Database Mesh 2.0: Database Governance in a Cloud Native Environment

Apache ShardingSphere
Posted on June 2, 2022

In March 2018, an article titled Service Mesh is the broad trend, what about Database Mesh?, was pubslished on InfoQ China and went viral in the technical community.
In this article, Zhang Liang, the founder of Apache ShardingSphere, described Database Mesh concept along with the idea of Service Mesh. Four years later, the Database Mesh concept has been integrated by several companies together with their own tools and ecosystems. Today, in addition to Service Mesh, a variety of “X Mesh” concepts such as ChaosMesh, EventMesh, IOMesh have emerged. Following four years of development, Database Mesh has also started a new chapter: Database Mesh 2.0.
This article reviews the background of Database Mesh, reexamines the value of Database Mesh 1.0, and introduces the new concepts, ideas, and features of Database Mesh 2.0. It also attempts to explore the future of Database Mesh.
1. Reviewing Database Mesh 1.0
In 2016, the first generation of Service Mesh was introduced to the public by Linkerd. In 2017, the second generation of Service Mesh, was born thanks to Istio. Its design separates the control plane from data plane, and key behavioral factors such as traffic governance, access control and observability in service governance are abstracted and standardized. Then the application container and governance container are decoupled by Kubernetes’ Sidecar model. It was at this point that Service Mesh was finally shaped.
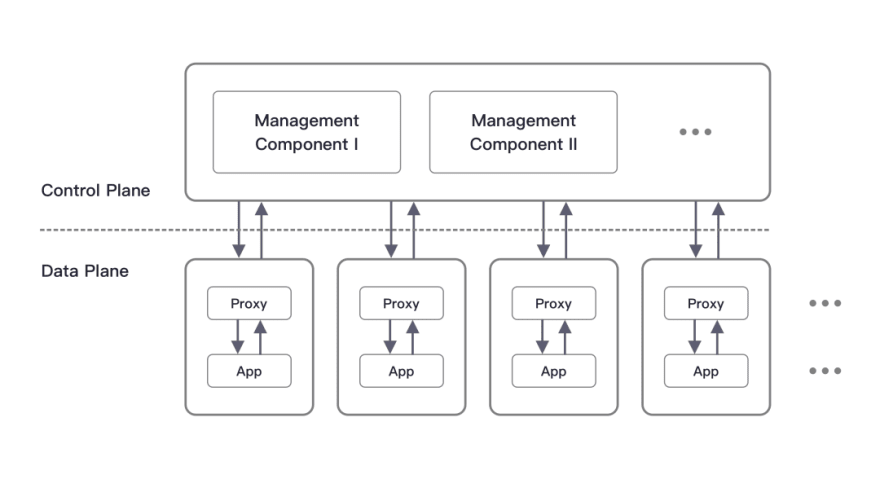
Almost at the same time, ShardingSphere led by Zhang Liang evolved from the original ShardingSphere-JDBC into the ShardingSphere-Proxy we know today, that can be deployed independently. Both built in Java, respectively representing SDK mode and Proxy mode, providing the same standardized data sharding, distributed transactions and other features.
Both of them have their respecitve pros and cons. In 2018, the article, Service Mesh is the broad trend, what about Database Mesh? written by Zhang Liang (on InfoQ China) described Database Mesh as:
”Database Mesh is a new term derived from Service Mesh. As its name suggests, Database Mesh uses a mesh layer to achieve unified management of databases scattered around the system. The network of interactions between applications and databases, held together by mesh layers, is as complex and ordered as a spider’s web.”
According to this description, the concept of Database Mesh is similar to that of the Service Mesh. It is called Database Mesh, not Data Mesh, because its primary goal is not to engage data stored in the database, but to engage the interaction between applications and databases.
Database Mesh focuses on how to organically connect distributed applications for data access with databases. It’s more focused on the interaction, and effectively clarifies the interaction between chaotic applications and databases.
Database Mesh empowers applications that access databases, eventually forming a huge databases grid. Applications and databases can simply be matched in the grid and are governed by the mesh layer.
This means that the implementation of Service Mesh in Kubernetes’ Sidecar model opens new possibilities: ShardingSphere-Sidecar mode can effectively combine the advantages and minimize the disadvantages of JDBC, Proxy and Proxy client, and achieve a real cloud infrastructure with “elastic scaling + zero intrusion + decentralization”.
When a new technology concept is launched, it’ll be characterized hahahby different business scenarios and patterns, different architectural design, different infrastructure maturity, and even different engineering cultures. It is a belief that has been fully demonstrated in the implementation of Kubernetes, and has been reinforced by Service Mesh. What about Database Mesh?
ShardingSphere-Sidecar incorporates ShardingSphere’s sharding capabilities, while some companies delivered their own interpretation based on Database Mesh.
For example, analysis and support for SQL protocol are added in Service Mesh by means of secondary development to enhance the database traffic governance ability, which is compatible with the unified service governance configuration. The concept of Database Mesh is integrated into a complete set of middleware service frameworks, and a unified access mode is provided for business applications in the form of SDK or Sidecar to simplify the operation for developers.
Another example is the project that integrates distributed transaction capabilities into the Database Mesh Sidecar, presenting business applications as cloud native distributed databases. Either way, you can see that the Database Mesh concept is taking gaining acceptance and growing into a thriving ecosystem.
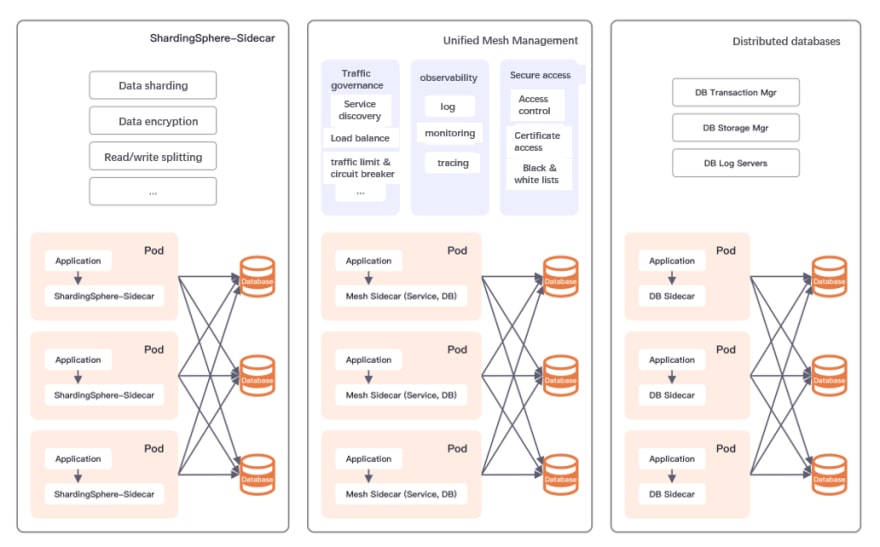
Note: There are three implementations of Database Mesh 1.0: ShardingSphere-Sidecar, Unified Mesh management, and distributed database from left to right respectively.
So that’s Database Mesh 1.0.
2. Introducing Database Mesh 2.0
In computer science, operating systems and databases are arguably the two most important basic softwares. SQL, for example, has an impressive half-life period. SQL not only played an important role in the early DBMS systems, but recently has become a must-have skill in data science along with Python. The vitality of SQL can be said to be timeless, which explains the famous paper proclaiming “One SQL to rule them all”.
If the database is perceived as a service node in the call-chain, then the framework of Service Mesh can also be used for governance. If a database is viewed as a stateful business application, its unique field gives rise to governance specificities. For example, database requests cannot be randomly routed to any peer nodes like services. More challenges are caused by the perception and understanding of database protocols, data sharding and routing, multiple replicas deployed by database, read/write splitting, and multiple writes to the primary library.
Moreover, when business applications are packaged and delivered in containers, and they are distributed to the Kubernetes infrastructure of each data center hundreds of thousands of times through CI/CD pipelines, people will undoubtedly think about how to achieve service governance in the upper layer of applications and database governance. Database Mesh is an answer to this question.
Without Database Mesh, SDK and Proxy can also support the access and governance to databases. Sidecar itself is not the core of Database Mesh.
Database Mesh is not a static definition, but an evolving dynamic concept.
Database Mesh 1.0 has been focusing on the governance of database traffic. It can support data sharding, load balancing, observability, auditing and other capabilities based on database protocol sensibility, which have tackled part of the problems related to traffic governance. However, many capabilities are still yet to be built for operators and database administrators (DBAs). For instance, can a unified configuration be used to declare database access? Can we restrict resource access to the database in a programmable way? Can the database maintenance experience be automated through a standard interface?
Developers may pay more attention to operational efficiency, cost overhead, database protocol type and access information rather than where the data is stored. Operators and database administrators (DBAs) are more concerned about the automation, stability, security, monitoring and alarming of database services. In addition, DBAs also focus on the changes, capacity, secure access, backup and migration of data. All of these factors are tied with database reliability engineering.
It is precisely with the in-depth understanding of database governance scenarios and the pursuit of ultimate user experience that led to the creation of Database Mesh 2.0. Database Mesh 2.0 can achieve high-performance scalability through programmability to address the challenge of database governance on the cloud.
The goals of Database Mesh 2.0
Database Mesh 2.0 focuses on how to achieve the following goals in a cloud native environment:
- Further reduce the mental burden of developers, improve development efficiency, and provide a transparent and intuitive user experience with database infrastructure.
- Build a database governance framework including database traffic, runtime resources, reliability in a configurable, pluggable and customizable manner.
- Provide standard user interfaces for typical scenarios in multiple database fields such as heterogeneous data sources, cloud native databases, and distributed databases.
Developer experience
As mentioned above, business developers are mainly concerned about business logic and implementation instead of infrastructure, operation and maintenance features. Developement experience will move towards Serverless, which means it will become more and more transparent and intuitive when accessing databases. Developers only need to understand the type of data storage required by their business, and then use preset or dynamic ID credential information to access corresponding database services.
Programmable
For database traffic, different scenarios have different load balancing policies and firewall rules, which can be provided to users in the form of configuration. Furthermore, runtime resources such as traffic and bandwidth can be restricted by loading programmable plugins. Both configurations and plugins are designed to provide users with the maximum flexibility within the framework, implementing the Unix design philosophy of “separation of mechanism and policy”.
Standard interface
In the process of migrating databases to the cloud, the migration complexity has increased due to many issues such as deployment mode, data migration, and data capacity. If you have a complete set of operating interfaces, you can achieve unified governance across different database environments, thus smoothing the process of cloud adoption in the future.
Database Mesh 2.0 governance framework
Database Mesh 2.0 provides a database-centric governance framework to achieve the three goals introduced above:
- Databases are first-class citizens. All abstractions are centered on database governance, such as access control, traffic governance, and observability.
- Engineer-oriented experience: developers can continue to develop through easy to use database declarations and definitions regardless of the location of the database. For operation and maintenance personnel and DBAs, it provides a variety of abstraction of database governance behavior to realize automatic database reliability engineering.
- Cloud native: it is built and implemented oriented towards cloud native, suitable to various cloud environments with an open ecosystem and implementation mechanism. Vendor lock-in is effectively elimated.
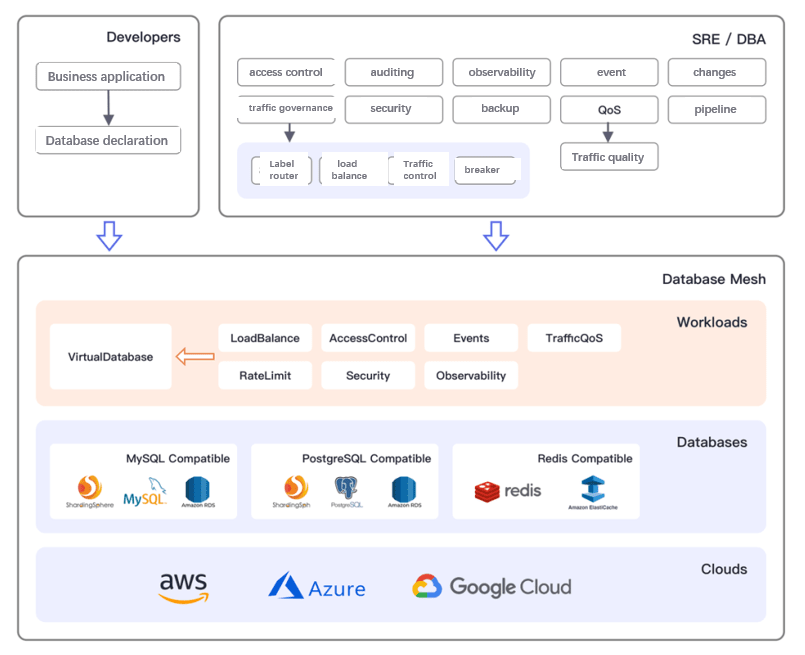
The set of governance framework relies on the following work loads:
- Virtual database: a database endpoint accessible to developers.
- Traffic strategy: governance strategies for database access traffic such as sharding, load balance, traffic control and circuit breaker.
- Access control: provides fine-grained access control based on specified rules, such as table level.
- Security statement: data security statements such as data encryption.
- Audit application: record applications’ operation behavior on the database, such as accessing the risk control system.
- Observability: configuration of database observability such as access traffic, running state, and performance indicators etc.
- Event bus: an event bus that accepts data changes.
- QoS statements: resource QoS metrics set to improve the overall SLO metrics of the database.
- Backup plan: perform database backups as scheduled tasks.
-
Schemapipeline: manage databaseschemachanges in code to improve the success rate of database DDL and DML changes. The above design framework enables development to be more centralized and efficient and cloud computing more user-friendly. In other words, Database Mesh is making big strides towards scalability, ease of use and standardization.
That’s Database 2.0.
3. Database Mesh community
The Database Mesh official website has been launched. The corresponding specification definition is open sourced on this Github repository. The community holds an online discussion every two weeks:
- Mailing list
- Biweekly meeting of English community (from February 27, 2022), on Wednesday 9:00 AM PST
- Biweekly meeting of Chinese community (from April 27, 2022), on Wednesday 9:00 PM GMT+8
- Slack
- Meeting minutes
You’re welcome to join the official community for discussion. The Database Mesh community welcomes enthusiasts from from all over the world to build the ecosystem together.
SphereEx, a company founded by Zhang Liang (who is also the initiator of Database Mesh), will launch Pisanix next month, which is an open source solution oriented database mesh.
Authors
Miao Liyao
Github: @mlycore

The Head of Cloud R&D at SphereEx, a promoter of open source, specializing in SaaS and Database Mesh
In 2015, he began to study Kubernetes and was one of the earliest cloud native practitioners in China. In 2016, he established the “Container Era” WeChat blog and contributed over 600 technical articles. He previously was an infrastructure architect, cloud product leader, cloud native R&D engineer at 株式会社ネットスターズ(NETSTARS), Beijing Chuanyang Technology, Ant Financial Services Group, YeePay, etc.
Zhang Liang
Github: @terrymanu
Zhang Liang, the founder & CEO of SphereEx, served as the head of the architecture and database team of many large well-known Internet enterprises. He is enthusiastic about open source and is the founder and PMC chair of Apache ShardingSphere, ElasticJob, and other well-known open source projects.
He is now a member of the Apache Software Foundation, a Microsoft MVP, Tencent Cloud TVP, and Huawei Cloud MVP and has more than 10 years of experience in the field of architecture and database. He advocates for elegant code, and has made great achievements in distributed database technology and academic research. He has served as a producer and speaker at dozens of major domestic and international industry and technology summits, including ApacheCon, QCon, AWS summit, DTCC, SACC, and DTC. In addition, he has published the book “Future Architecture: From Service to Cloud Native” as well as the paper “Apache ShardingSphere: A Holistic and Pluggable Platform for Data Sharding” published at this year’s ICDE, a top conference in the database field.
Posted on June 2, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related