
Alex de Sousa
Posted on March 5, 2020

One of the features I really like about RabbitMQ is its queue routing. Its flexibility allows you to do interesting things without much of a hassle. But before I dig deep into RabbitMQ's routing capabilities, I would like to mention some concepts.
Connections and Channels
RabbitMQ uses not only connections, but virtual connections called channels. The idea of channels is to introduce multiplexing in a single connection. A small system could establish only one connection with RabbitMQ while opening a channel for every single execution thread e.g:
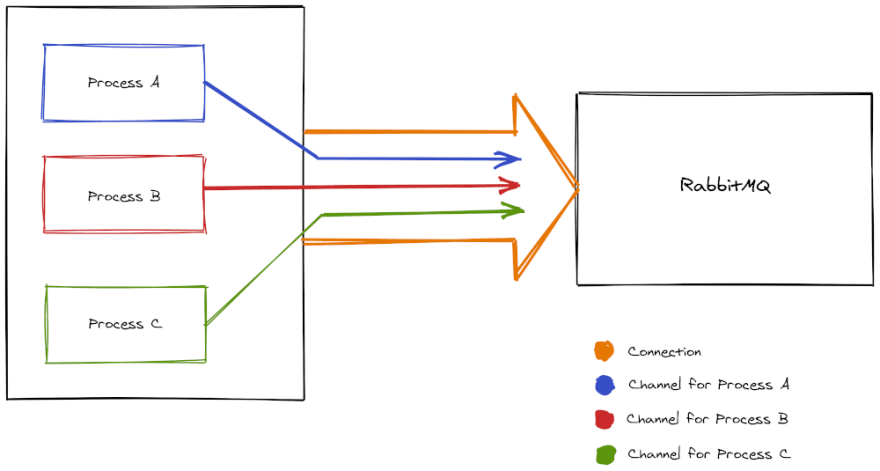
The rule of thumb would be to use:
- One connection per application.
- One channel per process in the application.
Note: Once our connection starts to be overloaded, we can start adding more connections to our connection pool.
With a normal RabbitMQ setup, we need to deal with:
- Connection pools: avoiding over consuming resources.
- Channel cleaning: avoiding channel memory leaks when they are not closed properly.
- Fault-tolerant connections: supporting re-connections in case of failure or disconnection.
- Re-connection back-off time: avoiding overloading the database on multiple re-connections.
Exchanges and Queues
An exchange is a message router. Every queue attached to it will be identified by a routing key. Typically, routing keys are words separated by dots e.g. spain.barcelona.gracia.
Additionally, routing keys support wildcards, for example: spain.barcelona.* will match messages with routing keys like spain.barcelona.gracia and spain.barcelona.raval.
It's easier to see these concepts with an image example:
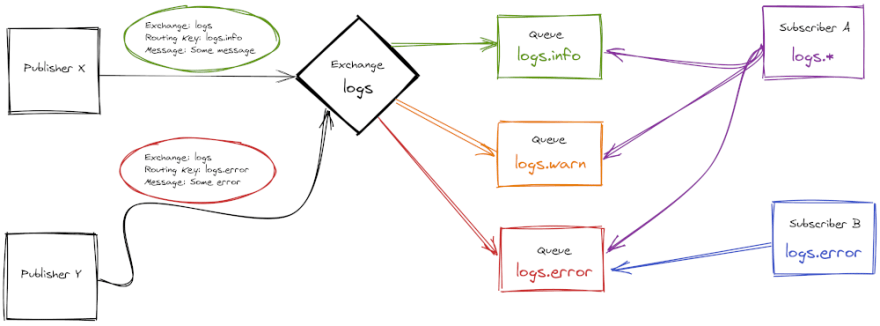
In the previous image:
- Publisher X and Publisher Y are sending messages to Exchange logs.
-
Subscriber A is subscribed to
logs.*. -
Subscriber B is subscribed to
logs.error.
Then:
-
Publisher X message will end up in Queue
logs.info. -
Publisher Y message will end up in Queue
logs.error. - Subscriber A will receive Publisher X and Publisher Y's messages.
- Subscriber B will receive Publisher Y's message.

Handling Subscriptions in Yggdrasil
Handling RabbitMQ's complexity might be intimidating. Fortunately, Yggdrasil for RabbitMQ generalizes the complexity in order to have a simpler API.
The biggest difference with previous adapters is the channel name. Instead of being a string, it's a tuple with the exchange name and the routing key e.g:
A subscriber would connect to the exchange amq.topic using the routing key logs.* as follows:
iex(subscriber)> Yggdrasil.subscribe(name: {"amq.topic", "logs.*"}, adapter: :rabbitmq)
iex(subscriber)> flush()
{:Y_CONNECTED, %Yggdrasil.Channel{...}}
Note: The exchange must exist and its type should be
topic. The exchangeamq.topicis created by default in RabbitMQ.
Then a publisher could send a message to the exchange amq.topic using logs.info as routing key:
iex(publisher)> Yggdrasil.publish([name: {"amq.topic", "logs.info"}, adapter: :rabbitmq], "Some message")
:ok
Finally, the subscriber would receive the message:
iex(subscriber)> flush()
{:Y_EVENT, %Yggdrasil.Channel{...}, "Some message"}
Additionally, the subscriber can be written using the Yggdrasil behaviour:
defmodule Logs.Subscriber do
use Yggdrasil
def start_link(options \\ []) do
channel = [
name: {"amq.topic", "logs.*"},
adapter: :rabbitmq
]
Yggdrasil.start_link(__MODULE__, [channel], options)
end
@impl true
def handle_event(_channel, message, _state) do
... handle event ...
{:ok, nil}
end
end
Lost Messages
Yggdrasil will acknowledge the messages as soon as they arrive to the adapter, then it will broadcast them to all the subscribers. If the adapter is alive while the subscribers are restarting/failing, some messages might be lost.
Though it's possible to overcome this problem with exclusive queues, this feature is not implemented yet.
Conclusion
Yggdrasil for RabbitMQ handles RabbitMQ complexity let's you focus in what really matters: messages.
Cover image by Aswathy N
Posted on March 5, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related