
Anthony Accomazzo
Posted on September 19, 2023

We knew building a database proxy would be hard. We wanted to find any other way to achieve our mission. But alas, after looking at all the options, only one solution remained standing.
Below, I'll share our journey to the inescapable conclusion.
Perhaps async writes will be good enough?
When we started Sequin, we had a one-way sync from third-party APIs to Postgres databases. Our hypothesis was that when working with third-party APIs, just reading all your data from a database is way easier than from an API. You can use SQL or your favorite ORM, don't have to worry about rate limits or latency, and don't have to worry about availability.
Reading through the database worked so well that we wanted to see if we could make writes work through the database too.
So we added database writes. We'd monitor your database for changes and send those changes to the API. The process ran async, completing just a couple of seconds after you committed your write.
After seeing customers adopt and scale with async writes, it was confirmed: writing back to the API via SQL is amazing. But the async part was causing a lot of problems.
For example, you write to Postgres. Let’s say you’re updating the email on a Salesforce contact. The write succeeds. But it's totally unknown to you if and when that change will make it to the API. Inserting, updating, or deleting a record in Postgres is like creating a job or a "promise" that you are hoping would resolve in a successful API write in the future.
The API is ultimately the source of truth. You need the API to approve your mutation. Writes are where APIs enforce their policy. You want to know about validation errors when they happen – like if the contact you’re updating has an invalid email – so you can handle them in code.
When developing on an API, an async experience like this is tough. You craft your mutation in your Postgres client and commit it. Then, you have to go check somewhere else to monitor the progress of your request – be it the audit table or a dashboard somewhere.
Furthermore, this approach means changes can originate in two places and that you have two nodes that can drift apart.
We were removing the HTTP API but replacing it with a classically hard distributed systems problems. For example: if a change fails API validation, do we roll it back? What if there were other changes stacked on top of this one? Or what if drift occurred between the time when the developer committed the Postgres change and we made the subsequent API request?
Synchronous, but at what cost?
We grew weary of async writes. It felt like we were close, but hadn't found the winning solution yet.
Ideally, we wanted the API to continue to act as the validation layer for commits. And for the API to be the source of truth, with Postgres as a simple follower database.
We wanted synchronous writes. But inside of Postgres' transactional model, we didn't see a way to make this happen.
So, we began exploring.
Requirements
Our requirements were driven by the fact that we wanted writes to be synchronous, so errors would be easy to see and handle. And that we wanted to be compatible with all Postgres clients, including ORMs:
- Support for
insert,update, anddelete. - Support for
returningclauses.returningclauses are often necessary for inserts, where you need to do something with the row you just inserted. And indeed several ORMs rely on these clauses to operate. 1 - A commit must translate to a single API request. This was the simplest way to avoid weird inconsistent state. 2
- Errors must happen during the commit. If the operation fails, the user should receive a Postgres error.
Notably, we decided that batch operations were a "nice to have." Many transactional workflows operate on only a single row at a time. Batch operations would be most common in one-off workflows. If we had to give them up for synchronous writes, we would.
Option: Synchronous replication
Postgres supports streaming replication to other Postgres databases. In streaming replication, Postgres sends the WAL stream over a network connection from the primary to a replica.
When streaming replication is set to synchronous mode, the primary will wait for any or all replicas to confirm they committed the data.
Instead of streaming the WAL to another Postgres database, we could stream the WAL synchronously to our application server. Instead of committing the changes to a database, it would attempt to commit them to the API. If it failed to do so, it could raise an error, which would trickle up to and break the transaction.
However, this wasn't going to meet our requirements.
Let's start by considering a success case: the customer inserts a record into the database, the new record streams to us through the WAL, we commit the new record to the API, and the API accepts the insert.
We now need to update the database with the record returned by the API. Importantly, the API response body includes the record’s API ID. It also may contain other fields not sent in our request, like calculated fields or timestamps.
In synchronous replication, we can only update the row with the result from the API after the commit has happened. That’s because another process is responsible for writing the changes back:
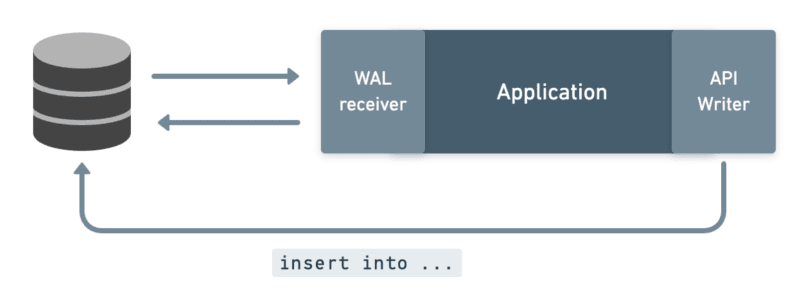
So while we hear about the commit as it’s happening – and can interrupt the commit if it fails – we still can't fit our whole operation neatly into the commit. We have to wait for the commit to finish – and therefore for the row to become available/unlocked – before we can update it with the API response.
This means we can’t meet two requirements.
The first is that there is no way for us to support a returning clause. The row needs to be modified before it's committed if you want to reflect the updated row in the fields returned to the client. You can only do that in a "before each row" trigger or in a rewrite rule.
The second issue is related: when the record will be updated with the API response is really indeterminate! If the client can't rely on a returning clause, they may opt to do a read-after-write: after writing the record, immediately read it. But again, because the update is not happening coincident with the commit, there's no telling if that subsequent read will "beat" whatever process we have writing back the API's response to the row.
In addition, in the failure case where the API rejects the changes, we weren't confident we could craft the right Postgres errors to percolate up to the client. (Unconfirmed, as we'd already eliminated this option.)
Option: Foreign data wrappers
Foreign data wrappers were another serious contender.
Foreign data wrappers (FDWs) are a Postgres feature that allow you to both read from and write to external data sources. The architecture that they model felt very similar to what we were building: the data source you're writing to doesn't live in your database, it lives over the wire (the API). This was encouraging.
While you can build your own FDWs, most cloud providers do not let you load arbitrary extensions into their managed databases. This was the first rub: in order to support our numerous customers on AWS' or GCP's managed Postgres databases, we couldn't create our own foreign data wrapper extension.
Instead we’d need to use Postgres’ built-in FDW, postgres_fdw. With postgres_fdw, you can connect two Postgres databases and create something like a view in one Postgres database that references a table in another Postgres database.
These foreign tables behave exactly like local tables. You can select, insert, update, delete, and join all the same.
When you setup postgres_fdw, under the hood you're turning one Postgres database into a client and the other into a server. When you make queries against foreign tables, the client database sends the queries to the server database via Postgres' wire protocol.
To make postgres_fdw work, we'd setup a Postgres wire protocol compliant server. That server would act as a fake Postgres database. By fitting into the model of the standard postgres_fdw, we'd have the widest compatibility:
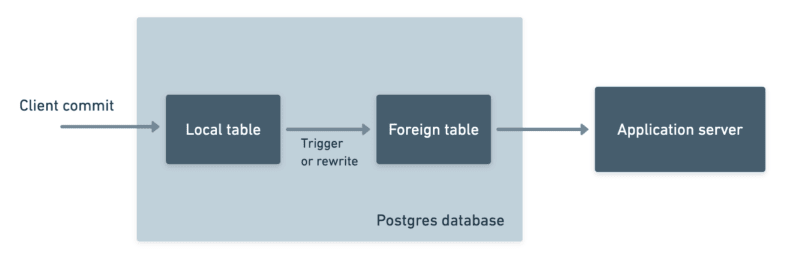
Like synchronous replication, we had to find a way to use postgres_fdw inside of Postgres' standard commit flow to deliver the experience we wanted. And like synchronous replication, we ran into limitations.
The most notable limitation was with postgres_fdw itself.
With update and delete queries, the client Postgres sends the query as-is to the server. This makes sense – the client Postgres doesn't store any of the rows. So when you run an update or delete, it has to fully delegate the operation to the server. This is exactly what we wanted, because it gives us full control. The client Postgres database is proxying requests to our server, allowing us to have full control over how they are executed.
But insert queries were a different story. In specific situations, postgres_fdw does not support batch inserts. The biggest drag is that it does not support batch inserts when a returning clause is specified.
In these situations, the query doesn't fail (which for our purposes would be preferable). Instead, postgres_fdw will rewrite the batch insert, turning it into multiple single row inserts:
-- original query sent by the client…
insert into orders (order_id, product_name, quantity)
values (1, 'Product A', 30), (2, 'Product B', 20);
-- is split into two queries before being sent to the foreign Postgres server
insert into orders (order_id, product_name, quantity)
values (1, 'Product A', 30);
insert into orders (order_id, product_name, quantity)
values (2, 'Product B', 20);
This is unfortunate because both the user and foreign server are blind to the fact that their batch insert is actually being translated into a bunch of serial inserts. Likewise, on the server, when we receive an insert we have no way of knowing that another is about to follow as part of a batch.
With postgres_fdw, all operations happen inside of a transaction. So, for batch inserts, you might think: can't we just "ack" each inserted row as it's received, storing it in memory. Then, at the end of the transaction, go write all the rows to the API? But then we'd violate our requirement to fully support returning clauses – because our only opportunity to affect the row returned to the client is when we receive each individual insert query. We can't return dummy data for each insert query, then at the end of the transaction say: "never mind all those rows I just sent you – here are the real rows you should return."
Ideally, we'd be able to detect when a customer was attempting to make a batch insert with a returning clause and return a helpful error. But that’s not possible.
So, foreign data wrappers in the general sense wouldn't work for us because we can't install our own FDWs on managed databases. And using postgres_fdw felt clever, but put us downstream of an extension that we had little control over.
We briefly surveyed other options, including far-out projects like pgsql-http. But no matter what we looked at, it was clear: we couldn't do what we needed to do behind the database (synchronous replication). And we couldn't do what we needed to do inside the database (FDWs).
We'd need to get in front of it.
Landing on the Postgres proxy
To get in front of the database, we'd need to build a proxy:

It felt like the biggest lift, but also came with the biggest guarantee that we could get the experience we wanted:
- We’d be able to support
insert,update, anddelete, including batches. - We’d be able to fully support
returningclauses, returning the response that we received from the API after performing the mutation request. - We’d have full control over the Postgres errors that we returned to the client.
To pull this off, we’d need to add an additional requirement, which was that the proxy would need to work seamlessly with all Postgres clients. That meant adhering to Postgres' wire protocol.
A standard Postgres proxy like Pgbouncer doesn't need to know much about Postgres' wire protocol beyond authentication. After a client establishes a connection to Pgbouncer, Pgbouncer opens connection to the Postgres database. These connections reside in a pool. When a client sends a statement or transaction, Pgbouncer checks out a connection from the pool and uses that connection for the duration of the statement or transaction.
But once a client's connection is paired with a database connection, Pgbouncer doesn't need to know much about what's going on. The proxy simply passes TCP packets back and forth between the two. All the while, it's looking for one particular message from the server to the client (the ReadyForQuery message). When it sees that message, it knows whatever the client and server were working on is completed, and it's able to release the database connection back into the pool.
We thought to achieve our goal, our proxy might not need to know too much about what was going on either.
Boy, were we wrong.
As we expanded our proxy to cover the surface area of Postgres operations, our proxy had to become more and more fluent in the Postgres protocol.
Eventually, our proxy became a fluent Postgres server. The specification of the Postgres protocol is concise, leaving room for interpretation. In that room, client quirks have blossomed, and our proxy had to adapt to handle all of them. 3
The proxy also had to become a fluent Postgres client. We have to inject our own queries into the client/server dance to capture changes.
Just like a Postgres server or client, our proxy keeps an internal state machine for all connections to ensure we know precisely where we are in a statement or transaction flow. We know the state of the client connection and of the server connection and what we need to do to safely progress to the next state with each.
(More on our proxy's design in a future post!)
The experience we always wanted
While it was a journey to decide to build the proxy and another journey to build it, we ended up with a solution that gives us much more control. That meant building the experience we'd been looking for.
When you make an insert, update, or delete to a Sequin-synced table, we're able to check the batch size of your query. If you're operating on more records than we can modify in a single API request, we'll return an error. Otherwise, we'll commit the changes to the API. If the API request succeeds, we'll commit your changes to the database and complete your query – including fulfilling your returning clause if you had one. If the API request fails, we'll rollback the changes in your database and return a helpful Postgres error to your client.
Some 80%+ of the operations we all perform on APIs are just standard CRUD. SQL or your favorite ORM is a great interface for CRUD, and far easier and faster to use than an HTTP API. It's such a cool experience, and we love seeing customers' reactions every time they get to play with it.
If you’re curious to give it a whirl for yourself, sign-up for a free trial. Otherwise, be sure to subscribe to our blog to catch future posts where we detail how our Postgres proxy works.
-
The row the database returns must reflect the row we upsert after getting a response from the API. That means it will be fully populated, with a canonical ID and the like. ↩
-
For example, imagine if it took us 5 API requests to perform all the mutations in a single commit. What happens if the third API request fails validation? The commit was only partially committed to the API, but in Postgres it's all-or-nothing. ↩
-
One example: some clients send an empty
SimpleQuerymessage as a keep alive. An emptySimpleQueryis strange. ASyncis better suited for this purpose. ↩
Posted on September 19, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related




