develEnvironment
];
$app->group("", function () use ($app, $configurationMap){
$configurationMap[getenv("APP_ENV")]($app);
});
The advantages of this technique is coherent with the main goal of CI (having constant feedback about code integration / validation / and collisions with other developments), the code in progress is developed and deployed into production and we have constant feedback about the integration of the new feature with the rest of the code, leveraging the risk of enabling the feature when it’s developed.
It is a good practice to remove this kind of toggles from code, once the new feature has been stabilized in order to avoid adding complexity to the codebase.
Ok, we have arrived at the end of this first part of true Continuous Integration. We have rediscovered that continuous integration is “not only” using a CI server but adopting a practice with perseverance and discipline. In the second part, we will talk about how to model a GOOD CI flow.
In order not to miss the second part of true Continuous Integration, subscribe to our monthly newsletter here.
If you found this article about true Continuous Integration interesting, you might like…
Scala generics I: Scala type bounds
Scala generics II: covariance and contravariance
F-bound over a generic type in Scala
Microservices vs Monolithic architecture
Benefits of true Continuous Integration
Working software over number of functionalities
True Continuous Integration with fastlane & Jenkins in iOS
The post Back to the roots: towards true Continuous Integration (part one) appeared first on Apiumhub.
Posted on April 17, 2018
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.