Jordan Scrapes Secretary of State: Vermont

Jordan Hansen
Posted on July 21, 2020
I continued down the United State from Maine to web scrape the Vermont Secretary of State. I’ve never been to Vermont and I don’t know much about it. It’s in the north eastern part of the United States and so I’m sure it’s very beautiful.
This is the 14th (!) state in the Secretary of State Scraping Series. There were some parts that were tricky but it wasn’t one of the more difficult scrapes like Delaware (gross).
Investigation

I try to look for the most recently registered businesses. They are the businesses that very likely are trying to get setup with new services and products and probably don’t have existing relationships. I think typically these are going to be the more valuable leads.
If the state doesn’t offer a date range with which to search, I’ve discovered a trick that works pretty okay. I just search for “2020”. 2020 is kind of a catchy number and because we are currently in that year people tend to start businesses that have that name in it.
Once I find one of these that is registered recently, I look for a business id somewhere. It’s typically a query parameter in the url or form data in the POST request. Either way, if I can increment that id by one number and still get a company that is recently registered, I know I can find recently registered business simply by increasing the id with which I search.
With Vermont I did things a little bit differently. The Vermont business search looks like this:

It’s kind of cool that you can specify the industry for which you are looking. Once I found a business listing in Vermont, I could easily see from the URL that using incrementing ids was probably going to work great.

I used code to find the end this time though. It looks like these two functions to help me narrow it down.
// Find where the end is by 10000
for (let i = 0; i < 15; i++) {
await getDetails(startingId + (i * 10000));
await timeout(2000);
}
// Find where the end is by 2500
for (let i = 0; i < 15; i++) {
await getDetails(startingId + (i * 2500));
await timeout(2000);
}
I had my starting id of a business and at first I just ran the first loop, incrementing by 10,000 until the getDetails function wasn’t yielding any valid businesses or until I had incremented 150,000 ids. Once it stopped yielding valid businesses, I just moved down to the 2500 increment and repeated the process. It was a quick way to hone down to the more recently registered businesses.
Handling Imperva

When first starting to scrape Vermont I was not getting any information. I checked into the response from axios and it returned the following:
<html style="height:100%"><head><META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW"><meta name="format-detection" content="telephone=no"><meta name="viewport" content="initial-scale=1.0"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><script type="text/javascript" src="/_Incapsula_Resource?SWJIYLWA=719d34d31c8e3a6e6fffd425f7e032f3"></script></head><body style="margin:0px;height:100%"><iframe id="main-iframe" src="/_Incapsula_Resource?SWUDNSAI=30&xinfo=4-17623399-0%200NNN%20RT%281593964271022%2033%29%20q%280%20-1%20-1%20-1%29%20r%280%20-1%29%20B12%284%2c315%2c0%29%20U18&incident_id=124000200035804360-89415816041989380&edet=12&cinfo=04000000&rpinfo=0" frameborder=0 width="100%" height="100%" marginheight="0px" marginwidth="0px">Request unsuccessful. Incapsula incident ID: 124000200035804360-89415816041989380</iframe></body></html>
If I see something like this but don’t see anything like this from the browser then I know that it’s something to do with the request. My browser is able to call the website so it’s not blocking by IP address. So I start adding in headers, starting with user-agent. Then cookie. And then I add origin. Then referer. If it still doesn’t work after all of those, then some more serious measures are needed and that’s probably the content for another post.
Cookie and user-agent were both required in order to successfully request the details page. The cookie was plucked from the browser when it requested this specific details page.

axiosResponse = await axios.get(url, {
headers: {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'cookie': 'visid_incap_2224160=8OJuO2TUSXejLRv2UQD1EOXr/14AAAAAQUIPAAAAAACA0qaj4fkQJojUi5vMMFij; _ga=GA1.2.2050730891.1593830374; visid_incap_2276107=aw2KKDFuS8+JO0jjXGTRDENfAF8AAAAAQUIPAAAAAABM4erwbYXZOZoFE8tNEHi2; onlinecollapsibleheaderid=0; incap_ses_124_2276107=1wAZfF/ym3NNHidjhom4AdDNAV8AAAAA7P3/P8xwwaLHIv4regAvEQ==; ASP.NET_SessionId=3hrquyy5i2yxpyvtrpaoeopz; __RequestVerificationToken=hEve0BVRrK2Hv5PjdE0lYqiXUpbG_uyTmaouP1iEbTJMA0Y6ZUma3eRYv4GpEnTCoOH5t7tQqeeU7gw31nvvH0Ir9vva2KA_Jn5OxZE8AyvhiDpNrupKSwKvLlv-mHRgFQv5NSBrtML8RZ1gLXx2SA2'
}
});
An interesting thing about this, however, is that the cookie is short lived. I tried it one day and it worked but the next day I was blocked again. I had to go and get another cookie. If I was to do this daily, I would have a puppeteer session open a headless browser, pluck the cookie from that and then use that in my axios requests.
Getting the details

This next part was some fun CSS selector magic. First thing to note is that there are three main tables that share similar CSS selectors. The only difference is the order. The first has the business details, the second has the principals information, and the third has the registered agent information. It looks like this:
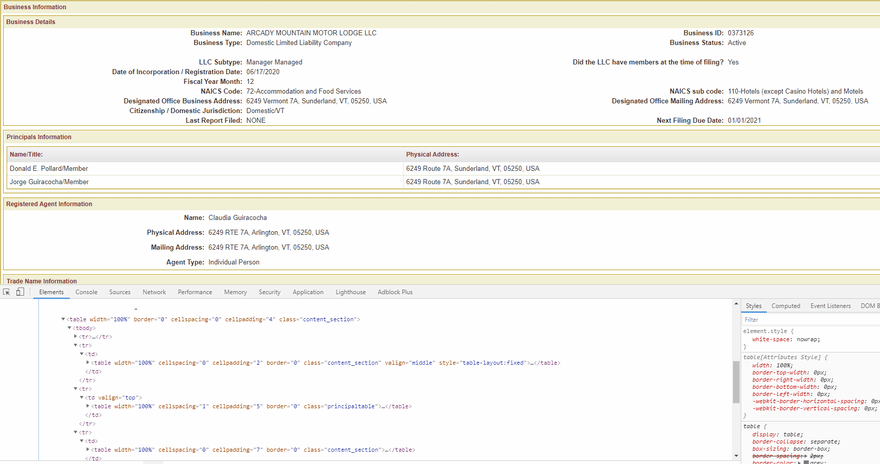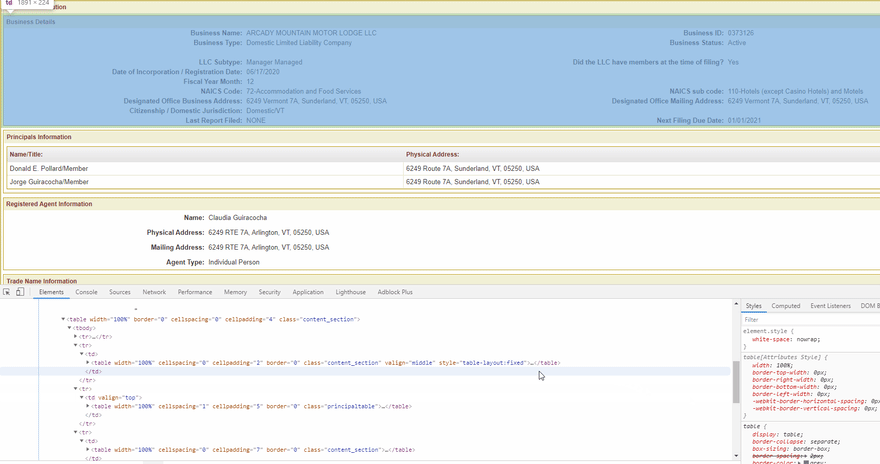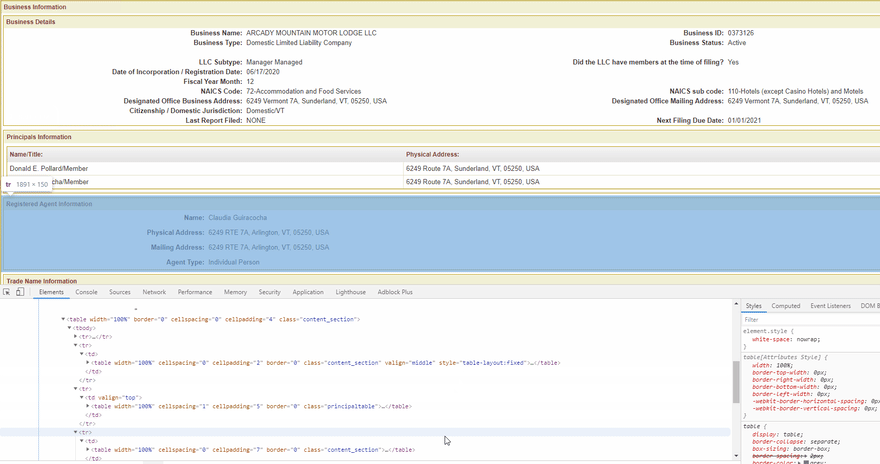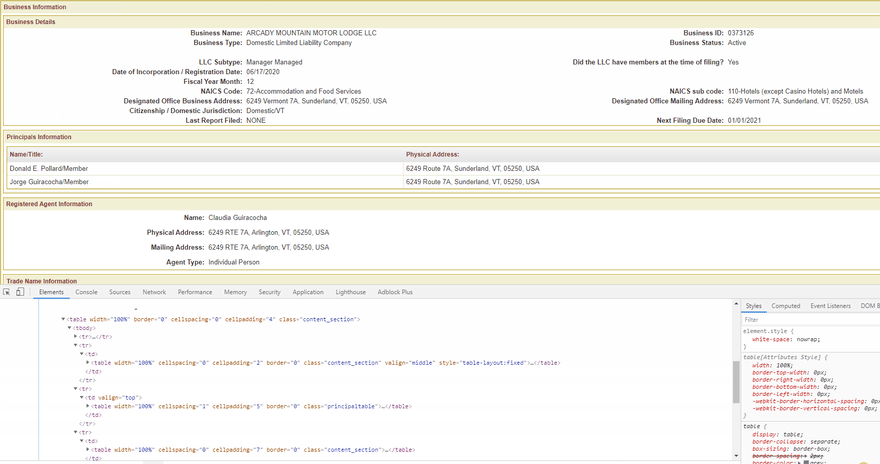
I built a little function that returns the proper selector depending on the table you want. This stops me from having to type in this huge selector each time I want an element from whichever table I am using.
function getTableSelector(tableNumber: number) {
return `body > table > tbody > tr:nth-of-type(2) >td > table > tbody > tr:nth-of-type(3) > td > table> tbody > tr:nth-of-type(${tableNumber})`;
}
The next tricky part is that the table is arranged with rows and cells but each business had different data. I couldn’t trust that filingDate would also be the nth row. I built a switch that checked the label and then used the sibling combinator css selector to get the next value which was the value I’d want.
The whole chunk looks like this:
const businessDetailsRows = $(`${getTableSelector(2)} > td > table > tbody > tr`);
const business: any = {};
for (let i = 0; i < businessDetailsRows.length; i++) {
const row$ = cheerio.load(businessDetailsRows[i]);
const cells = row$('td');
for (let cellsIndex = 0; cellsIndex < cells.length; cellsIndex++) {
const labelCell = row$(`td:nth-of-type(${cellsIndex})`).text();
switch (labelCell) {
case 'Date of Incorporation / Registration Date:':
business.filingDate = row$(`td:nth-of-type(${cellsIndex}) + td`).text();
break;
case 'Business Name:':
business.title = row$(`td:nth-of-type(${cellsIndex}) + td label`).text();
break;
case 'Business Description:':
business.industry = row$(`td:nth-of-type(${cellsIndex}) + td`).text();
break;
case 'NAICS Code:':
business.industry = row$(`td:nth-of-type(${cellsIndex}) + td`).text();
break;
default:
break;
}
}
}
And it worked like a charm. It check all the labels in all the rows. If any of them matched the values I was looking for, it’d pluck the value out. I’m really happy with how this worked.
And that’s really the meat of it! From here you could easily select another table, add more labels to check for, and pluck the data you wanted.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome web data. Learn more at Cobalt Intelligence!
The post Jordan Scrapes Secretary of State: Vermont appeared first on JavaScript Web Scraping Guy.
Posted on July 21, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.