An Overview of Distributed Programming and Systems

Alex Alves
Posted on January 29, 2024
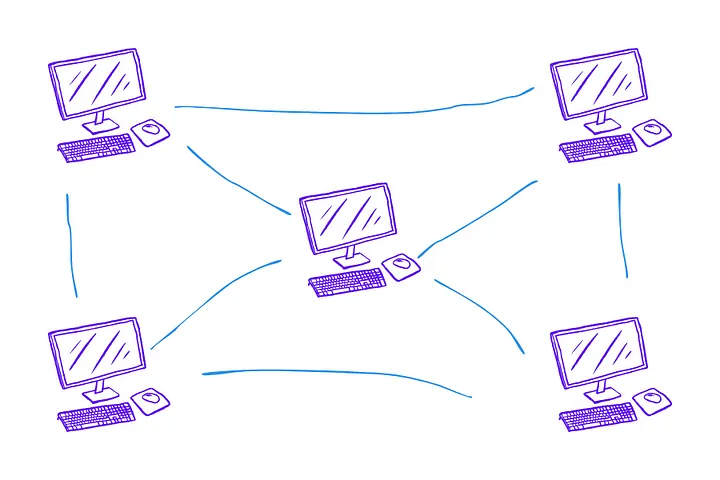
A simple way to define/describe is the same system can be executed in many environments, where you can distribute the execution/process of some flow. Besides this, you need to build algorithms that can be executed in this environment. Let’s see some overview concepts, below!
Why is this important?
When you work with high processing power, distributing it is an excellent way to improve the utilization of computational resources without spending all your resources on the machine. You allow your system to process things in different environments/nodes/machines/servers.
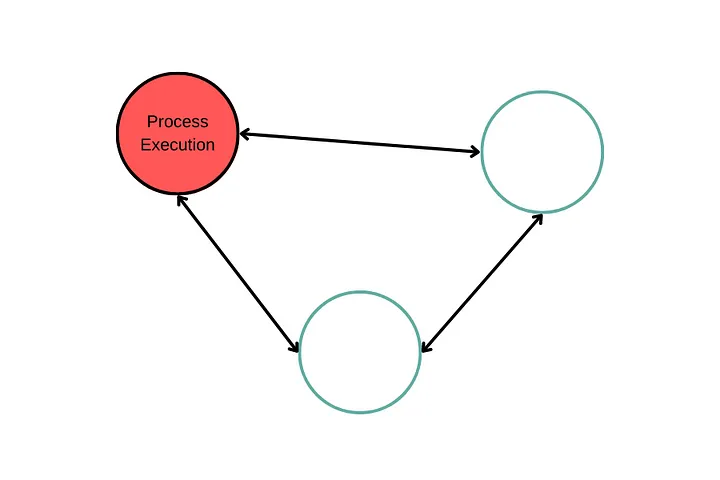
When we use a non-distributed architecture, we have just one POD/VM (the first called) to execute all the flow:
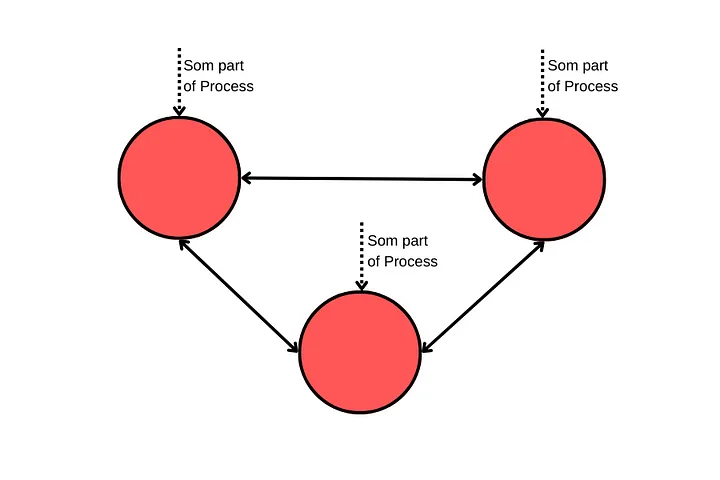
On the other hand, when we use distributed architecture, we can divide the responsibility to execute all the processes. Where we use all PODs/VMs to do this:
Distributed programming is the art of solving the same problem that you can solve on a single computer using multiple computers. [Mikito Takada]
Pros
- Horizontal Scalability
- Availability: failures do not impact other modules/services
- Performance: distributed tasks may get a great result
- Resilience: distributed processes and data may be more failure resistance
Cons
- Complexity: requires advanced knowledge about distributed programming, network, and resource manager
- Consistency: mainly in a high concurrency
- Communication: may introduce latency when transmitting some data
- Infrastructure: you should know about networking to define the best way to reduce latency, cost, and degradation
Topologies
When we talk about distributed systems, we talk about strategies for following, and we need to answer the following question by ourselves:
* Are we confident in the system/service, to process some piece of journey/flow correctly?
If the answer is “yes”, we don’t need some app to control the flow, we need to accept it, and we will get a decentralized system. If the answer is “no”, we need something to control all the journey/flow, to tell which service/environment will execute something, and then we'll get a centralized system. Both are distributed but in different ways (or Topologies). Let’s talk about it!
Broker (Decentralized)
The message flow is distributed across the journey/components. This topology is very useful if you do not want a central event orchestration. You only need to broadcast the message, someone consumes it and propagates another message, without other components knowing about the process. It’s all about the chaining of events. And, to see what happens if an event is published, you need an “alive documentation” to demonstrate it, like an EventStorming.
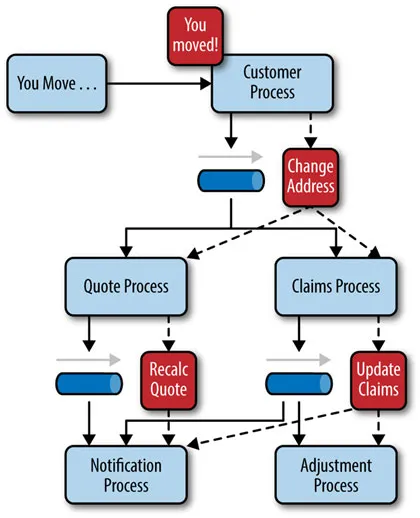
Points to Consider
🔴 Monitoring complexity
🔴 Debbuging complexity
🔴 Error handling
🟢 Decoupling
🟢 Flexibility
🟢 Scalability
🟢 High throughput
Mediator (Centralized)
It is useful if you need some level of orchestration, like when you will do a rollout process (migrate functionalities of legacy to new application). Here, you have to pay attention to SPOF (Single Point of Failure), because all the processes will depend on your orchestration. Here we maybe see the Request-Reply pattern, in which the orchestration needs to wait for the service reply when he calls it.
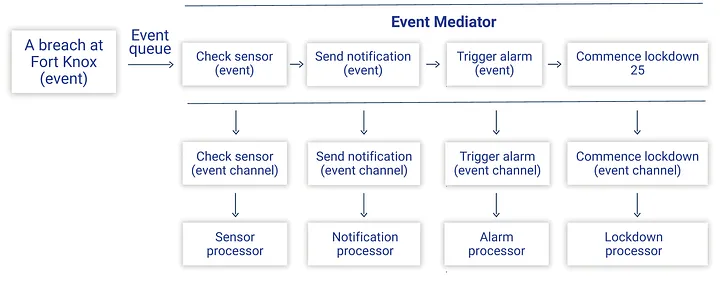
Points to Consider
🔴 Single Point of Failure (SPOF)
🔴 Scalability limitations
🔴 Performance overhead
🔴 Over-coupling
🟢 Clearer visibility
🟢 Simplified error handling
🟢 Improved security
Sagas
This is a pattern that helps us to do rollbacks in “distributed transactions”, used in both topologies like Choreographic (to broker topology) and Orchestration (to mediator topology).
Choreographic
When a process fails, the service publishes an event of failure, and all interested services consume it to do something (like "revert"), using the "compensation event" concept.
Orchestration
Is almost the same thing as Choreographic, except it controls the failure service and calls directly all other points to "revert".
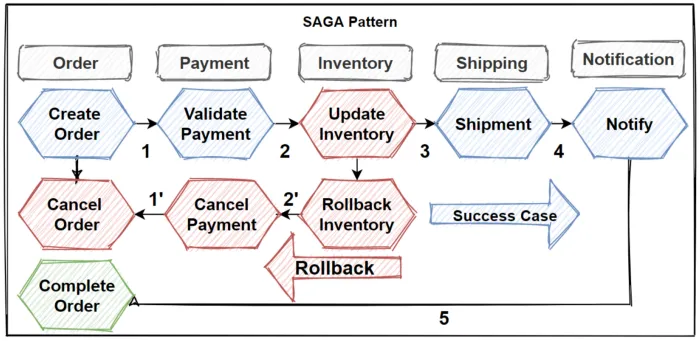
In other words, we don’t have a real rollback, just a “compensation event”, because the side effects have already happened. And, looking at this we observe how this strategy impacts the system coordination and consistency. As the topology models the components' interaction, let’s see below how can we use the concurrency control to guarantee the consistency and integrity of each service.
Concurrency Controls
It's something like a mechanism that ensures to control of multiple concurrent transactions. It thinks about the conflicts and how we can maintain data consistency.
Optimistic
This strategy considers the best scenarios possible because it assumes will happen infrequently and allows transactions to happen unsynchronized. However, you need to guarantee that the conflicts that will have don’t affect your system. Whether through exceptions or the ordering of actions that will happen, for example.
Pessimistic
On the other hand, you can use a blockade strategy. In this case, we assume that conflicts will happen frequently and we block the part of the code for the first client to use it. We can use thread local safe or distributed lock for this, using something like Redis.
The best practice to choose will depend of to know which how you will send and receive requests. For this, let’s see some high-level protocols.
Communication Protocols
Let's see some useful protocols that we can use in Distributed Architecture:
HTTP/HTTPS
- Client-Server communication: allows to segregate tasks between client and server
- Stateless: each request is independent
- Scalability: easy server replication
RPC
- Transparent Integration: call remote functions as local functions
- Network Abstraction: you do not need to care about the subjacent networks
- Concurrency Manager: allows control of transactions and distributed locks
MQ (Message Queue)
- As AMQP or MQTT
- Decoupling and Asynchronism: A component can send a message without waiting for your processing
- Fault Tolerance: Ensure message delivery even if systems are temporarily unavailable
- Load Balance: Allows to distribute messages in many server instances
- Integration of Heterogeneous Systems: Programming language agnostic
Now, let’s see how we can use all these things together in an architecture/code design
Architectures/Patterns
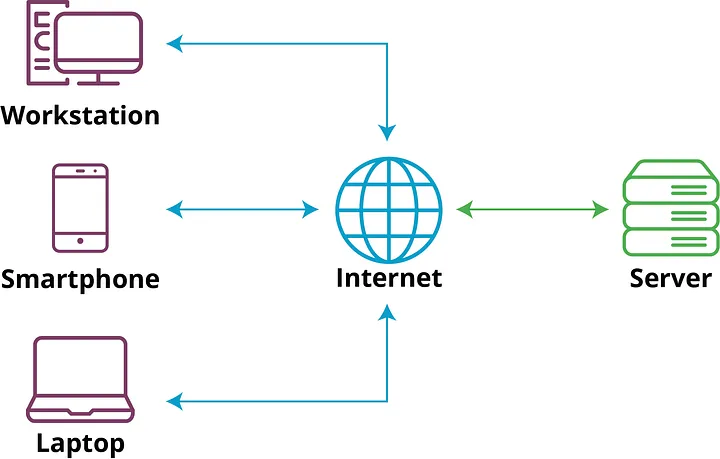
Client-Server
It is when you divide the application into two, client and server. The client is the part that is responsible for interacting with the end user, and the server provides all the client requests. The client can be software in a mobile phone or web application, and the server can be a dedicated machine. We need to pay attention to a single point, which every request on the server needs a response, so the clients wait for the server to process the request.
Service-Oriented Architecture
A way to goal organize a system with interconnected services. Service in this context is autonomous, independent, and exposed. Following the Distributed System, we can distribute different tasks to different services.
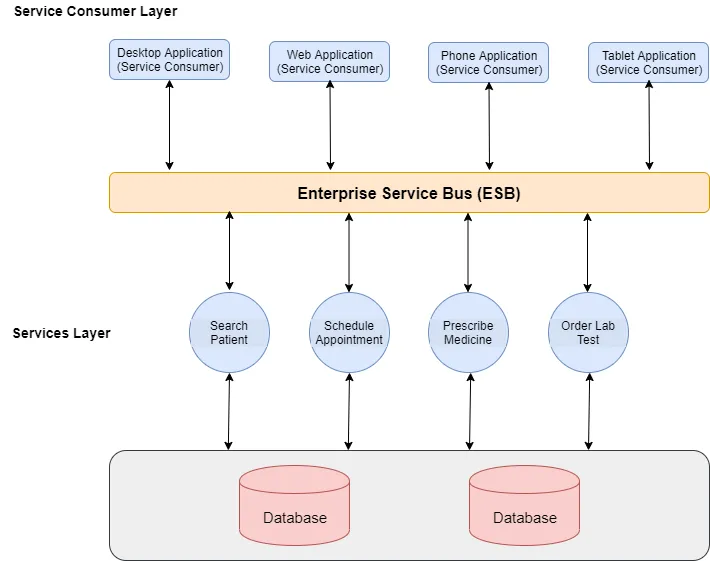
Microservices
This pattern almost follows the same way as SOA, but the difference is how the Consumer Layer uses the services. In this case, we do not need the ESB, the services are so independent that the Consumer Layer uses it directly and their infrastructure is just for itself.
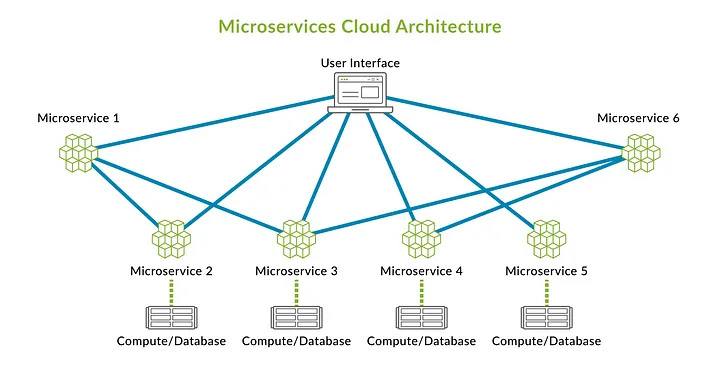
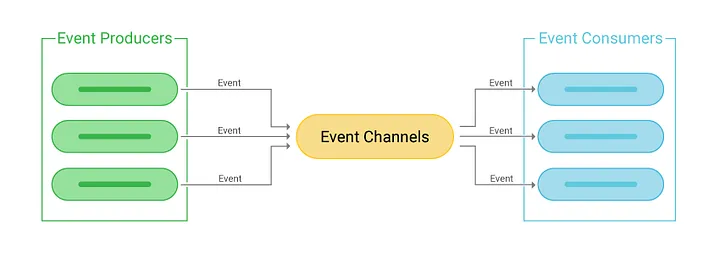
Event-Driven Architecture
We can do this pattern in different scenarios, from Monolithic to Microservice. The idea is to use the MQ protocol to do async communication, in which we can use the load balance strategy and redirect all the charges to the infrastructure, like Message Brokers. This is useful for distributing the same task process to different server instances.
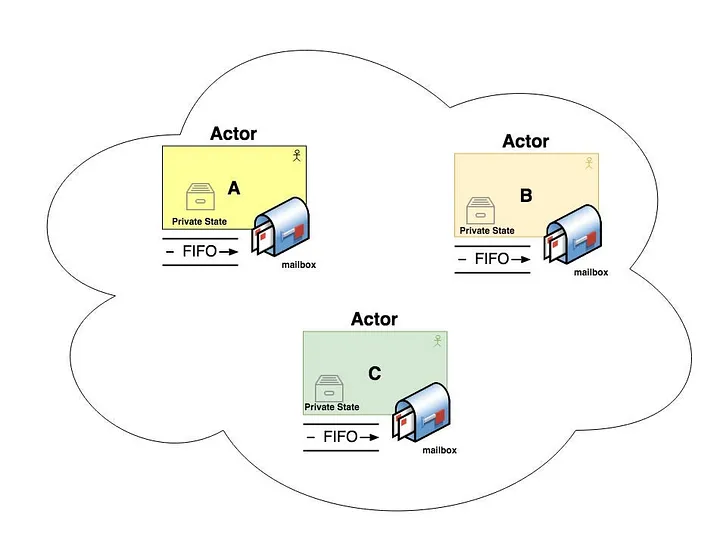
Actor Models
This pattern is based on Actors, in which each actor is an independent unit and your interactions are by messages. This kind of architecture works with a stateful strategy, and for this is very performative.
Conclusions
We need to recognize this way brings us some benefits, like resilience, scalability, and performance. But we need to see the complexity and challenges that exist, too, like architectural decisions, concurrency controls, and protocol management. For this, we can look at the CAP Theorem, which may help us choose between consistency, availability, and fault tolerance.
The comprehension of these trade-offs helps us to decide the best way to follow and the best alignment between the tech team and product team.
PS: This article brings us an overview of the distributed system, we did not go deep into any concepts. For this, we require a deeper study.
Abbreviations / Significates
- SPOF: Single Point Of Failure
- POD: Kubernetes abstraction that represents a group of one or more application containers, and some shared resources for those containers
- VM: Virtual Machine
- RPC: Remote Procedure Call
- AMQP: Advanced Message Queuing Protocol
- MQTT: Message Queuing Telemetry Transport
- ESB: Enterprise Service Bus
References
- Chapter 10: Distributed Architecture, Decentralized Architecture, and Federated Social Networks
- Distributed Architecture
- DISTRIBUTED PROGRAMMING: WHAT IT IS AND WHERE IT IS USED
- 4. Distributed Programming
- Optimistic vs Pessimistic Concurrency
- Variations in Event-Driven Architecture
- Microservices
- Event-Driven Architecture Topologies Broker and Mediator
Posted on January 29, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.