Recurrent neural networks: The powerhouse of language modeling

Adam
Posted on June 9, 2019
During the spring semester of my junior year in college, I had the opportunity to study abroad in Copenhagen, Denmark. I had never been to Europe before that, so I was incredibly excited to immerse myself into a new culture, meet new people, travel to new places, and, most important, encounter a new language. Now although English is not my native language (Vietnamese is), I have learned and spoken it since early childhood, making it second-nature. Danish, on the other hand, is an incredibly complicated language with a very different sentence and grammatical structure. Before my trip, I tried to learn a bit of Danish using the app Duolingo; however, I only got a hold of simple phrases such as Hello (Hej) and Good Morning (God Morgen).
When I got there, I had to go to the grocery store to buy food. Well, all the labels there were in Danish, and I couldn’t seem to discern them. After a long half hour struggling to find the difference between whole grain and wheat breads, I realized that I had installed Google Translate on my phone not long ago. I took out my phone, opened the app, pointed the camera at the labels… and voila, those Danish words were translated into English instantly. Turns out that Google Translate can translate words from whatever the camera sees, whether it is a street sign, restaurant menu, or even handwritten digits. Needless to say, the app saved me a ton of time while I was studying abroad.
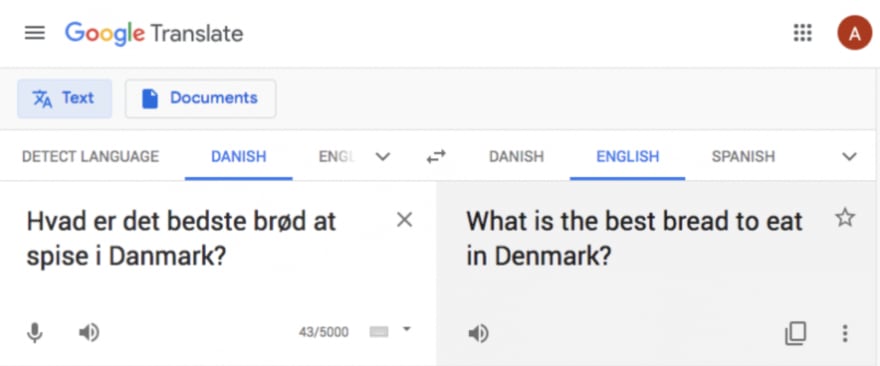
Google Translate is a product developed by the Natural Language Processing Research Group at Google. This group focuses on algorithms that apply at scale across languages and across domains. Their work spans the range of traditional NLP tasks, with general-purpose syntax and semantic algorithms underpinning more specialized systems.
Looking at a broader level, NLP sits at the intersection of computer science, artificial intelligence, and linguistics. The goal is for computers to process or “understand” natural language in order to perform tasks that are useful, such as Sentiment Analysis, Language Translation, and Question Answering. Fully understanding and representing the meaning of language is a very difficulty goal; thus it has been estimated that perfect language understanding is only achieved by AI-complete system. The first step to know about NLP is the concept of language modeling.
Language Modeling
Language Modeling is the task of predicting what word comes next. For example, given the sentence “I am writing a …”, the word coming next can be “letter”, “sentence”, “blog post” … More formally, given a sequence of words x(1), x(2), …, x(t), language models compute the probability distribution of the next word x(t+1).
The most fundamental language model is the n-gram model. An n-gram is a chunk of n consecutive words. For example, given the sentence “I am writing a …”, then here are the respective n-grams:
-
unigrams: “I”, “am”, “writing”, “a”
-
bigrams: “I am”, “am writing”, “writing a”
-
trigrams: “I am writing”, “am writing a”
-
4-grams: “I am writing a”
The basic idea behind n-gram language modeling is to collect statistics about how frequent different n-grams are, and use these to predict next word. However, n-gram language models have the sparsity problem, in which we do not observe enough data in a corpus to model language accurately (especially as n increases).
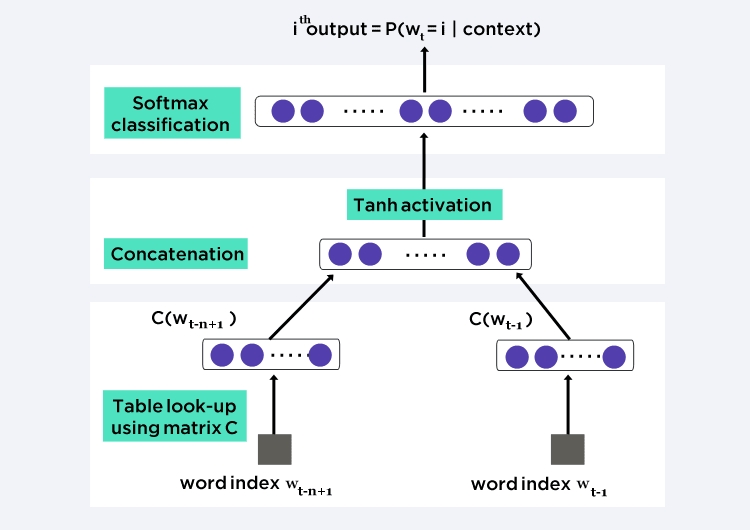
Instead of the n-gram approach, we can try a window-based neural language model, such as feed-forward neural probabilistic language modelsand recurrent neural network language models. This approach solves the data sparsity problem by representing words as vectors (word embeddings) and using them as inputs to a neural language model. The parameters are learned as part of the training process. Word embeddings obtained through neural language models exhibit the property whereby semantically close words are likewise close in the induced vector space. Moreover, recurrent neural language model can also capture the contextual information at the sentence-level, corpus-level, and subword-level.
Recurrent Neural Net Language Model
The idea behind RNNs is to make use of sequential information. RNNs are called recurrent because they perform the same task for every element of a sequence, with the output depended on previous computations. Theoretically, RNNs can make use of information in arbitrarily long sequences, but empirically, they are limited to looking back only a few steps. This capability allows RNNs to solve tasks such as unsegmented, connected handwriting recognition or speech recognition.
Let’s try an analogy. Suppose you are watching Avengers: Infinity War (by the way, a phenomenal movie). There are so many superheroes and multiple story plots happening in the movie, which may confuse many viewers who don’t have prior knowledge about the Marvel Cinematic Universe. However, you have the context of what’s going on because you have seen the previous Marvel series in chronological order (Iron Man, Thor, Hulk, Captain America, Guardians of the Galaxy) to be able to relate and connect everything correctly. It means that you remember everything that you have watched to make sense of the chaos happening in Infinity War.

Similarly, RNN remembers everything. In other neural networks, all the inputs are independent of each other. But in RNN, all the inputs are related to each other. Let’s say you have to predict the next word in a given sentence, the relationship among all the previous words helps to predict a better output. In other words, RNN remembers all these relationships while training itself.
RNN remembers what it knows from previous input using a simple loop. This loop takes the information from previous time stamp and adds it to the input of current time stamp. The figure below shows the basic RNN structure. At a particular time step t, X(t) is the input to the network and h(t) is the output of the network. A is the RNN cell which contains neural networks just like a feed-forward net.
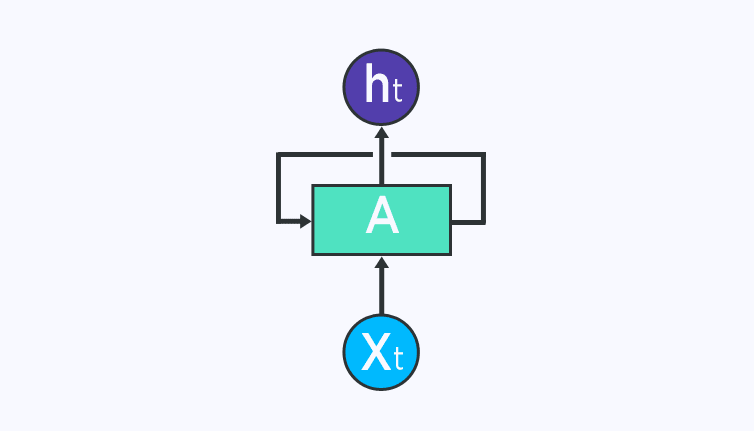
This loop structure allows the neural network to take the sequence of the input. If you see the unrolled version below, you will understand it better:
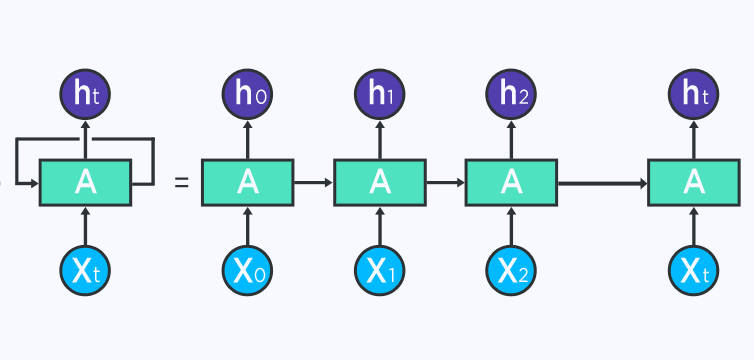
First, RNN takes the X(0) from the sequence of input and then outputs h(0)which together with X(1) is the input for the next step. Next, h(1) from the next step is the input with X(2) for the next step and so on. With this recursive function, RNN keeps remembering the context while training.
If you are a math nerd, many RNNs use the equation below to define the values of their hidden units:

of which h(t) is the hidden state at timestamp t, ∅ is the activation function (either Tanh or Sigmoid), W is the weight matrix for input to hidden layer at time stamp t, X(t) is the input at time stamp t, U is the weight matrix for hidden layer at time t-1 to hidden layer at time t, and h(t-1) is the hidden state at timestamp t.
RNN learns weights U and W through training using back propagation. These weights decide the importance of hidden state of previous timestamp and the importance of the current input. Essentially, they decide how much value from the hidden state and the current input should be used to generate the current input. The activation function ∅ adds non-linearity to RNN, thus simplifying the calculation of gradients for performing back propagation.
RNN Disadvantage
RNNs are not perfect. It suffers from a major drawback, known as the vanishing gradient problem, which prevents it from high accuracy. As the context length increases, layers in the unrolled RNN also increase. Consequently, as the network becomes deeper, the gradients flowing back in the back propagation step becomes smaller. As a result, the learning rate becomes really slow and makes it infeasible to expect long-term dependencies of the language. In other words, RNNs experience difficulty in memorizing previous words very far away in the sequence and is only able to make predictions based on the most recent words.
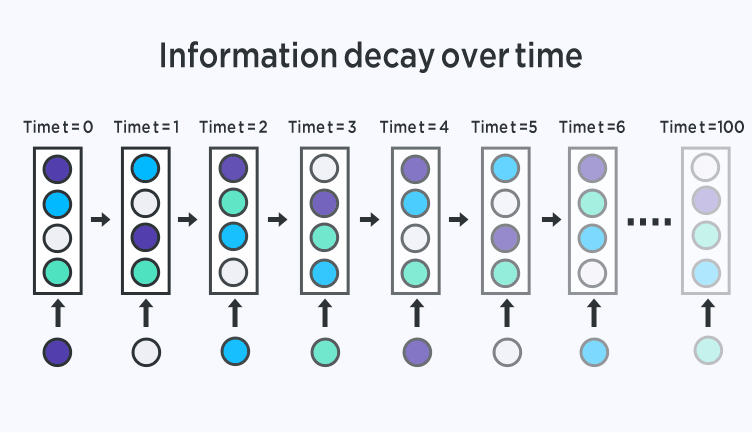
RNN Extensions
Over the years, researchers have developed more sophisticated types of RNNs to deal with this shortcoming of the standard RNN model. Let’s briefly go over the most important ones:
-
Bidirectional RNNs are simply composed of 2 RNNs stacking on top of each other. The output is then composed based on the hidden state of both RNNs. The idea is that the output may not only depend on previous elements in the sequence but also on future elements.
-
Long Short-Term Memory Networks are quite popular these days. They inherit the exact architecture from standard RNNs, with the exception of the hidden state. The memory in LSTMs (called cells) take as input the previous state and the current input. Internally, these cells decide what to keep in and what to eliminate from the memory. Then, they combine the previous state, the current memory, and the input. This process efficiently solves the vanishing gradient problem.
-
Gated Recurrent Unit Networks extends LSTM with a gating network generating signals that act to control how the present input and previous memory work to update the current activation, and thereby the current network state. Gates are themselves weighted and are selectively updated according to an algorithm.
-
Neural Turing Machines extend the capabilities of standard RNNs by coupling them to external memory resources, which they can interact with through attention processes. The analogy is that of Alan Turing’s enrichment of finite-state machines by an infinite memory tape.
Read more about Recurrent Neural Networks on Built In.
Posted on June 9, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related




November 30, 2024