
Alvin Lee
Posted on March 18, 2024

Since the launch and wide adoption of ChatGPT near the end of 2022, we’ve seen a storm of news about tools, products, and innovations stemming from large language models (LLMs) and generative AI (GenAI). While many tech fads come and go within a few years, it’s clear that LLMs and GenAI are here to stay.
Do you ever wonder about all the tooling going on in the background behind many of these new tools and products? In addition, you might even ask yourself how these tools — leveraged by both developer and end users — are run in production. When you peel back the layers for many of these tools and applications, you’re likely to come across LangChain, Python, and Heroku.
These are the pieces that we’re going to play around with in this article. We’ll look at a practical example of how AI/ML developers use them to build and easily deploy complex LLM pipeline components.
Demystifying LLM Workflows and Pipelines
Machine learning pipelines and workflows can seem like a black box for those new to the AI world. This is even more the case with LLMs and their related tools, as they’re such (relatively) new technologies. Working with LLMs can be challenging, especially as you’re looking to create engineering-hardened and production-ready pipelines, workflows, and deployments. With new tools, rapidly changing documentation, and limited instructions, knowing where to start or what to use can be hard. So, let’s start with the basics of LangChain and Heroku.
The documentation for LangChain tells us this: “LangChain is a framework for developing applications powered by language models.”
Meanwhile, Heroku describes itself this way: “Heroku is a cloud platform that lets companies build, deliver, monitor, and scale apps — we’re the fastest way to go from idea to URL, bypassing all those infrastructure headaches.”
If we put this in the context of building an LLM application, then LangChain and Heroku are a match made in heaven. We need a well-tested and easy-to-use framework (LangChain) to build our LLM application upon, and then we need a way to deploy and host that application (Heroku).
Let’s look into each of these technologies in more detail.
Diving into LangChain
Let’s briefly discuss how LangChain is used. LangChain is a framework that assists developers in building applications based on LLM models and use cases. It has support for Python, JavaScript, and TypeScript. For example, let’s say we were building a tool that generates reports based on user input or automates customer support response. LangChain acts as the scaffolding for our project, providing the tools and structure to efficiently integrate language models into our solution.
Within LangChain, we have several key components:
Agent: The agent is the component that interacts with the language model to perform tasks based on our requirements. This is the brain of our application, using the capabilities of language models to understand and generate text.
Chains: These are sequences of actions or processes that our agent follows to accomplish a task. For example, if we were automating customer support, a chain might include accepting a customer query, finding relevant information, and then crafting a response.
Templates: Templates provide a way to structure the outputs from the language model. For example, if our application generates reports, then we would leverage a template that helps format these reports consistently, based on the model’s output.
LangServe: This enables developers to deploy and serve up LangChain applications as a REST API.
LangSmith: This tool helps developers evaluate, test, and refine the interactions in their language model applications to get them ready for production.
LangChain is a widely adopted framework for building AI and LLM applications, and it’s easy to see why. LangChain provides the functionality to build and deploy products end to end.
Diving into Heroku
Heroku is best known as a cloud platform as a service (PaaS) that makes it incredibly simple to deploy applications to the cloud. Developers often want to focus solely on code and implementation. When you’re already dealing with complex data pipelines and LLM-based applications, you likely don’t have the resources or expertise to deal with infrastructure concerns like servers, networks, and persistent storage.
With the ability to easily deploy your apps through Heroku, the major hurdle of productionizing your projects is handled effortlessly.
Building with LangChain
For a better understanding of how LangChain is used in an LLM application, let’s work through some example problems to make the process clear. In general, we would chain together the following pieces to form a single workflow for an LLM chain:
Start with a prompt template to generate a prompt based on parameters from the user.
Add a retriever to the chain to retrieve data that the language model was not originally trained on (for example: from a database of documents).
Add a conversation retrieval chain to include chat history, so that the language model has context for formulating a better response.
Add an agent for interacting with an actual LLM.
LangChain lets us “chain” together the processes that form the base of an LLM application. This makes our implementation easy and approachable. Let’s work with a simple example.
In our example, we’ll work with OpenAI. We’ll craft our prompt this way:
Tell OpenAI to take on the persona of an encouraging fitness trainer.
Input a question from the end user.
To keep it nice and simple, we won’t worry about chaining in the retrieval of external data or chat history. Once you get the hang of LangChain, adding other capabilities to your chain is straightforward.
On our local machine, we activate a virtual environment. Then, we install the packages we need:
(venv) $ pip install langchain langchain_openai
We’ll create a new file called main.py. Our basic Python code looks like this:
import os
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
my_prompt = ChatPromptTemplate.from_messages([
("system", "You are a friendly and encouraging fitness trainer."),
("user", "{input}")
])
llm = ChatOpenAI(openai_api_key=os.getenv("OPENAI_API_KEY"))
chain = my_prompt | llm
That’s it! In this basic example, we’ve used LangChain to chain together a prompt template and our OpenAI agent.
To use this from the command line, we would add the following code:
user_input = input("Ask me a question related to your fitness goals.\n")
response = chain.invoke({
"input": user_input
})
print(response)
Let’s test out our application from the command line.
(venv) $ OPENAI_API_KEY=insert-key-here python3 main.py
Ask me a question related to your fitness goals.
How do I progress toward holding a plank for 60 seconds?
content="That's a great goal to work towards! To progress
towards holding a plank for 60 seconds, it's important to
start with proper form and gradually increase the duration
of your plank holds. Here are some tips to help you
progress:\n\n1. Start with shorter durations: Begin by
holding a plank for as long as you can with good form,
even if it's just for a few seconds. Gradually increase
the time as you get stronger.\n\n2. Focus on proper form:
Make sure your body is in a straight line from head to
heels, engage your core muscles, and keep your shoulders
directly over your elbows.\n\n3. Practice regularly: Aim
to include planks in your workout routine a few times a
week. Consistency is key to building strength and
endurance.\n\n4. Mix it up: Try different variations of
planks, such as side planks or plank with leg lifts, to
work different muscle groups and keep your workouts
challenging.\n\n5. Listen to your body: It's important to
push yourself, but also know your limits. If you feel any
pain or discomfort, stop and rest.\n\nRemember, progress
takes time and patience. Celebrate each milestone along
the way, whether it's holding a plank for a few extra
seconds or mastering a new plank variation. You've got
this!"
(I’ve added line breaks above for readability.)
That’s a great start. But it would be nice if the output was formatted to be a bit more human-readable. To do that, we simply need to add an output parser to our chain. We’ll use StrOutputParser.
import os
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
my_prompt = ChatPromptTemplate.from_messages([
("system", "You are a friendly and encouraging fitness trainer."),
("user", "{input}")
])
llm = ChatOpenAI(openai_api_key=os.getenv("OPENAI_API_KEY"))
chain = my_prompt | llm | output_parser
user_input = input("Ask me a question related to your fitness goals.\n")
response = chain.invoke({
"input": user_input
})
print(response)
Now, at the command line, our application looks like this:
(venv) $ OPENAI_API_KEY=insert-key-here python3 main.py
Ask me a question related to your fitness goals.
How do I learn how to do a pistol squat?
That's a great goal to work towards! Pistol squats can be challenging but with practice and patience, you can definitely learn how to do them.
Here are some steps you can follow to progress towards a pistol squat:
1. Start by improving your lower body strength with exercises like squats, lunges, and step-ups.
2. Work on your balance and stability by practicing single-leg balance exercises.
3. Practice partial pistol squats by lowering yourself down onto a bench or chair until you can eventually perform a full pistol squat.
4. Use a support like a TRX band or a pole to assist you with balance and lowering yourself down until you build enough strength to do it unassisted.
Remember to always warm up before attempting pistol squats and listen to your body to avoid injury. And most importantly, stay positive and patient with yourself as you work towards mastering this challenging exercise. You've got this!
The LLM response is formatted for improved readability now.
For building powerful LLM applications, our chains would be much more complex than this. But that’s the power and simplicity of LangChain. The framework allows for the modularity of logic specific to your needs so you can easily chain together complex workflows.
Now that we have a simple LLM application built, we still need the ability to deploy, host, and serve our application to make it useful. As a developer focused on app building rather than infrastructure, we turn to LangServe and Heroku.
Serving with LangServe
LangServe helps us interact with a LangChain chain through a REST API. To write the serving portion of a LangChain LLM application, we need three key components:
A valid chain (like what we built above)
An API application framework (such as FastAPI)
Route definitions (just as we would have for building any sort of REST API)
The LangServe docs provide some helpful examples of how to get up and running. For our example, we just need to use FastAPI to start up an API server and call add_routes() from LangServe to make our chain accessible via API endpoints.
Along with this, we’ll need to make some minor modifications to our existing code.
We’ll remove the use of the
StrOutputParser. This will give callers of our API flexibility in how they want to format and use the output.We won’t prompt for user input from the command line. The API call request will provide the user’s input.
We won’t call
chain.invoke()because LangServe will make this part of handling the API request.
We make sure to add the FastAPI and LangServe packages to our project:
(venv) $ pip install langserve fastapi
Our final main.py file looks like this:
import os
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from fastapi import FastAPI
from langserve import add_routes
my_prompt = ChatPromptTemplate.from_messages([
("system", "You are a friendly and encouraging fitness trainer."),
("user", "{input}")
])
llm = ChatOpenAI(openai_api_key=os.getenv("OPENAI_API_KEY"))
chain = my_prompt | llm
app = FastAPI(title="Fitness Trainer"")
add_routes(app, chain)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
On my local machine (Ubuntu 20.04.6 LTS) running Python 3.8.10, I also needed to install some additional packages to get rid of some warnings. You might not need to do this on your machine.
(venv) $ pip install sse_starlette pydantic==1.10.13
Now, we start up our server:
(venv) $ OPENAI_API_KEY=insert-key-here python3 main.py
INFO: Started server process [629848]
INFO: Waiting for application startup.
LANGSERVE: Playground for chain "/" is live at:
LANGSERVE: │
LANGSERVE: └──> /playground/
LANGSERVE:
LANGSERVE: See all available routes at /docs/
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)
Ooooh… nice!
In the browser, we can go to http://localhost:8000/docs. This is what we see:
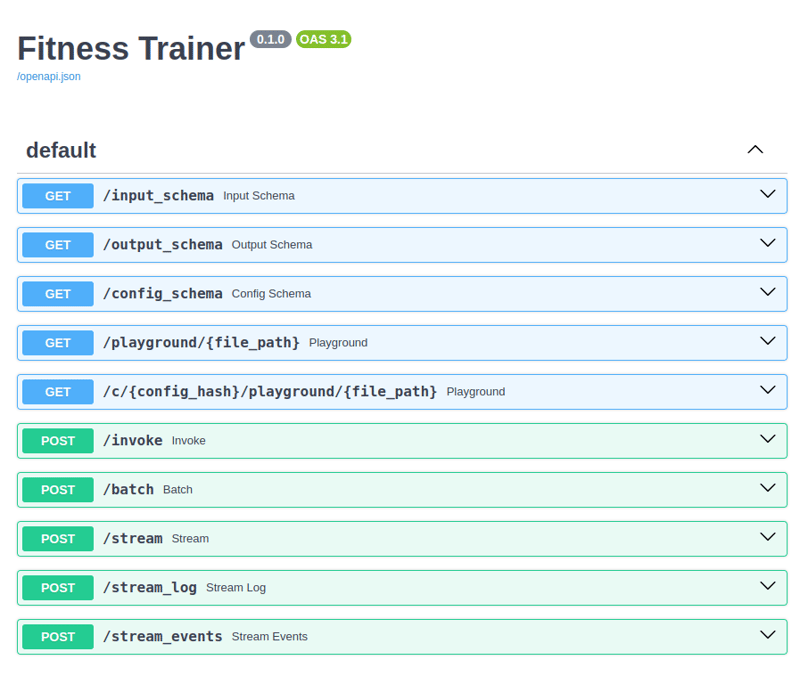
LangServe serves up an API docs page that uses a Swagger UI! These are the endpoints now available to us through LangServe. We could send a POST request to the invoke/ endpoint. But LangServe also gives us a playground/ endpoint with a web interface to work with our chain directly.
We provide an input and click Start. Here’s the result:
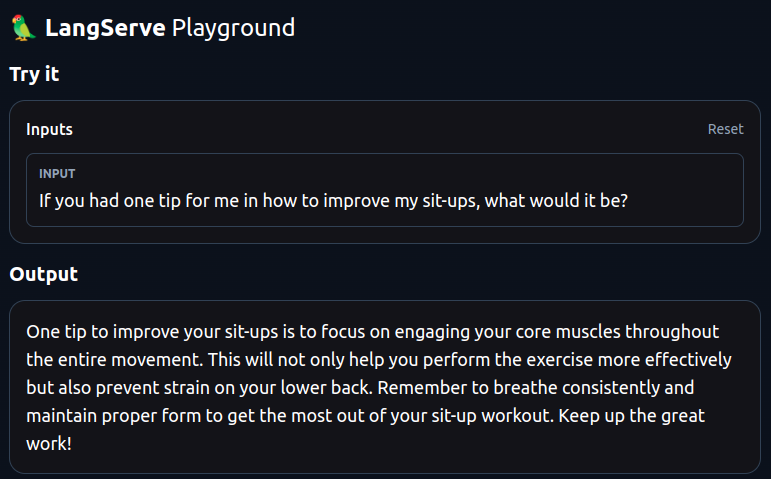
It’s important to stress the importance of having APIs in the context of LLM application workflows. If you think about it, most use cases of LLMs and applications built on top of them can’t rely on local models and resources for inference. This neither makes sense nor scales well.
The real power of LLM applications is the ability to abstract away the complex workflow we’ve described so far. We want to put everything we’ve done behind an API so the use case can scale and others can integrate it. This is only possible if we have an easy option to host and serve these APIs. And that’s where Heroku comes in.
Deploying to Heroku
Heroku is the key, final part of our LLM application implementation. We have LangChain to piece together our workflow, and LangServe to serve it up as a useful REST API. Now, instead of setting up complex resources manually to host and serve traffic, we turn to Heroku for the simple deployment of our application.
After setting up a Heroku account, we’re nearly ready to deploy. Let’s walk through the steps.
Create a new Heroku app
Using the Heroku CLI, we log in and create a new app.
$ heroku login
$ heroku create my-langchain-app
Set config variables
Next, we need to set the OPENAI_API_KEY environment variable in our Heroku app environment.
$ heroku config:set OPENAI_API_KEY=replace-with-your-openai-api-key
Create config files for Python application deployment
To let Heroku know what we need for our Python application to run, we need to create three simple files:
Procfile: Declares what command Heroku should execute to start our app.requirements.txt: Specifies the Python package dependencies that Heroku will need to install.runtime.txt: Specifies the exact version of the Python runtime we want to use for our app.
These files are quick and easy to create. Each one goes into the project’s root folder. To create the Procfile, we run this command:
$ echo 'web: uvicorn main:app --host=0.0.0.0 --port=${PORT}' > Procfile
This tells Heroku to run uvicorn, which is a web server implementation in Python.
For requirements.txt, we can use the pip freeze command to output the list of installed packages.
$ pip freeze > requirements.txt
Lastly, for runtime.txt, we will use Python 3.11.8.
$ echo 'python-3.11.8' > runtime.txt
With these files in place, our project root folder should look like this:
$ tree
.
├── main.py
├── Procfile
├── requirements.txt
└── runtime.txt
0 directories, 4 files
We commit all of these files to the GitHub repository.
Connect Heroku to GitHub repo
The last thing to do is create a Heroku remote for our GitHub repo and then push our code to the remote. Heroku will detect the push of new code and then deploy that code to our application.
$ heroku git:remote -a my-langchain-app
$ git push heroku main
When our code is pushed to the Heroku remote, Heroku builds the application, installs dependencies, and then runs the command in our Procfile. The final result of our git push command looks like this:
…
remote: -----> Discovering process types
remote: Procfile declares types -> web
remote:
remote: -----> Compressing...
remote: Done: 71.8M
remote: -----> Launching...
remote: Released v4
remote: https://my-langchain-app-ea95419b2750.herokuapp.com/ deployed to Heroku
remote:
remote: Verifying deploy... done.
This shows the URL for our Heroku app. In our browser, we visit https://my-langchain-app-ea95419b2750.herokuapp.com/playground.
We also check out our Swagger UI docs page at https://my-langchain-app-ea95419b2750.herokuapp.com/docs.
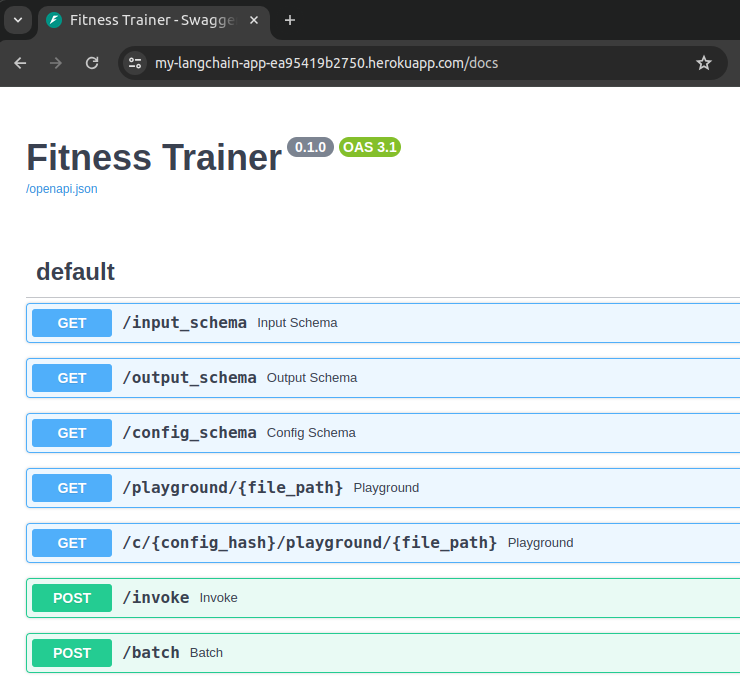
And just like that, we’re up and running!
This process is the best way to reduce developer time and overhead when working on large, complex LLM pipelines with LangChain. The ability to take APIs built with LangChain and seamlessly deploy to Heroku with a few simple command line arguments is what makes the pairing of LangChain and Heroku a no-brainer.
Conclusion
Businesses and developers today are right to ride the wave of AI and LLMs. There’s so much room for innovation and new development in these areas. However, the difference between the successes and failures will depend a lot on the toolchain they use to build and deploy these applications.
Using the LangChain framework makes the process of building LLM-based applications approachable and repeatable. But, implementation is only half the battle. Once your application is built, you need the ability to easily and quickly deploy those application APIs into the cloud. That’s where you’ll have the advantage of faster iteration and development, and Heroku is a great way to get you there.
Posted on March 18, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related