Need microservice? Take Clojure!

Andrew Panfilov
Posted on April 26, 2024

Initially, this post was published here: https://www.linkedin.com/pulse/lets-write-simple-microservice-clojure-andrew-panfilov-2ghqe/
Intro
This article will explain how to write a simple service in Clojure. The sweet spot of making applications in Clojure is that you can expressively use an entire rich Java ecosystem. Less code, less boilerplate: it is possible to achieve more with less. In this example, I use most of the libraries from the Java world; everything else is a thin Clojure wrapper around Java libraries.
From a business logic standpoint, the microservice calculates math expressions and stores the history of such calculations in the database (there are two HTTP endpoints for that).
Github repository with source code: https://github.com/dzer6/calc
This educational microservice project will provide the following:
- Swagger descriptor for REST API with nice Swagger UI console. Nowadays, it is a standard de facto. Microservices should be accessible via HTTP and operate with data in a human-readable JSON format. As a bonus, it is super easy to generate data types and API client code for the client side (it works well for a TypeScript-based front-end, for example).
- Postgres-based persistence with a pretty straightforward mapping of SQL queries to Clojure functions. If you have ever used Java with Hibernate ORM for data persistence, you will feel relief after working with the database in Clojure with Hugsql. The model of the persistence layer is much simpler and easier to understand without the need for Session Cache, Application Level Cache and Query Cache. Debugging is straightforward, as opposed to the nightmare of debugging asynchronous actual SQL invocation that is never in the expected location. It is such an incredible experience to see the query invocation result as just a sequence of plain Clojure maps instead of a bag of Java entity proxies.
- REPL-friendly development setup. DX (dev experience) might not be the best in class, but it is definitely not bad. Whenever you want to change or add something to the codebase, you start a REPL session in an IDE (in my case, Cursive / IntelliJ Idea). You can run code snippets to print their results, change the codebase, and reload the application. In addition, you can selectively run needed tests. You do not need to restart the JVM instance every time after the codebase changes (JVM is famous for its slow start time). Using the mount library, all stateful resources shut down and initialize correctly every reload.
Leiningen
The project.clj file is a configuration file for Leiningen, a build automation and dependency management tool for Clojure. It specifies the project's metadata, dependencies, paths, and other settings necessary for building the project. Let's break down the libraries listed in the project.clj file into two groups: pure Java libraries and Clojure libraries, and describe each.
Clojure Libraries:
-
org.clojure/clojure: The Clojure language itself. -
org.clojure/core.memoize: Provides memoization capabilities to cache the results of expensive functions. -
org.clojure/tools.logging: A simple logging abstraction that allows different logging implementations. -
mount: A library for managing state in Clojure applications. -
camel-snake-kebab: A library for converting strings (and keywords) between different case formats. -
prismatic/schema: A library for structuring and validating Clojure data. -
metosin/schema-tools: Utilities for Prismatic Schema. -
clj-time: A date and time library for Clojure. -
clj-fuzzy: A library for fuzzy matching and string comparison. -
slingshot: Provides enhanced try/catch capabilities in Clojure. -
ring: A Clojure web applications library. -
metosin/compojure-api: A library for building REST APIs with Swagger support. -
cprop: A configuration library for Clojure. -
com.taoensso/encore: A utility library providing additional Clojure and Java interop facilities. -
com.zaxxer/HikariCP: A high-performance JDBC connection pooling library. -
com.github.seancorfield/next.jdbc: A modern, idiomatic JDBC library for Clojure. -
com.layerware/hugsql-core: A library for defining SQL in Clojure applications. -
metosin/jsonista: A fast JSON encoding and decoding library for Clojure.
Pure Java Libraries:
-
ch.qos.logback: A logging framework. -
org.codehaus.janino: A compiler that reads Java expressions, blocks, or source files, and produces Java bytecode. -
org.slf4j: A simple logging facade for Java. -
org.postgresql/postgresql: The JDBC driver for PostgreSQL. -
org.flywaydb: Database migration tool. -
com.fasterxml.jackson.core: Libraries for processing JSON. -
org.mvel/mvel2: MVFLEX Expression Language (MVEL) is a hybrid dynamic/statically typed, embeddable Expression Language and runtime.
To build the project, just run it in a terminal: lein uberjar
The path to a resulting fat-jar with all needed dependencies: target/app.jar
Frameworks VS Libraries
In the Java world, one common approach is to use full-fledged frameworks that provide comprehensive solutions for various aspects of software development. These frameworks often come with a wide range of features and functionalities built-in, aiming to simplify the development process by providing pre-defined structures and conventions. Examples of such frameworks include the Spring Framework, Java EE (now Jakarta EE), and Hibernate.
On the other hand, in the Clojure world, the approach tends to favour using small, composable libraries rather than monolithic frameworks. Clojure promotes simplicity and flexibility, encouraging developers to choose and combine libraries that best fit their needs. These libraries typically focus on solving one problem well, making them lightweight and easy to understand. Examples of popular Clojure libraries include Ring for web development, Compojure for routing, and Spec for data validation.
The difference between these approaches lies in their philosophies and design principles. Full bloated frameworks in the Java world offer convenience and a one-size-fits-all solution but may come with overhead and complexity. In contrast, small libraries in the Clojure world emphasize simplicity, modularity, and flexibility, allowing developers to build tailored solutions while keeping the codebase lightweight and maintainable.
Docker
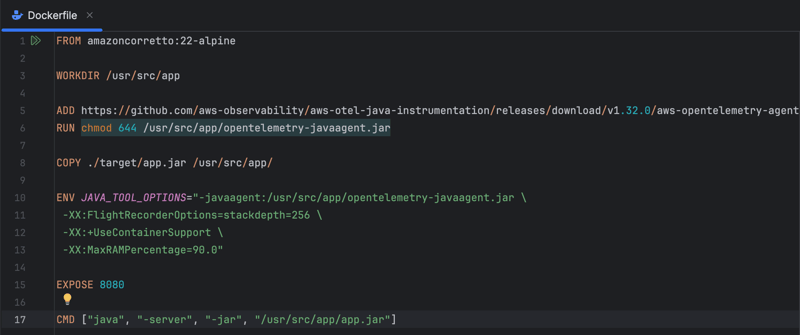
Dockerfile sets up a containerized environment for the application, leveraging Amazon Corretto 22 on Alpine Linux. It downloads the AWS OpenTelemetry Agent (you can use the standard one if you don't need AWS-related) to enable observability features, including distributed tracing, and then copies the application JAR file into the container. Environment variables are configured to include the Java agent for instrumentation and allocate 90% of available RAM (which is useful for a container-based setup). Finally, it exposes port 8080 and specifies the command to start the Java application server.
Dev Experience
REPL
The Read-Eval-Print Loop in Clojure is a highly effective tool for interactive development, which allows developers to work more efficiently by providing immediate feedback. Unlike traditional compile-run-debug cycles, the REPL enables developers to evaluate expressions and functions on the fly, experiment with code snippets, and inspect data structures in real time. This makes the development process more dynamic and exploratory, leading to a deeper understanding of the codebase. Additionally, the REPL's seamless integration with the language's functional programming paradigm empowers developers to embrace Clojure's expressive syntax and leverage its powerful features, ultimately enhancing productivity and enabling rapid prototyping and iterative development cycles. REPL is a bee's knees, in other words.
First you start REPL-session:
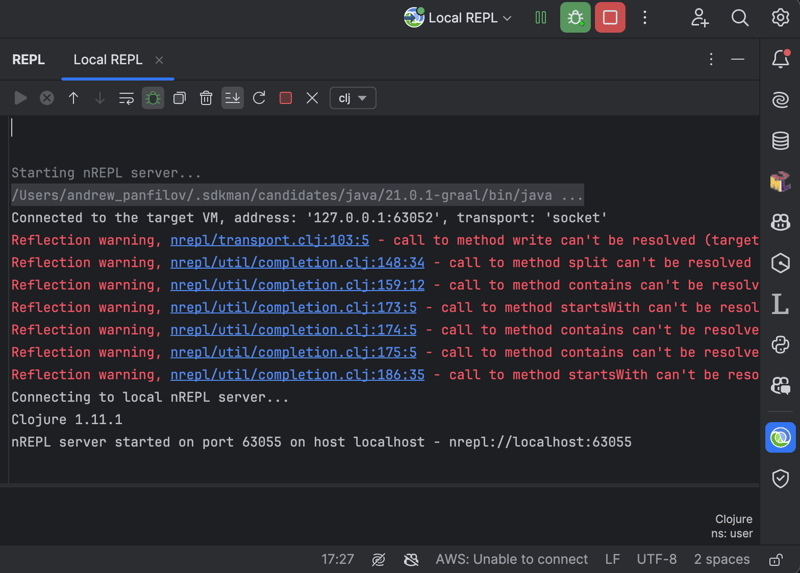
Next you type (init) to invoke initialization function and press Enter – application will start and you will see something similar to:
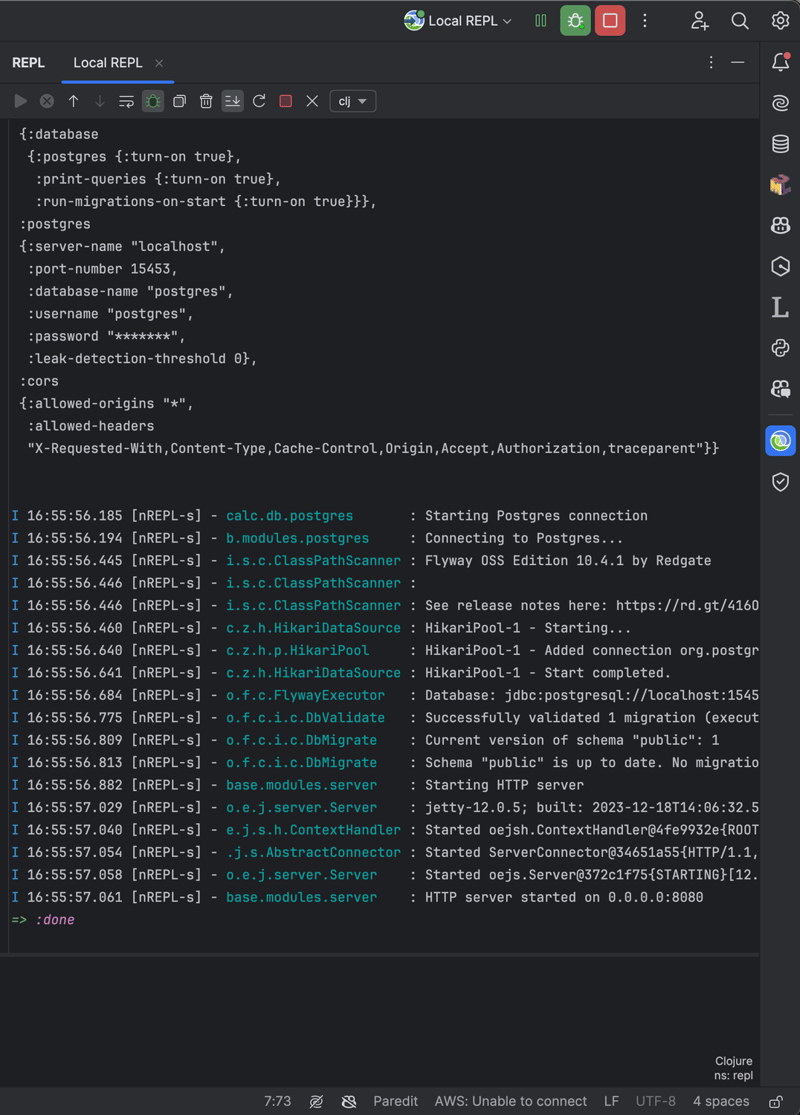
The session logs show that the application loads configurations and establishes a connection with a PostgreSQL database. This involves initializing a HikariCP connection pool and Flyway for database migrations. The logs confirm that the database schema validation and migration checks were successful. The startup of the Jetty HTTP server follows, and the server becomes operational and ready to accept requests on the specified port.
After any code change to apply it, you should type (reset) and press Enter.
To run tests, you should type (run-tests) and press Enter.
Docker Compose
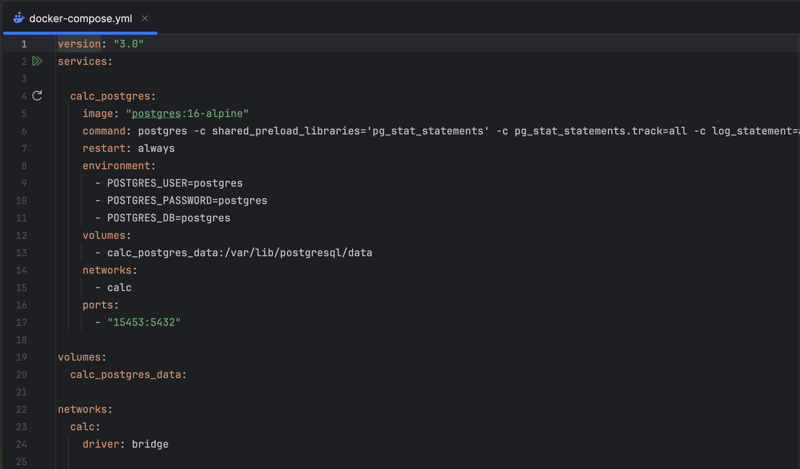
Using Docker Compose to run Postgres and any third-party services locally provides a streamlined and consistent development environment. Developers can define services in a docker-compose.yml file, which enables them to configure and launch an entire stack with a single command. In this case, Postgres is encapsulated within a container with predefined configurations. Docker Compose also facilitates easy scaling, updates, and isolation of services, enhancing development efficiency and reducing the setup time for new team members or transitioning between projects. It encapsulates complex configurations, such as Postgres' performance monitoring and logging settings, in a manageable, version-controlled file, simplifying and replicating the service setup across different environments.
Stateful Resources
The mount Clojure library is a lightweight and idiomatic solution for managing application state in Clojure applications. It offers a more straightforward and functional approach than the Spring Framework, which can be more prescriptive and heavy. Mount emphasizes simplicity, making it an excellent fit for the functional programming paradigm without requiring extensive configuration or boilerplate code. This aligns well with Clojure's philosophy, resulting in a more seamless and efficient development experience.
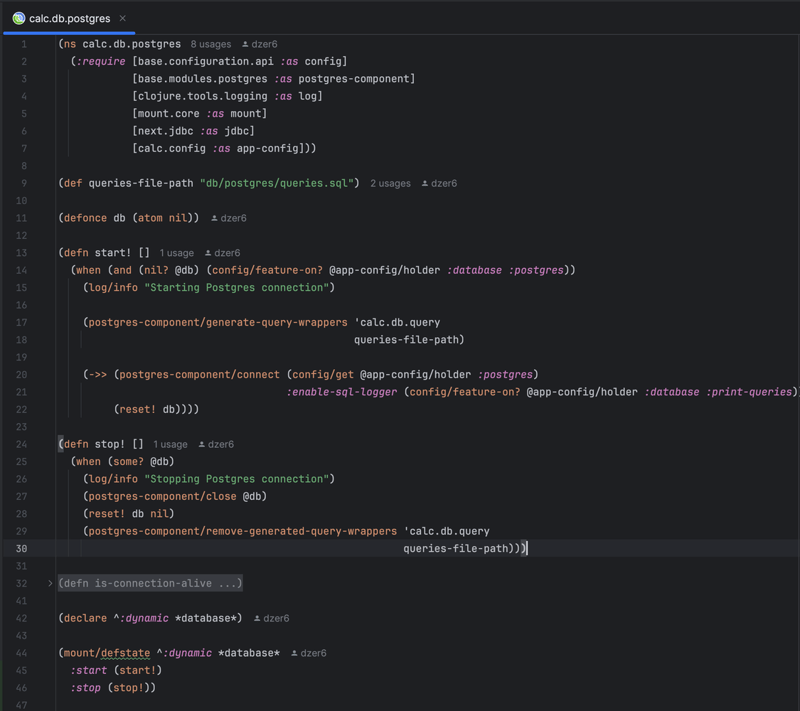
Only two functions: for start and stop.
REST API
Compojure's DSL for web applications makes it easy to set up REST API routes with corresponding HTTP methods. Adding a Swagger API descriptor through libraries like ring-swagger provides a visual interface for interacting with the API and enables client code generation. You can use the Prismatic schema library for HTTP request validation and data coercing to ensure the API consumes and produces data that conforms to predefined schemas. Compojure's middleware approach allows for modular and reusable components that can handle cross-cutting concerns like authentication, logging, and request/response transformations, enhancing the API's scalability and maintainability.
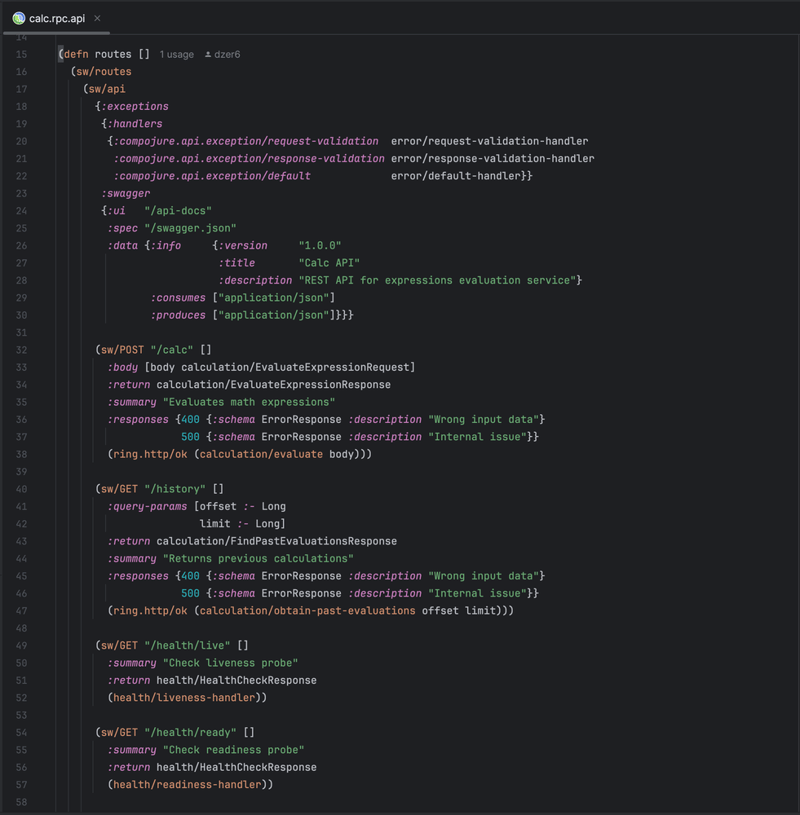
The middleware chain is set up in HTTP server-related namespace:
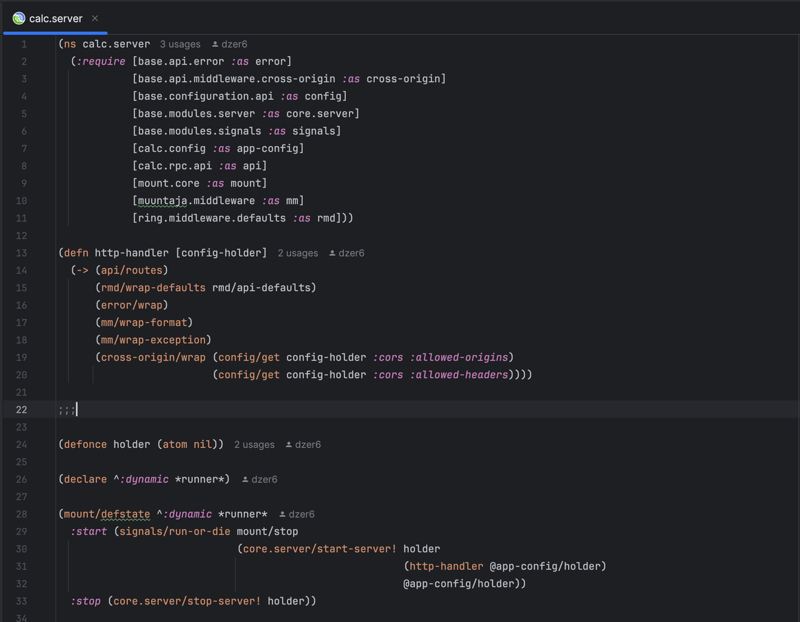
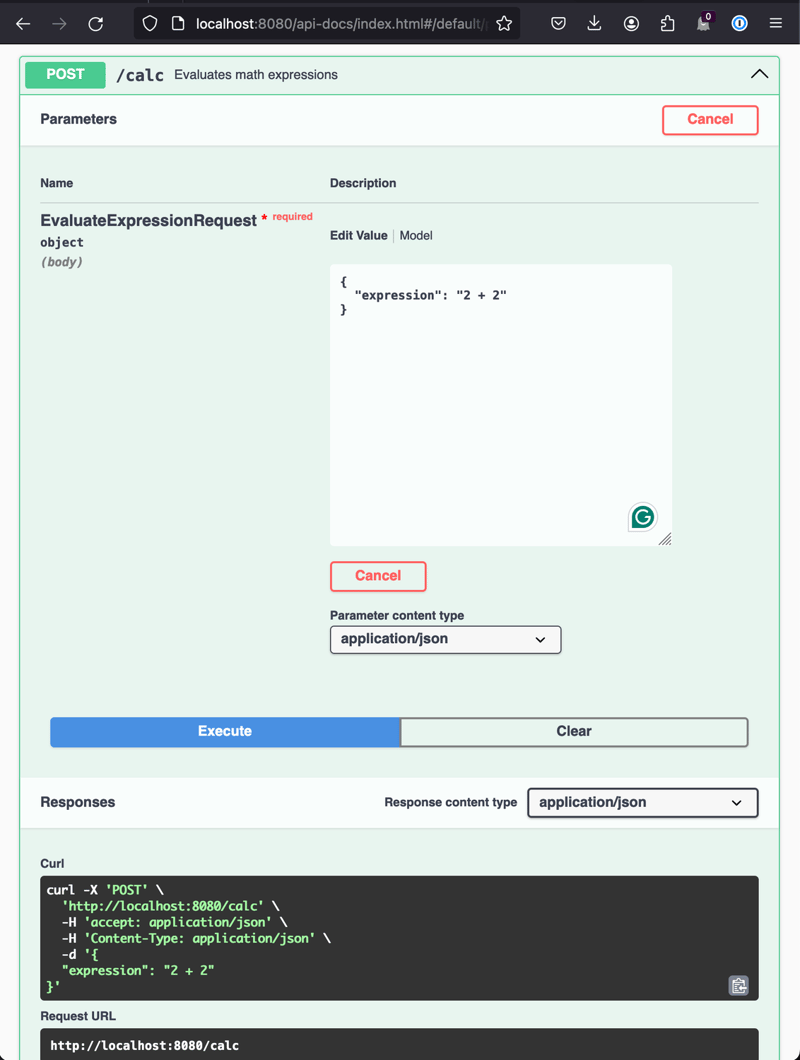
Developers and QA engineers find Swagger UI console highly convenient. I encourage you to run the service locally and try the console in a browser. Here is a list of HTTP endpoints with data schemas:

Isn't it awesome?
Business Logic
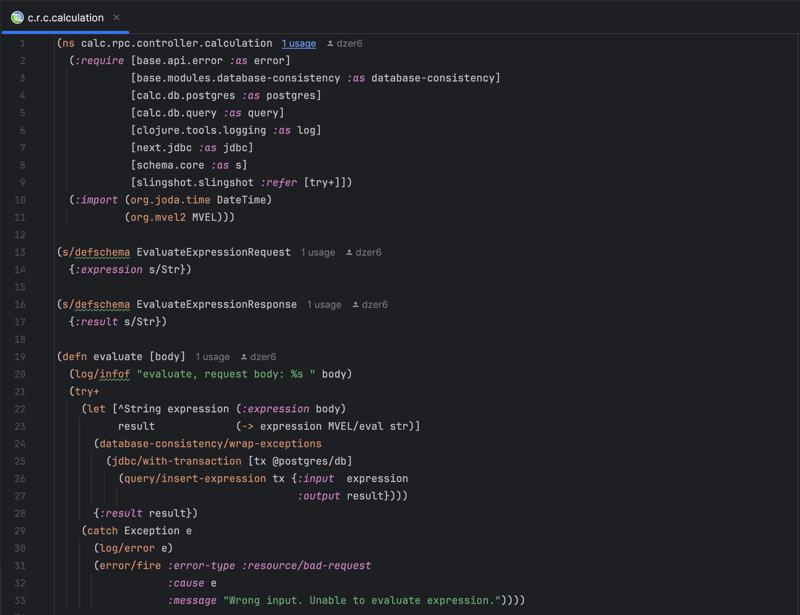
The calc.rpc.controller.calculation controller houses the business logic that defines two primary operations: evaluate and obtain-past-evaluations.
The evaluate operation processes and evaluates mathematical expressions received as requests, storing the results in a database:
The obtain-past-evaluations operation fetches a list of previously executed calculations based on provided offset and limit parameters:
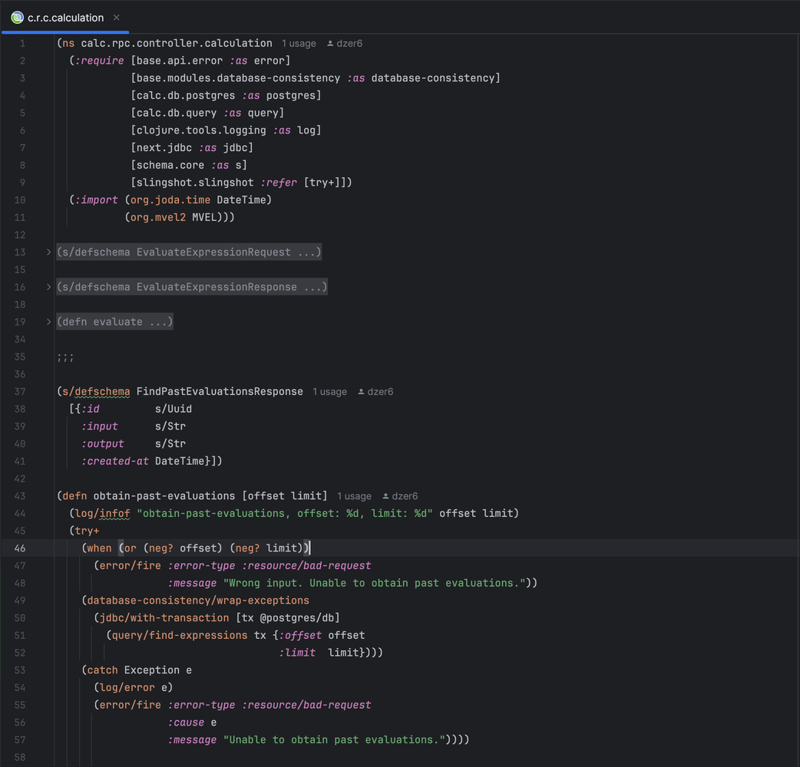
Ensuring that exceptions or database inconsistencies are handled gracefully is crucial for the successful execution of these operations.
The integration of external libraries, MVEL (MVFLEX Expression Language) for expression evaluation, and JDBC for database transactions highlights Clojure's interoperability with Java.
Another essential principle demonstrated by using the MVEL library is never to write your implementation of something already written in Java in Clojure. Most of your business cases are already covered by some Java library written, stabilized, and optimized years ago. You should have strong reasons to write something from scratch in Clojure instead of using a Java analog.
Persistence Layer
Thanks to the hugsql library, we can use autogenerated Clojure functions directly mapped to SQL queries described in a plain text file:
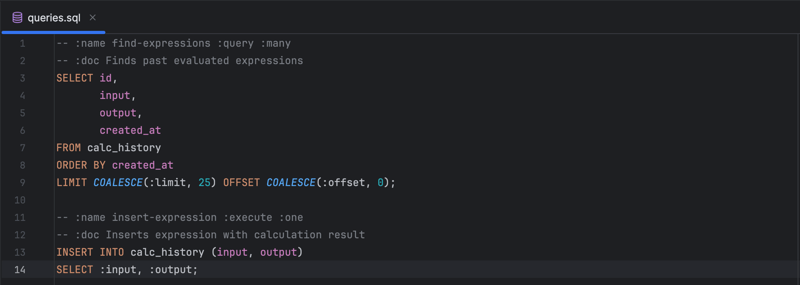
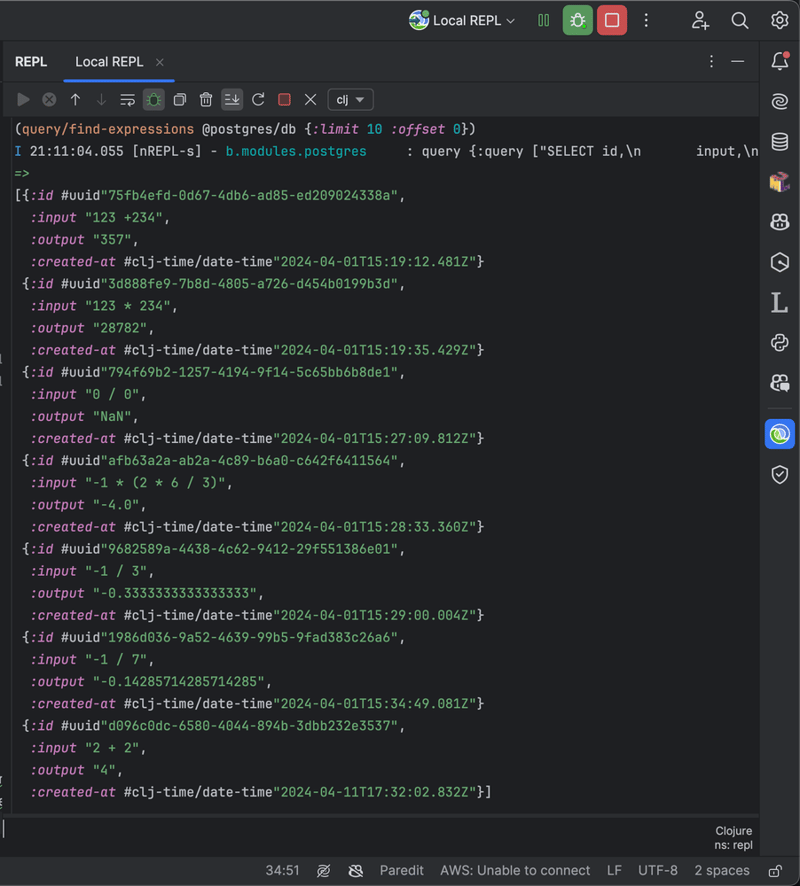
As Clojure is not an object-oriented language, we don't need to specially map query result sets coming from a relational database to a collection of objects in a programming language. No OOP, no ORM. Very convenient. The relational algebra paradigm seamlessly marries with a functional paradigm in Clojure. Very natural:
Compared to NoSQL databases, migrating the data schema in relational databases such as Postgres is a well-established practice. This is typically done through migrations, which is made easy by using the flyway library. To adjust the data schema in Postgres, we simply need to create a new text file containing the Data Definition Language (DDL) commands. In our case there is only one migration file:
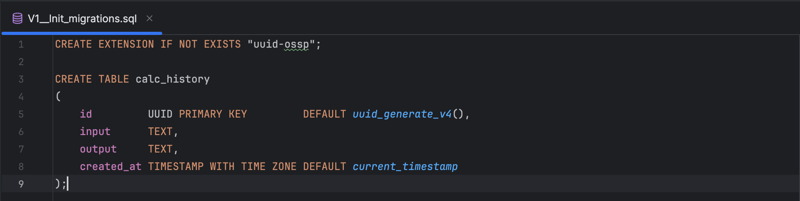
Whenever you change an SQL query in the queries.sql file, do not forget to run the (reset) function in the REPL-session console. It automatically regenerates the Clojure namespace with query declarations and runtime-generated SQL wrapper functions.
Configuration
The system uses the Clojure library cprop to manage its configuration. The library adopts a sequential merge policy to construct the application's configuration map. It starts by loading default-config.edn from resources and overlays it with local-config.edn if available. Then, it applies settings from an external config.edn and overrides by environment variables (adhering to the 12-factor app guidelines). This ensures that the latest source has precedence.
The configuration is essential during development and is a Clojure map validated against a Prismatic schema. If discrepancies are detected, the system immediately shuts down, adhering to the fail-fast principle.
Additionally, feature flags within the configuration enable selective feature toggling, aiding in the phased introduction of new functionality and ensuring robustness in production environments.
Logging
The service utilizes org.clojure/tools.logging to offer a logging API at a high level, which works in conjunction with Logback and Slf4j—two Java libraries that are well-known for their reliability in logging. The logging setup is customized for the application's environment: while in development, logs are produced in a plain text format that is easy to read, allowing for efficient debugging. On the other hand, when the service is deployed on servers, logs are structured in a JSON format, which makes them ideal for machine parsing and analysis, optimizing their performance in production.
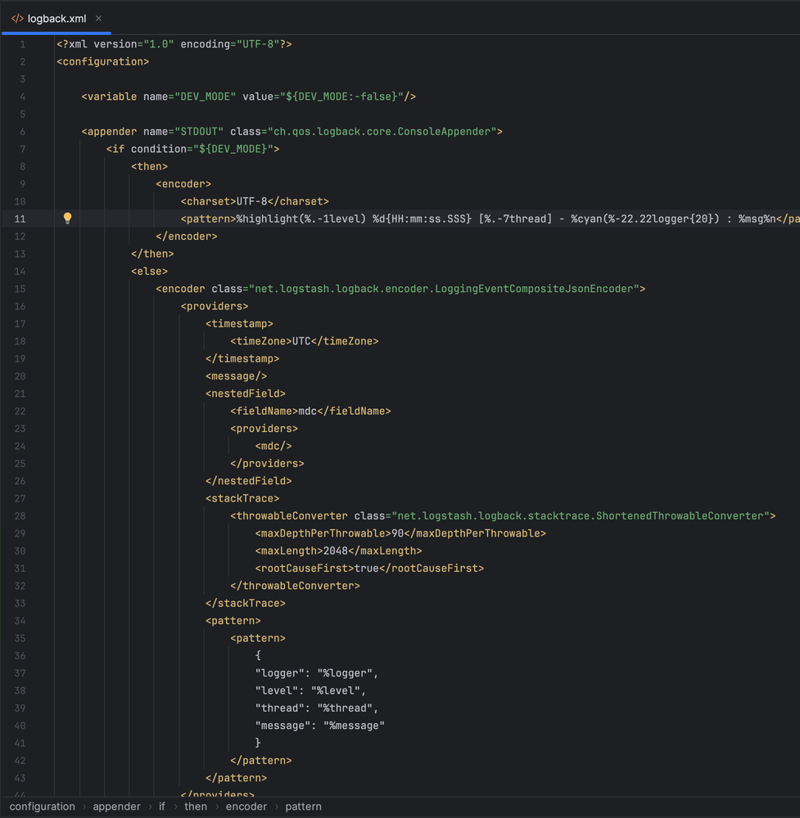
Tests
This is a real-world industrial example. Yes, we do have tests. Not many. But for this size codebase is pretty much okay.
Unfortunately, most open-source Clojure-based projects on Github do not contain good examples of integration tests. So, here we are, trying to close this gap.
We use the TestContainers library to raise real Postgres instances during the tests. Before Docker and TestContainers, the standard de facto in the Java world was running embedded pure Java database H2, trying to mimic Postgres. It was not good, but there was not much choice then.
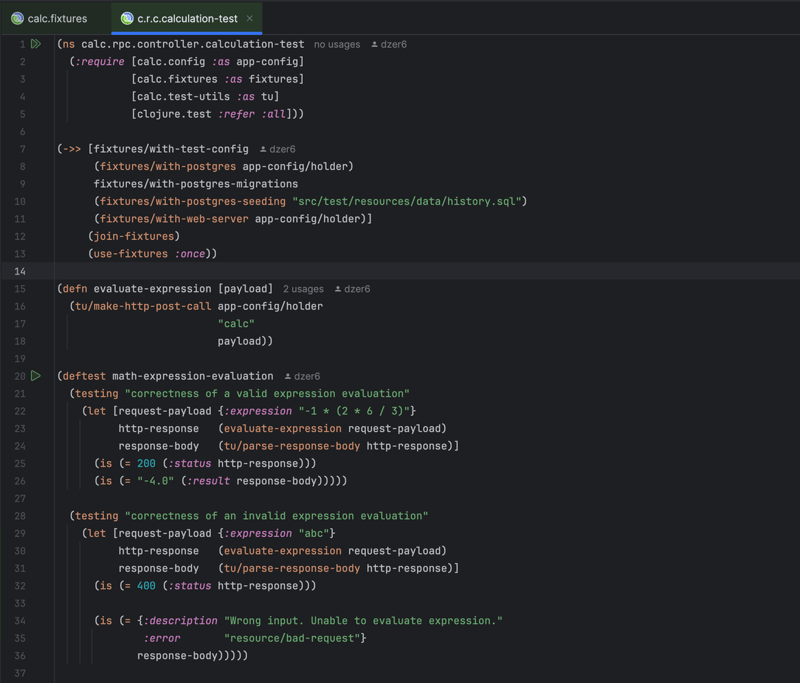
The evaluate operation integration test:
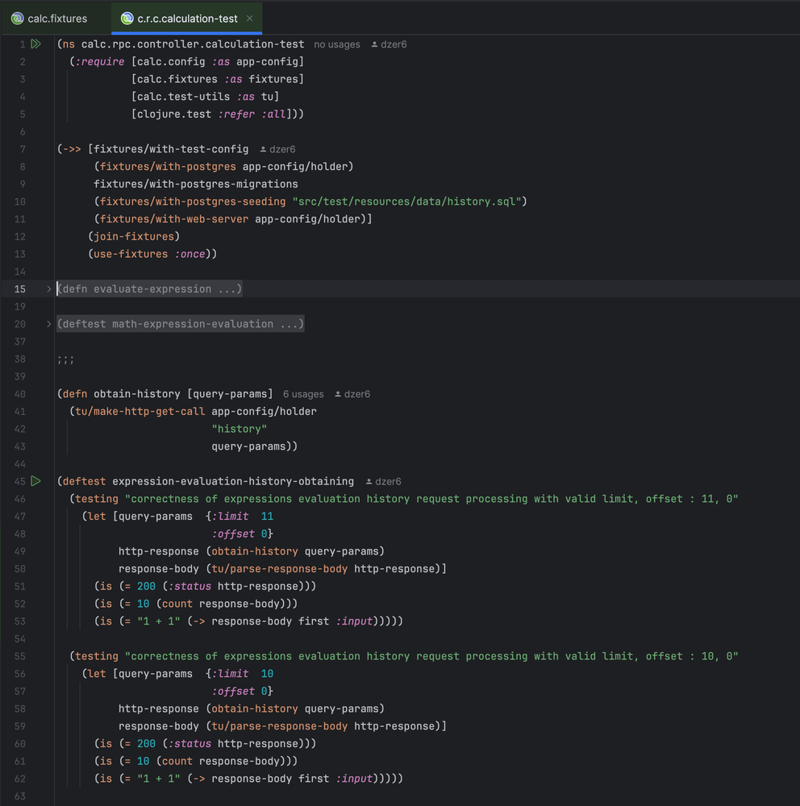
The obtain-past-evaluations operation integration test:
After the tests run, you should see this:
Conclusion
Now, when you go through the service codebase and know its internals, you can copy-paste it for yourself, change it according to your requirements, and voila, you will have a really good-looking microservice.
The described codebase is based on years of Clojure programming and a number of projects that have been implemented in Clojure. Some used libraries may look outdated, but in the Clojure world, if a library works, it is okay not to update it often—the language itself is super-stable, and you can easily read and support code written even a decade ago.
Posted on April 26, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related