How profiling my slow Ruby code led me to publish my first gem!
André Diego Piske
Posted on March 24, 2020
My current side project is a HTTP/2 server, fully written in Ruby. This protocol is a major improvement in comparison to its antecessor, HTTP/1.1, but it also brings along a much higher complexity.
The major change is in the way data is transported over the wire. For instance, when downloading a file through http/1.1, after the headers were exchanged, a server only has to read the file contents from disk and forward them to the client, without any processing involved.
This is not true in http/2. Instead, a server has to send the file contents in chunks. Every one of those chunks has to be wrapped in what the protocol specification calls a frame.
A frame is composed of a header and a payload. Here is a depiction of a frame in HTTP/2, borrowed straight from the spec:
That is all binary data. That Length (24) there is a 24 bits long field, and it stores length of the payload inside the frame.
Where it starts
That binary thing, dealing with bits and bytes, that is where the problem starts.
That picture depicts how slow my server was before I could optimize it. The URL points to localhost, the picture shows a file being downloaded at 4.4 MB/s. Such speed is painfully slow, it should be instantaneous! Downloading a file from a localhost server that is serving only one request should be really fast.
During the file download, the server was showing 100% CPU usage. This gave the insight that the reason of the bad performance could be the fact that ruby was really busy doing stuff. But why so busy? Doing what?
To the profiler!
The best way to know what keeps a program busy is to get to the data, and getting the data means profiling the code. Fortunately, and thanks to some very nice people out there putting effort writing up that gem, ruby has stackprof.
Setting up the gem is very straightforward. I added a StackProf.start call before the code I was suspecting to be slow and also a StackProf.stop after it. This is the code:
The iterate method above is run multiple times in a loop that only stops when the server is shut down. I only wanted to profile that portion, because that's where most of the stuff happens.
I wanted to be able to run the server with and without the profiler, so I made it configurable via those @config.enable_profiling? probes.
I also had to add some code to finish up the profiler. I added that in the code that calls the method above. It looks like this:
The run_forever method above runs the loop that only finishes once the server is shut down. When the @signaled variable evaluates to true, the server has to shut down. The important piece of code is the line that calls StackProf.results. It will dump all the profiler data collected so far to a file.
Then I ran the server, fired some downloads using curl and stopped the server. The profiler results were now dumped into a file. To visualize them, there is another awesome ruby gem called stackprof-webnav. It provides a command to view the profiler results. The following installs it and gets it running:
$ gem install stackprof-webnav
$ stackprof-webnav
That has to be run in the same folder where the profiler result files are stored. It opens a web server and then there is a web UI to view the profiler results.
Finding the bottleneck
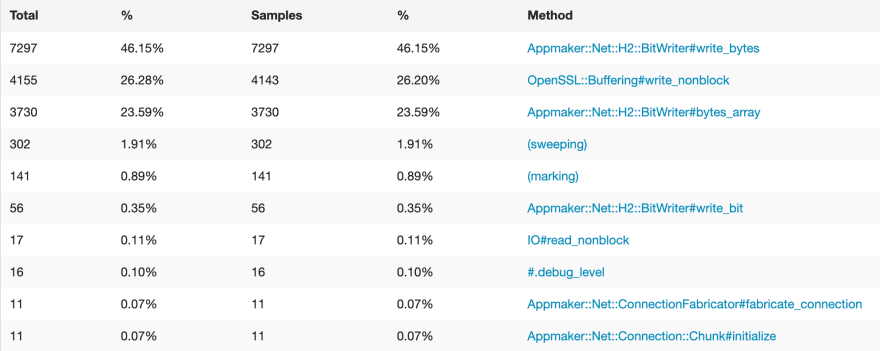
Have done the first run with the profiler on, the results revealed the following:
This was a profile run of that file download operation. And that has a lot to say: 42% of the time just running String.unpack! It's almost half of everything that is being done there.
It struck me. Since HTTP/2 is a binary based protocol, the server needs to deal with bitwise operations to deliver data. Remember how I told before that every chunk of data has to be wrapped in frames?
There are two important things there: chunk and wrapped. The http/2 spec dictates that the maximum size of a frame is only 16 KiB long. This means that every 16 KiB of data has to be wrapped into a frame. That is a lot of processing involved.
Wrapping the chunk is a simple but repetitive operation. And repetitions, namely loops, are the Achilles' heel of interpreted languages like Ruby. If the frames could be larger, it would be possible to wrap it less often, which would more easily allow for a higher performance.
Nevertheless, here is the code of that slowest method call, the BitWriter#write_bytes:
def write_bytes value
value = value.unpack('C*') if value.is_a?(String)
@buffer += value
@cursor += value.length
end
The BitWriter class is responsible for writing binary data into http/2 frames. It has methods to write bytes, integers and strings. The write_bytes method just writes an array of bytes, so it only has to copy the data.
The BitWriter stores all the data internally as an Array of which element is a number from 0 to 255 - thus, a byte. The write_bytes method accepts either an array of bytes as input or a String. For the latter case, it has to first convert it to an array of numbers (bytes). That conversion should be a very simple operation. But that doesn't seem to be what the data is showing there.
My first suspect is the String#unpack, because I knew that most of the calls were actually passing a String to the method. Performing a quick benchmark of the String#unpack method, I concluded it was in fact much more slower than I had anticipated. You can check it yourself how it performs, just hit the Run button below:
That took 6.8 seconds to run on my machine. And that's only 10 thousand times!
Going back to the benchmark results above, the second most busy method call was in OpenSSL's write_nonblock method. That is the method that actually sends the data to the client. However that is a third party library that I have no control over, so I skipped it and went to look after the bytes_array method of the BitWriter class.
This class of mine was causing trouble. Two methods of it together are using almost 70% of the CPU time alone. And it shocks me again, since the code for the bytes_array method is even simpler than the other one. It is exactly this:
defbytes_arraybytes.pack('C*')end
Here, bytes is just an alias to the variable that stores the internal bytes. It is an Array of numbers. I just had found out that the unpack method is very slow, and now I'm about to find out that pack is also very slow. Doing a benchmark in the same manner as before:
This one took about 7.3 seconds on my machine. Again, very slow.
I tried playing around with different ways of achieving the same results. I even went to look into Ruby's source code to check out how that was implemented to why it was so slow. Hint: Reading ruby's source code in C is not that easy. So I went to look for another solution.
The solution
I had played with buffers in JavaScript in the past using classes like the DataView and ArrayBuffer.
Then I thought to myself: What if I had those classes in Ruby?
I went to search for something like that, but couldn't find it. So I thought I should do it myself. Finding out that there was no such thing for Ruby was an additional motivation for me, since I'd be filling a gap!
There was another thing that motivated me. It had been quite a while since I wanted to learn how to integrate Ruby code with C code. That was it. I could make it in C, which would be great for achieving the performance needs, and use it in Ruby!
The standards above are, however, not strictly followed.
Why?
The only way I found to do this was manipulating an array of numbers
treating them as bytes and using buffer.pack('C*') to transform it
into a String object. However, for some reason the Array#pack method
is painfully slow.
Other gems exist out there, like the class
ByteBuffer
class in nio4r. However, they
didn't had a design I was satisfied with or they had different purposes
that wouldn't suit my use case :)
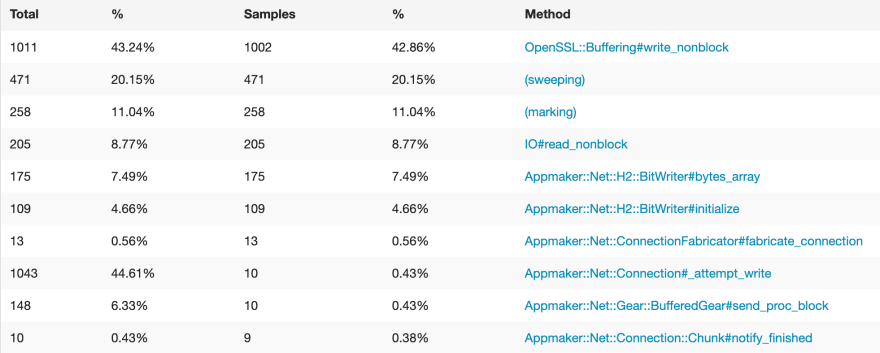
After changing all of the BitWriter code to use the arraybuffer gem with the ArrayBuffer and DataView classes, I went to profile it again. The result was really encouraging:
Amazing! Now the next challenging bottleneck is the OpenSSL writing operation. I have no idea on how to optimize that yet, but will surely look for a way. Coming in second and third places is the mark-and-sweep garbage collector in action. My code is probably producing too much trash. That will also be challenging to profile and optimize. I hope that renders me enough material to write a post!