The Science behind Generative AI Models

Anna Kovalenko
Posted on December 7, 2022
I covered the topic of Generative AI and types of AI generated content in one of my previous articles. In this one, I will explain the science behind it and answer the important question: how do Generative AI Models work?
If you have read my article “How Generative AI changes the Process of Creating Content”, you know what magical things Generative AI Models can do — from generating images from text prompts to restoring the old movies — and here is how:
Discriminative modeling & Generative modeling
There’s two different types of modeling and to understand the science behind Generative AI it is important to learn the difference between these two.
Discriminative modeling helps to classify existing data points (for example, images of elephants and mice into respective categories). It is mostly used in supervised machine learning tasks.
Generative modeling helps to understand the structure of the dataset and generate similar datasets (for example, creating a photorealistic image of an elephant or a mouse). It is mostly used in unsupervised and semi-supervised machine learning tasks.

Source: Altexsoft
Discriminative modeling
Like most machine learning models, discriminative algorithms classify input data with some set of features and predict a category, a label or a class to which an input data example belongs.
The training data for machine learning models usually contains images — they are called samples — each of which has input features (X) and output class labels (Y). The training data for machine learning models can be, for example, photos of elephants and mice. And there is a neural net that looks at one of those photos, pays attention to the features that distinguish elephants and mice and tells whether that one specific photo is an elephant or a mouse.

p(ylx) = probability of y given x
Source: Altexsoft
The difference between elephants and mice can be limited to just two features x (for example, “the size of the body” and “the presence of the trunk”). In this case, each feature is a dimension so it is easy to present them in a two-dimensional data space. In the illustration above, the blue dots represent elephants and the red dots represent mice. The line represents the decision boundary and shows that the discriminative model learned to separate elephants from mice based on the x features.
When the discriminative model is fully trained and can tell the difference between elephants and mice, it can “recall” what an elephant or a mouse looks like from what it has already seen during training.
If the discriminative model comes across an image from a different class, for example, a house, it can tell that it’s an elephant with some level of probability. In this case, the predicted output (ŷ) is compared to the expected output (y) from the training dataset. Based on the comparison, it is easy to understand how and what in a model needs to be updated to create more accurate outputs for given classes.
So, to sum up, the discriminative model compresses information about the differences between elephants and mice but doesn’t try to understand what exactly elephants and mice are.
Generative modeling
Well, generative algorithms do the complete opposite. They don’t predict a label given to some features, they try to predict features given a certain label. For discriminative algorithms the relations between x and y are more important than the process of how to get x.

p(x,y) = probability of x and y occurring together
Source: Altexsoft
Mathematically speaking, generative modeling can capture the probability of x and y occurring together. Generative algorithms learn the distribution of individual classes and features but not the boundary.
So generative models help to answer the question of what is an elephant or a mouse itself. The illustration above shows that a generative model can predict both “the size of the body” and “the presence of the trunk” features of the animals and also other features from a class. Basically, it means that the generative model learns features and their relations between them to get an idea of what those animals look like in general.
If the generative model knows what kinds of elephants and mice there are in general, then their differences are also known. Those generative algorithms can learn to recreate images of elephants and mice, although that was not in their training dataset.
Generative modeling can help to solve a lot of problems using cutting-edge technologies like GANs and transformer-based algorithms.
GANs (Generative Adversarial Networks)
A generative adversarial network is a machine learning algorithm that puts the two neural networks that are called the generator and the discriminator against each other. The contest between two neural networks takes the form of a zero-sum game, where one agent’s gain is another agent’s loss.
GANs were invented in 2014 by Jan Goodfellow and his colleagues from the University of Montreal. If you want to look at their description of the GAN architecture you can read their paper titled “Generative Adversarial Networks”.
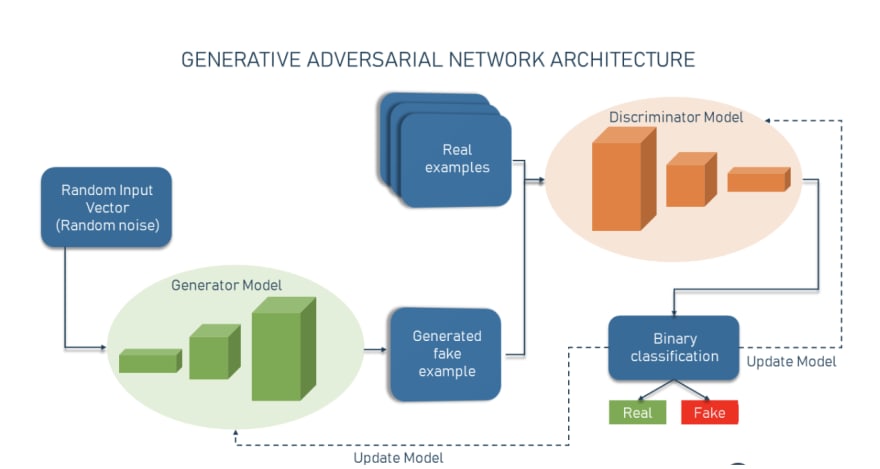
Source: Altexsoft
The GAN architecture has two sub-models in it:
Generator
Generator is a neural net that can create fake input or fake samples from a random input vector (a list of mathematical variables each of whose value is unknown)
Discriminator
It’s a neural net that can take a given sample and decide if it’s a fake sample from a generator or a real sample from the domain. So, basically, the discriminator is a binary classifier that returns probabilities — a number between 0 and 1. If the result is closer to 0, the output is more likely to be fake. And if the number is closer to 1 is more likely to be real.
A generator and a discriminator are often implemented as Convolutional Neural Networks (CNNs), when working with visual content.
Transformer-based models
Transformer-based models are deep neural networks that learn context and therefore meaning by tracking relationships in sequential data, for example, like the words in the sentence. That’s why transformers are often used in Natural Language Processing tasks.
Transformer-based models were firstly described in a 2017 paper “Attention Is All You Need” by Ashish Vaswani and his colleagues from Google. The examples of transformers are GPT-3 and LaMDA.
The transformer-based models can transform one sequence into another. Those models go through semi-supervised learning which means that they are pre-trained in an unsupervised manner using a large unlabeled dataset and then fine-tuned through supervised training to perform better.

Source: Altexsoft
A typical transformer has two parts in it:
The encoder
The encoder works on the input sequence. It extracts all features from a sequence, converts them into vectors (e.g. vectors representing the semantics and position of a word in a sentence) and then passes them to the decoder.
The decoder
The decoder works on the target output sequence. Each decoder receives the encoder layer outputs, derives context from them and generates the output sequence.
Transformers work through sequence-to-sequence learning, so, basically, the transformer takes a sequence of tokens (again, for example, words in a sentence) and predicts the next word in the output sequence. It does this through iterating encoder layers.
Now when you know the science behind generative AI models you can read my other article about generative content in which I describe how generative AI models can be used and what are their advantages and disadvantages.
Posted on December 7, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

November 29, 2024